阿里云oss空间清理之奇思妙想
用过阿里云oss的同学,应该都知道上传后的文件名,命名是一串随机字符串:

而且这串bucket,据说开发还是做了优化,才存到一个个叫uuid的目录。不然,最最原始的时候,它们没有自己的“归属”(即上面的子目录),就是一坨字符串杂乱无章地存着。
阿里的oss控制台、还有oss管理工具,都没有做按文件更新时间做排序搜索,导致清理极其困难。
今早手动清理了几个目录发现累死了,因为,清理之前是要先备份的。我昨天拉了850天前的数据,大概几万个文件到公司内网的服务器上,清理之前,我要先对下该bucket目录里面的文件更新时间是否是2018、2019年(开发说保留最近两年数据即可),要先确认更新时间是否对上了,本地备份的对上了才能删。所以我今天在内网的机器不停地运行这几条命令,实属悲催:
[root@ljy bak-某bucket-img]# mkdir 某目录uuid ##因为该目录下文件前缀就是某目录uuid,所以直接移动到 [root@ljy bak-某bucket-img]# mv 某目录uuid* -t 某目录uuid/ mv: 无法将目录"某目录uuid" 移动至自身的子目录"某目录uuid" 下 ##年份:2018或2019 [root@ljy bak-某bucket-img]# mv 某目录uuid /data_bak/bak-某bucket-img]/年份/
说明:
(1)当前目录:bak-某bucket-img : 存有几万个文件, 要 “ls | more” 找到文件前缀,

上面的mkdir uuid 的uuid就是指这人眼甄选出的文件前缀!!!
然后我就把这坨有该uuid的一类文件选出来,放到目录uuid里,
(2)年份确认是从oss控制台搜索这个uuid,点进去看更新时间的 = =
一天下来,搞到眼都花,没错,就是看到重影,我以为视力深了好几百度。
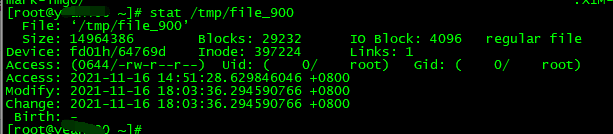
话说做这玩意的时候,我弄了个脚本,未写完,但应该可以减少点人工,利用stat命令去找modify的更新时间,注意不是ctime和atime!
## 1、找到900天前数据 find 挂载到服务器的bucket -mtime +900 -type f > /tmp/file_900 keyword1="2018" keyword2="2019" ## 2、判断修改文件更新时间是否有关键字: 2018,2019 cat /tmp/file_900 | while read line do f1=`stat $line |grep Modify |awk '{print $2}'` result1=$(echo $f1 | grep "${keyword1}") result2=$(echo $f1 | grep "${keyword2}") #stat 2c9220dd6884168843aaefa0000/2c9220dd6884168843aaefa0000_856_1.jpg |grep Modify |awk '{print $2}' # 有关键字(2018年) if [ "$result1" != "" ]; then #截取前缀uuid目录名字,然后准备拷贝文件进去,这里开始没写完。。 ml=`echo $line | awk -F'/' '{print $4}'` [ ! -d ${bakdir}/${keyword1} ] && mkdir -p ${bakdir}/${keyword1} # 有关键字(2019年) elif [ "$result2" != "" ]; ml2=`echo $line | awk -F'/' '{print $4}'` [ ! -d ${bakdir}/${keyword2} ] && mkdir -p ${bakdir}/${keyword2} else continue fi …… done
当我发现find这个查找900天前的数据,跑了3个小时才跑完,彻底绝望,因为清理的bucket是2018年底建的,筛选900天前的数据实际上只是很小一部分,这意味着找出来让人头痛,备份再删除更不用说。。。900天前已经放着一坨没规律的海量数据,何况慢慢缩小范围直到找完2020前数据?!
最后下班的时候,告诉领导难处,他说数据库有记录这些考试id(就是上面的uuid),可以找到2019年前的那批uuid,到时直接拉下备份删除,会减少我这个查找工作 = =。而且并不是所有bucket都需要拉下来备份,有些测试能直接干掉,听完感动流涕,
希望明天一片光明。。。。