上午11点,下午4-5点,晚上8-9点,反应得比较多
而且我们公司的人测试很快,复现不了客户的问题。
再者,是某一个区域的人反映慢,并不是大面积范围的人都反映慢。开发觉得是区域网络问题,我则觉得是程序代码问题(其实两边都有,代码引用被墙的js+区域网络管的严刚好把这地址墙了)。因为产品经理有说过,是最近在几个时间段,用这个业务的人数多了,以前从来没有过(我当时怀疑程序线程数)
我觉得是程序代码问题,是因为看到有这样的报错日志,关键字:simpleasyncuncaughtexception,以为线程数开的不够来不及处理通知任务(后面说到这个原因也是不对的,虽然是程序,但是不是这个原因)
然而,我领导始终把问题原因锁在运维这边,不仅@我跟一个测试储备,用一个叫Testin云测的东西【https://www.testin.cn/account/login.htm】,去最大限度模拟客户手机环境(包括硬件)去测试这个业务(跟客户的测试机型保持一致),当时我是这样的:= = ! (估计研发部的人都看到我脸黑了),因为我以为被抓去测业务流程。在公司里,作为运维的我是最不懂业务的,我也是看中基本不用懂业务所以才当的运维,因为不想记太多难记的东西,哈哈~~所以对于这个云测,最后还是给了那个储备去测试,我算是开开 ,原来进去后,有很多款测试模拟手机
,原来进去后,有很多款测试模拟手机 ,好像商品一样琳琅满目,界面挺好看的~~放个图给大家欣赏下:
,好像商品一样琳琅满目,界面挺好看的~~放个图给大家欣赏下:
云测也复现不了客户问题,我们测试正常(FQ+不FQ的网络环境都正常)
过了几天,领导还是说那个区域的客户反馈很慢,叫再查下资源和带宽,无果。。。
又过了几天,领导外出了,想误导我去分析nginx日志:
这么久了,nginx日志我没少分析过,往这个方向排查,很大可能是无用功!
加一,xxx前后端nginx日志,你统计下超时访问的情况,还有有没有访问数据过大的情况
如果有,收集一下访问的地址,都是哪些地址超时访问 ---- 幸好我拒绝了,做了等于白做
我说nginx日志分析做不到超时访问情况统计的,顶多能统计每个接口响应时间
有类似timeout的记录不,nginx的超时时间是多少 --- 我就回了个600秒
最后发了这个链接我【https://blog.csdn.net/xu710263124/article/details/118180821】
我说我们日志没有这种报错(nginx的error log里面),那天,终于死心了。。。
后来,在6月2日的时候,问题最终解决!
当时一早叫我坐在他旁边(加一,我们一起来查 = =),看着他排查(老实说,我既不喜欢他在我电脑操作,或者要我看着他操作,浪费俺的宝贵时间,据说其他开发也吐槽,说他一过来正事做不了),真的有种莫挨老子的感觉。。。
整个流程,他跟前端开发交流多,其实没啥我的事,可能看中我的观察力(我多次回我工位,他还是抓我回去看着他的骚操作 ),因为要改数据库的字段来模拟客户使用场景,偷客户的账号密码去登录(这个“偷”字,我觉得用的特别精辟,据说是用我们测试的账号密码123456加密过的密文,然后将这个已知123456的密文,来替换客户密码加密过的密文,这就能用客户账号登录了,密码就是123456嘛~)
),因为要改数据库的字段来模拟客户使用场景,偷客户的账号密码去登录(这个“偷”字,我觉得用的特别精辟,据说是用我们测试的账号密码123456加密过的密文,然后将这个已知123456的密文,来替换客户密码加密过的密文,这就能用客户账号登录了,密码就是123456嘛~)
最后终于还我清白了,沉冤得雪了,感人肺腑 ~~不然跳进黄河都洗不清啦
xxx访问慢的问题,已得到解决。以下是问题原因及解决方法,请周知! 原因:由于程序中采用了域名cdn.jsdelivr.net下的cdn文件/代码,当前该域名被墙了,因此相关引用都会无法访问。 解决方法: 1、无用的cdn引用文件/代码删除 2、将该cdn文件下载到本地,修改代码引用本地文件
插一句题外话,这天还有另一个项目:公司文档编辑docsify,也存在FQ能看内容,不FQ白屏的问题:
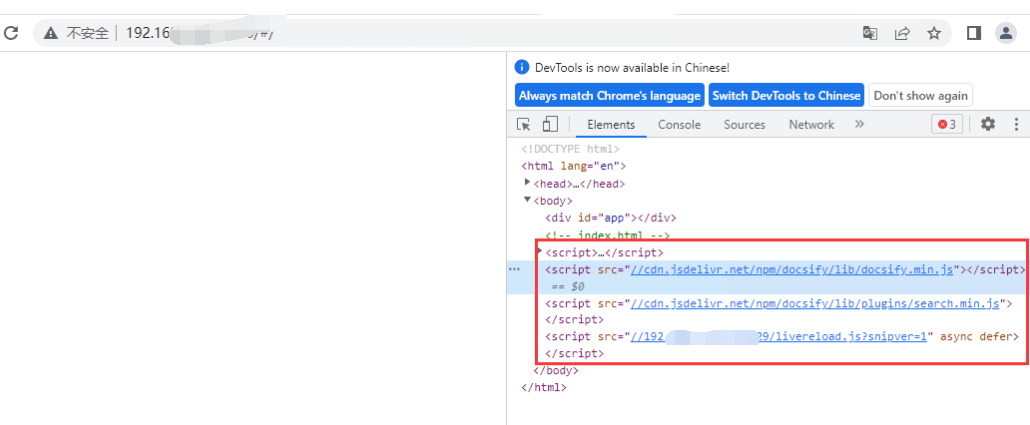
我就说不FQ看不了是因为页面调用的js访问不了。
两个项目都了刚好也是用到npm环境,当时大家都醒悟了,原来这两个问题的解决方法是相通的,也就是说,npm引用到的js地址(cdn.jsdelivr.net)最近可能国家管的严,有些地区把这个地址墙了,有些没有,所以出现某区域客户访问慢的情况,有些区域的客户还是用的好好的,在乎你所在地域~~~
总结:
一路走的弯路历程:kafka ——》 系统资源、带宽 ——》 云测 ——》 nginx日志
总结下来就是,这种迟迟找不到原因的,一定要有开发介入处理,而不是直接把问题扔给运维(我领导也算是半个开发,所以有他帮忙就很快解决了)