转自本人:https://blog.csdn.net/New2World/article/details/106431424
Influence Maximization
Influence maximization 字面意思,很好理解。比如 Twitter 要推一则广告,肯定希望这则广告能被更多的人看到,于是他们会选择一些用户投放广告,让这些用户转发广告然后推荐给他们的朋友。如何选择这些初始的用户才能让广告的传播更广就是一个影响最大化的问题。也就是说,我现在要选择 (k) 个初始传播点 (S),并且从这些点开始能传播到的最多的点的期望为 (f(S)),那么 influence maximization 就是一个优化问题 (maxlimits_{S of size k}f(S))。而这个优化问题被证明是 NP-Complete 的,因此我们需要一个有效的 approx. 算法。
Propagation Models
Linear Threshold Model
任意节点都有一个阈值 ( heta_vsim U[0,1]),且每个节点都受其邻接点的影响 (b_{v,w})。当且仅当这个影响的累加值大于等于节点阈值时,即 (sumlimits_{w active neighbor of v}b_{v,w} geq heta_v),这个节点被激活。
Independent Cascade Model
每对节点间都有一个概率 (p_{vw}) 表示激活概率,被激活的点按概率激活其未激活的邻接点。这个模型里的顺序不影响结果,比如 (u,v) 都是已激活节点,那么由谁先尝试激活 (w) 是无关的。
Greedy Hill Climbing Algorithm
这个算法理论上能达到 (f(S) geq (1-1/e) imes f(OPT) = 0.63 imes f(OPT))。它的核心思想是逐个添加节点,每次添加一个能激活最多点的节点。这里涉及到一个独立的数学分支 submodularity,这个玩意儿我做 influence maximization 的时候研究过但没深入,Stanford 专门有一门讲这个的课,可以去看看。不过它的基础概念很简单:回报递减,即 (f(Scup{u})-f(S) geq f(Tcup{u})-f(T)),其中 (S subseteq T)。举个例子:你现在很饿,给你一个汉堡你会非常开心;再给你一杯可乐你也会很开心,毕竟可乐汉堡是“标配”,但没有刚得到汉堡时那么开心;现在再给你一包薯条,还是很开心,但此时绝对没有在极度饥饿的情况下得到汉堡和可乐那么开心了,因为你可能已经饱了。
我们现在要证明在 influence maximization 中的 (f(S)) 是 submodular 的,想偷个懒,这里我就不写了,cs224w 有单独一个 hand-out 可供参考。
以 IC 模型为例,我们可以按概率先 sample 多次得到不同的“平行世界” (realizations),然后找能通过 (S) 到达的所有点,即为一个 set cover 问题。根据多个 realization 的平均就能估计 (f(S)) 的期望。
然而,这个贪心算法相当慢,其复杂度为 (O(knRm)),其中的符号分别是:初始选定的节点数、图中总节点数、平行世界个数、图中边的条数。
Sketch-Based Algorithm
回顾贪心算法为什么慢,因为每次在平行世界中计算影响范围时都是 (O(m)) 的复杂度。由于计算影响范围是一个不确定的过程,因此我们尝试用一个 approx. 的方法来估计它,这就成了一个用 approx. 方法来估计 approx. 的过程。
- 首先得到一个平行世界
- 给每个节点分配一个 ([0,1]) 的值
- 将每个节点的值更新为这个节点能到达的所有点中最小的值
直观上讲如果一个节点传播的范围更广的话,它有更大的概率到达那些值很小的节点。因此我们可以通过对点按更新的值进行升序排序,值越小的节点影响越大。这些步骤都是预处理的步骤,也就是说在排好序后使用 greedy 时就只管查询就行。因此我们能在 (O(1)) 复杂度内找到影响大的节点了。
但只使用一个值可能会导致结果偏差很大,因此我们可以维护多个值来保证算法的可靠性。我的理解是这样的,给每个节点分配 rank 值,预处理的时候考虑所有平行世界,对每个节点保留 (c) 个最小的 rank (因为不同平行世界节点间的连通性不一定相同,所以可能出现有些世界能到达更小的 rank 而有些不能)。接下来在贪心的时候就能直接选出最小 rank。将新的节点加入 (S) 后要删除所有由这个节点影响的点,并从其他节点中删除选中这个节点时所用的那个最小 rank 值。
由于这个算法是贪心的近似,因此它的上界其实是贪心的下界。而这个方法的效果能有多好取决于保留的 rank 数 (c)。实验证明,sketch-based 能比贪心更快地得到和贪心差不多的结果。
OutBreak Detection
Outbreak detection 和 influence maximization 问题很类似,都是在网络中选择一些节点来达到某个目的。以社交网络为例,influence maximization 是为了通过选中的节点使传播更广,而 outbreak detection 是为了通过这些选中的点来及时全面地侦测网络上可能会爆发的话题。这里要求侦测满足及时和全面两个要求,因此选点就得慎重了。我们先规定节点 (u) 得知事件 (i) 的时间为 (T(u,i)),以及通过我们选择的点侦测到事件 (i) 的收益 (f(S) = sum_iP(i)f_i(S)),(P(i)) 为事件 (i) 发生的概率。当然侦测所有点是最直接的方法,然而侦测一个点都会产生一定的代价。因此 outbreak detection 也是一个带约束的优化问题。
目前还没解释的就是这个 reward (f(S)) 了。它的定义至关重要,直接关系到及时性和全面性。它需要满足
- 使事件被侦测到的时间要尽量早
- 要侦测尽量多的事件
- 一旦 outbreak 尽量减小受影响的范围
围绕以上几个条件展开讨论,首先定义几个符号,(pi_i(t)) 表示在时刻 (t) 侦测到事件 (i) 的惩罚。
- time to detection (DT): (pi_i(t)=t)
- detection likelihood (DL): (pi_i(t)=0, pi_i(infty)=1)
- population affected (PA): (pi_i(t)={# of infected nodes in outbreak i by time t })
那么我们用 penalty reduction 的思路来定义 reward 即 (f_i(S)=pi_i(infty)-pi_i(T(S,i)))。这里又出现了 submodular 的身影。把网络设想为一个黑暗的房间,侦测点是一个光源,那么放的第一个光源对这个黑暗房间的意义应该是最大的,因为你从伸手不见五指到能看清房间的一部分了。放第二个的时候你能看到的地方更多了,但它的效果明显没有第一个光源那么有意义。而当我们放入更多光源到一定程度后,整个房间都亮了,再放入光源已经完全没有必要了。抽象一下,可由符号表述为
如下为证明,不感兴趣的朋友可以跳过。要证明这个需要分 3 种情况讨论点 (x) 侦测到事件 (i) 的时间。
- (T(B,i)leq T(A,i) < T(x,i)),即 (x) 比 A 和 B 更晚侦测到。所以 (f_i(Acup{x})=f_i(A)), (f_i(Bcup{x})=f_i(B))
- (T(B,i)leq T(x,i) < T(A,i)),即 (x) 比 B 早,比 A 晚。如此便有
- (T(x,i) < T(B,i)leq T(A,i)),即 (x) 比 A 和 B 都更早侦测到。所以
由于 (f_i(A)leq f_i(B)),所以 (f_i(Acup{x})-f_i(A)geqf_i(Bcup{x})-f_i(B))
综上,(f_i(cdot)) 是 submodular,因此 (f(cdot)=sum_iP(i)f_i(cdot)) 也是 submodular。那么根据 influence maximization 的经验,submodular 可以用贪心的方法做到 ((1-1/e)cdot OPT)。然而这只对 unit cost 有效,当每个侦测点的代价不同时,贪心就不适用了。
CELF: Cost-Effective Lazy Forward-selection
Benefit-Cost Greedy
为什么忽略 cost 会出问题?假设,我们的预算为 (B),而现在有两种感应器各无数个
- s1: reward (r), cost (B)
- s2: reward (r-epsilon), cost (1)
忽略 cost 的情况下我们会首选 s1,这样一来预算消耗完了,我们得到了 (r) 的收益。然而如果我们用 s2,我们可以装 (B) 个上去,得到的收益为 (B(r-epsilon))。
Unit-Cost Greedy
那么如果我们考虑性价比呢?回答还是否定的。考虑一个很极端的情况,预算为 (B),但我们只有两个感应器
- s1: reward (2epsilon), cost (epsilon)
- s2: reward (B), cost (B)
光看性价比肯定选 s1,然而这样一来我们预算就不够装 s2 了,最终的 reward 就只有 (2epsilon)。
那么,怎么解决这个问题?很简单,两个方法一起用,取最优呗!这就是 CELF 的精髓,即
- S': use benefit-cost greedy
- S'': use unit-cost greedy
然后通过取最大得到最终结果 (S=argmax(f(S'),f(S'')))。那这个方法能做到什么程度呢?(frac12(1-1/e)cdot OPT)。惊人吧,两个 arbitrary bad 的方法能做到这么好的结果,我感觉类似 boosting 的本质:多个 suboptimal 可以提升为更好的结果。
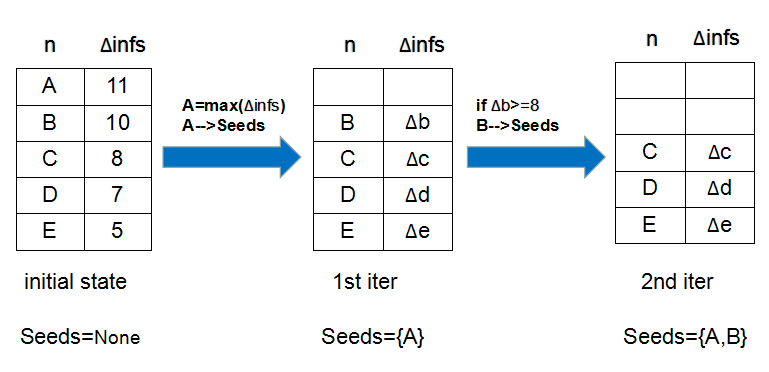
Lazy Evaluation
Greedy 效果挺好,但速度太慢。Influence maximization 中我们希望网络中的传播范围更大因此可以通过 rank 值来加速,但这里不行啊。我们需要充分利用 submodular 的性质。假设在一次迭代中,我们选择了点 (x),那么这次我们通过 (x) 得到的收益一定是最多的。而且对于其它所有点,这次的回报一定比以后得到的更多。于是我们将所有点的收益排成递减序列,然后每次取首位的最大值就好。下一次迭代时按上次的顺序更新收益值,如果某个点的新收益值大于等于上次收益比这个点小且最接近的值,那么就能确定这个点就是这次的最大值;不然就得将更新后的值插入到正确位置以保证序列为降序。这里借用一个图[1]来说明
Data Dependent Bound
上面提到的贪心算法的结果的下界是独立于数据的理论分析,相对来说可能很宽松。如果根据数据来估计能否得到一个更紧凑的界限。我们在每一次迭代时都会计算收益,如果将收益降序排列,我们能得到基于数据的估计 (f(OPT)leq f(S)+sumlimits_{i=1}^kdelta(i)),其中 (delta) 是收益,(k) 是我们要选取的点的个数。至于为什么,我们来看看证明,假设 $S_{OPT}={t_1, t_2, ..., t_k}
后面还有一些 case study 来证明上面的理论是正确的。因为大多是图,这里就不贴了,感兴趣的话可以去看 slides。