一、grep
1、简介
linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
2、语法格式
grep [OPTION]...PATTERN [FILE] ...
3、主要参数
[options]主要参数:
-c:只输出匹配了多少次。
-i:不区分大小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
-d:跳过对子目录的搜索
-r: 对子目录也进行查找
4、grep正则表达式元字符集(基本集):
\:忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行,如:'^grep'匹配所有以grep开头的行。
$: 匹配正则表达式的结束行,如'grep$'匹配所有以grep结尾的行。
\<:从匹配正则表达式的行开始。如'\<grep'匹配包含以grep结尾的单词的行。
\>:到匹配正则表达式的行结束。如'grep\>'匹配包含以grep结尾的单词的行。
[]:匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。需要特別留意的是,在 [] 当中『仅代表一个待搜寻的字元』
[ n1-n2 ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
[^xyz] 匹配除方括号中字符外的所有字符。
. :所有的单个字符。
* :有字符,长度可以为0。
5、用于egrep和 grep -E的元字符(扩展集)
+ 匹配一个或多个先前的字符。如:'[a-z]+able',匹配一个或多个小写字母后跟able的串,如loveable,enable,disable等。
? 匹配零个或多个先前的字符。如:'gr?p'匹配gr后跟一个或没有字符,然后是p的行。
a|b|c 匹配a或b或c。如:grep|sed匹配grep或sed
() 分组符号,如:love(able|rs)ov+匹配loveable或lovers,匹配一个或多个ov。
6、例句
# 显示过滤注释( # ; 开头) 和空行后的配置信息 $ grep -Ev "^$|^[#;]" server.conf #显示匹配出以开头为空格的行 cat -n /root/ryan/shell/fist.sh |egrep -in "[' ']+" #显示文件名是字母的文件 ls | egrep -in '[a-z]+'
二、sed
1、简介
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
每次仅读取一行内容;
根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
2、语法格式
sed的命令格式:sed [options] [-e] 'script' file(s);
sed的脚本格式:sed [options] -f scriptfile file(s);
########################################
3、主要参数
[options]主要参数
-e :直接在命令行模式上进行sed动作编辑,此为默认选项;
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
-i :直接修改文件内容;
-n :只打印模式匹配的行;
‘script’主要参数
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
4、例句
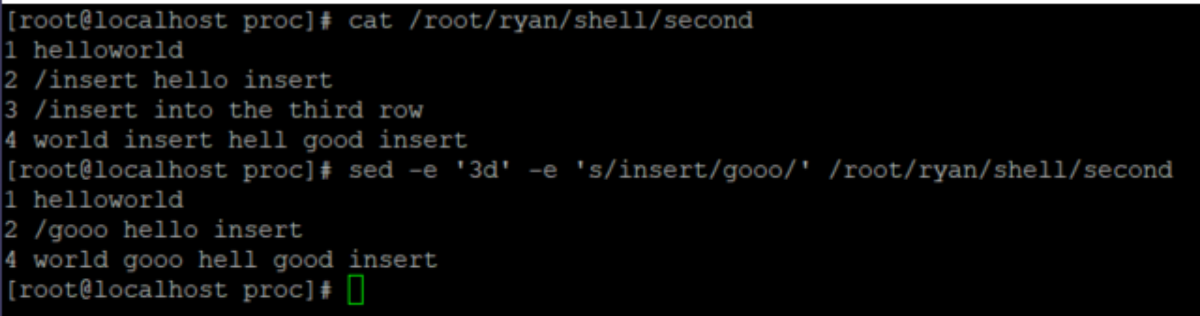
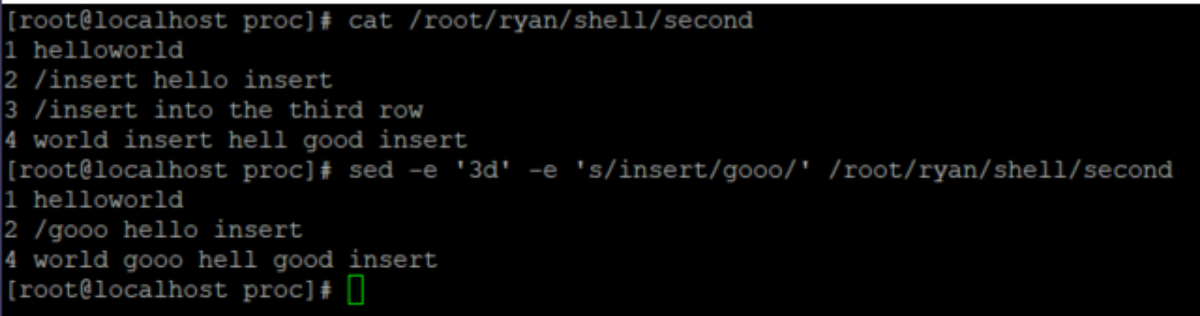
(1)、插入动作 #在testfile文件的第四行后添加一行 # sed -i ‘4a\newLine’ testfile #在第二行上插入数据 sed -i ‘2i\newline’ testfile (2)、删除动作 #删除第四行 #sed -i ‘4d’ testfile 要删除第 3 到最后一行 #sed -i ‘3,$d’ testfile #删除空白行: sed '/^$/d' file # 删除文件中所有开头是test的行: sed '/^test/'d file (3)、替换动作 #替换第二行 sed -i ‘2c\change’ testfile #替换每一行第一个匹配的字符串 sed -i ‘s/hello/good/’ testfile #替换每一行所有匹配的字符串 sed -i ‘s/hello/good/g’ testfile #-n选项和p命令一起使用表示只打印那些发生替换的行: sed -n 's/test/TEST/p' file 定界符 以上命令中字符 / 在sed中作为定界符使用,也可以使用任意的定界符 sed 's:test:TEXT:g' sed 's|test|TEXT|g' (4)、查看动作 #只查看文件的第3行到第9行 # sed -n '3,9p' /var/log/yum.log # 所有在模板test和check所确定的范围内的行都被打印: sed -n '/test/,/check/p' file (5)组合多个表达式 sed '表达式' | sed '表达式' 等价于:sed '表达式; 表达式' 引用 sed表达式可以使用单引号来引用,但是如果表达式内部包含变量字符串,就需要使用双引号。 test=hello echo hello WORLD | sed "s/$test/HELLO" HELLO WORLD 选定行的范围:,(逗号) 所有在模板test和check所确定的范围内的行都被打印: sed -n '/test/,/check/p'
file打印从第5行开始到第一个包含以test开始的行之间的所有行: sed -n '5,/^test/p'
file对于模板test和west之间的行,每行的末尾用字符串aaa bbb替换: sed '/test/,/west/s/$/aaa bbb/' file (6)、多点编辑:e命令 -e选项允许在同一行里执行多条命令: sed -e '1,5d' -e 's/test/check/' file上面sed表达式的第一条命令删除1至5行,第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。 和 -e 等价的命令是 --expression: sed --expression='s/test/check/' --expression='/love/d' (7)、file从文件读入:r命令 file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面: sed '/test/r file' filename (8)、写入文件:w命令 在example中所有包含test的行都被写入file里: sed -n '/test/w file' example (9)、追加(行下):a\命令 将 this is a test line 追加到 以test 开头的行后面: sed '/^test/a\this is a test line' file在 test.conf 文件第2行之后插入 this is a test line: sed -i '2a\this is a test line' test.conf (10)、插入(行上):i\命令 将 this is a test line 追加到以test开头的行前面: sed '/^test/i\this is a test line' file在test.conf文件第5行之前插入this is a test line: sed -i '5i\this is a test line' test.conf (11)、下一个:n命令 如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续: sed '/test/{ n; s/aa/bb/; }' file (12)、变形:y命令 把1~10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令: sed '1,10y/abcde/ABCDE/' file (13)、 退出:q命令 打印完第10行后,退出sed sed '10q' file 保持和获取:h命令和G命令 在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。 sed -e '/test/h' -e '$G' file 在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。 (14)、保持和互换:h命令和x命令 互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换: sed -e '/test/h' -e '/check/x' file (15)脚本scriptfile sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。 sed [options] -f scriptfile file(s)打印奇数行或偶数行 方法1: sed -n 'p;n' test.txt #奇数行 sed -n 'n;p' test.txt #偶数行 方法2: sed -n '1~2p' test.txt #奇数行 sed -n '2~2p' test.txt #偶数行 打印匹配字符串的下一行 grep -A 1 SCC URFILE sed -n '/SCC/{n;p}' URFILE awk '/SCC/{getline; print}' URFILE
#############################################################
[options]参数详解:
-e :直接在命令行模式上进行sed动作编辑,此为默认选项;
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
-i :直接修改文件内容;
-n :只打印模式匹配的行;
-r :支持扩展表达式;
-h或--help:显示帮助;
-V或--version:显示版本信息。
‘script’参数详解
a\ 在当前行下面插入文本;
i\ 在当前行上面插入文本;
c\ 把选定的行改为新的文本;
d 删除,删除选择的行;
D 删除模板块的第一行;
s 替换指定字符;
h 拷贝模板块的内容到内存中的缓冲区;
H 追加模板块的内容到内存中的缓冲区;
g 获得内存缓冲区的内容,并替代当前模板块中的文本;
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面;
l 列表不能打印字符的清单;
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令;
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码;
p 打印模板块的行。 P(大写) 打印模板块的第一行;
q 退出Sed;
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾;
r file 从file中读行;
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
w file 写并追加模板块到file末尾;
W file 写并追加模板块的第一行到file末尾;
! 表示后面的命令对所有没有被选定的行发生作用;
= 打印当前行号;
# 把注释扩展到下一个换行符以前;
################################################################
三、awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
语法格式 :
awk '{pattern + action}' {filenames}
常用参数:
-F 指定输入时用到的字段分隔符
-v 自定义变量
-f 从脚本中读取awk命令
-m 对val值设置内在限制
[root@localhost shell]# cat log.txt
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo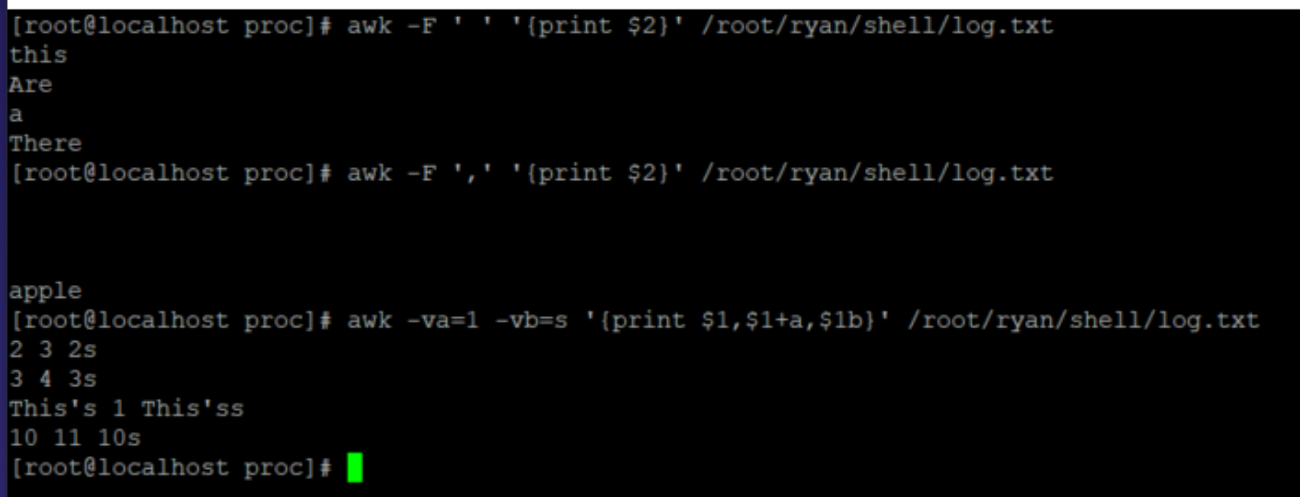
awk脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
BEGIN{ 这里面放的是执行前的语句 }
END {这里面放的是处理完所有的行后要执行的语句 }
{这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txt Marry 2143 78 84 77 Jack 2321 66 78 45 Tom 2122 48 77 71 Mike 2537 87 97 95 Bob 2415 40 57 62 我们的 awk 脚本如下: $ cat cal.awk #!/bin/awk -f #运行前 BEGIN { math = 0 english = 0 computer = 0 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n" printf "---------------------------------------------\n" } #运行中 { math+=$3 english+=$4 computer+=$5 printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5 } #运行后 END { printf "---------------------------------------------\n" printf " TOTAL:%10d %8d %8d \n", math, english, computer printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR } #我们来看一下执行结果: $ awk -f cal.awk score.txt NAME NO. MATH ENGLISH COMPUTER TOTAL --------------------------------------------- Marry 2143 78 84 77 239 Jack 2321 66 78 45 189 Tom 2122 48 77 71 196 Mike 2537 87 97 95 279 Bob 2415 40 57 62 159 --------------------------------------------- TOTAL: 319 393 350 AVERAGE: 63.80 78.60 70.00
find
find命令可以根据给定的路径和表达式查找的文件或目录。find参数选项很多,并且支持正则,功能强大。和管道结合使用可以实现复杂的功能,是系统管理者和普通用户必须掌握的命令。
语法格式
:
find path -option [ -print ] [ -exec -ok command ] {} \;
print
:表示将结果输出到标准输出。
exec
:对匹配的文件执行该参数所给出的shell命令。
形式为command {} \;,
注意{}与\;之间有空格
ok
:与exec作用相同,
区别在于,在执行命令之前,都会给出提示,让用户确认是否执行
常用参数
:
-name 按名称查找 |
-iname 忽略大小写 |
-size 按大小查找 |
-user 按属性查找 |
-type 按类型查找 |
-perm :按执行权限来查找
-atime n : 在过去n天内被读取过的文件
-ctime n : 在过去n天内被修改过的文件
-empty : 空的文件-gid n or -group name : gid 是 n 或是 group 名称是 name
-amin n : 在过去 n 分钟内被读取过
-cmin n : 在过去 n 分钟内被修改过
-anewer file : 比文件 file 更晚被读取过的文件
-cnewer file :比文件 file 更新的文件
-ipath p, -path p : 路径名称符合 p 的文件,ipath 会忽略大小写
在/etc及其子目录中,查找host开头的文件
$ find /etc -name 'host*' -print
在当前目录及子目录中,查找属主具有读写执行,其他具有读执行权限的文件
$ find . -perm 755 -print
查找用户有写权限或者组用户有写权限的文件或目录
find ./ -perm /220
find ./ -perm /u+w,g+w
find ./ -perm /u=w,g=w
find支持变量,查找$HOME变量目录下,24小时内修改过的文件。命令如下:
find $HOME -mtime 0
查找 /var/log 目录中更改时间在 7 日以前的普通文件,并在删除之前询问它们:
# find /var/log -type f -mtime +7 -ok rm {} \;
使用-name参数查看/etc目录下面所有的.conf结尾的配置文件:
[root@linuxcool ~]# find /etc -name "*.conf
使用-size参数查看/etc目录下面大于1M的文件:
[root@linuxcool ~]# find /etc -size +1M
查找当前用户主目录下的所有文件:
[root@linuxcool ~]# find $HOME -print
列出当前目录及子目录下所有文件和文件夹:
[root@linuxcool ~]# find .
在/home目录下查找以.txt结尾的文件名:
[root@linuxcool ~]# find /home -name "*.txt"
在/var/log目录下忽略大小写查找以.log结尾的文件名:
[root@linuxcool ~]# find /var/log -iname "*.log"
搜索超过七天内被访问过的所有文件:
[root@linuxcool ~]# find . -type f -atime +7
搜索访问时间超过10分钟的所有文件:
[root@linuxcool ~]# find . -type f -amin +10
找出/home下不是以.txt结尾的文件:
[root@linuxcool ~]# find /home ! -name "*.txt"
ps
进程是运行的程序在系统中的存在形式,通过查看进程的状态信息,我们可以了解进程占用的系统资源情况,对系
统的运行状态进行分析、调整,从而让系统保持在一个平稳的状态下运行。
Linux中查看进程信息的基本命令有ps、top,其中ps(Process Status)查看的是进程信息的一个快照,显示的我们
执行ps这个命令时进程的信息,top显示的是进程的动态信息,使用这个命令会看到进程信息的动态变化。
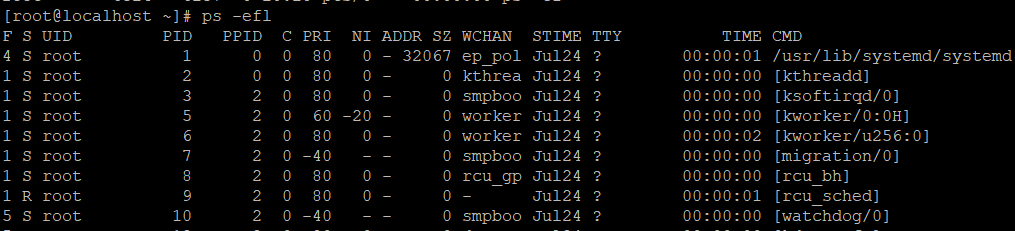
F 代表这个程序的旗标 (flag), 4 代表使用者为 superuser;
S 代表这个程序的状态 (STAT);
( 常见的进程的 STAT 如下:
R 运行 Runnable (on run queue) 正在运行或在运行队列中等待,
S 睡眠 Sleeping 休眠中, 受阻, 在等待某个条件的形成或接受到信号,
I 空闲 Idle ,
Z 僵死 Zombie(a defunct process) 进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放,
D 不可中断 Uninterruptible sleep (ususally IO) 收到信号不唤醒和不可运行, 进程必须等待直到有中断发生,
T 终止 Terminate 进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行,
P 等待交换页 ,
W 无驻留页 has no resident pages 没有足够的记忆体分页可分配,
X 死掉的进程 ,)
进程
状态后缀表示:
<:优先级高的进程
N:优先级低的进程
L:有些页被锁进内存
s:进程的领导者(在它之下有子进程)
l:ismulti-threaded (using CLONE_THREAD, like NPTL pthreads do)
+:位于后台的进程组
PROCESS STATE CODES Here are the different values that the s, stat and state output specifiers (header "STAT" or "S") will display to describe the state of a process: D uninterruptible sleep (usually IO) R running or runnable (on run queue) S interruptible sleep (waiting for an event to complete) T stopped by job control signal t stopped by debugger during the tracing W paging (not valid since the 2.6.xx kernel) X dead (should never be seen) Z defunct ("zombie") process, terminated but not reaped by its parent For BSD formats and when the stat keyword is used, additional characters may be displayed: < high-priority (not nice to other users) N low-priority (nice to other users) L has pages locked into memory (for real-time and custom IO) s is a session leader l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do) + is in the foreground process group
USER :进程的所属用户,
PID :进程的进程ID号,
%CPU :进程占用的 CPU资源 百分比,
%MEM :进程占用的 物理内存 百分比,
VSZ :进程使用掉的虚拟内存量 (Kbytes) ,
RSS :进程占用的固定的内存量 (Kbytes) ,
TTY :与进程相关联的终端(tty),?代表无关,tty1-tty6是本机上面的登入者程序,pts/0表示为由网络连接进主机的程序。
STAT :进程的状态,具体见2.1列出来的部分 ,
START :进程开始创建的时间 ,
TIME :进程使用的总cpu时间,
COMMAND : 进程对应的实际程序。
perf
perf是Linux下的一款性能分析工具,能够进行函数级与指令级的热点查找。
Perf List
利用perf剖析程序性能时,需要指定当前测试的性能时间。性能事件是指在处理器或操作系统中发生的,可能影响到
程序性能的硬件事件或软件事件
-----------------------------------------------------------------------------------------------------
Perf top
实时显示系统/进程的性能统计信息
常用参数
-e:指定性能事件
-a:显示在所有CPU上的性能统计信息
-C:显示在指定CPU上的性能统计信息
-p:指定进程PID
-t:指定线程TID
-K:隐藏内核统计信息
-U:隐藏用户空间的统计信息
-s:指定待解析的符号信息
‘‐G’ or‘‐‐call‐graph’ <output_type,min_percent,call_order>
graph: 使用调用树,将每条调用路径进一步折叠。这种显示方式更加直观。
每条调用路径的采样率为绝对值。也就是该条路径占整个采样域的比率。
fractal
默认选项。类似与 graph,但是每条路径前的采样率为相对值。
flat
不折叠各条调用
选项 call_order 用以设定调用图谱的显示顺序,该选项有 2个取值,分别是
callee 与caller。
将该选项设为callee 时,perf按照被调用的顺序显示调用图谱,上层函数被下层函数所调用。
该选项被设为caller 时,按照调用顺序显示调用图谱,即上层函数调用了下层函数路径,也不显示每条调用路径的采样率
注: Perf top需要root权限
-----------------------------------------------------------------------------------------------------
Perf stat
分析系统/进程的整体性能概况
task‐clock事件表示目标任务真正占用处理器的时间,单位是毫秒。也称任务执行时间
context-switches是系统发生上下文切换的次数
CPU-migrations是任务从一个处理器迁往另外一个处理器的次数
page-faults是内核发生缺页的次数
cycles是程序消耗的处理器周期数
instructions是指命令执行期间产生的处理器指令数
branches是指程序在执行期间遇到的分支指令数。
branch‐misses是预测错误的分支指令数。
XXX seconds time elapsed系程序持续时间
任务执行时间/任务持续时间大于1,那可以肯定是多核引起的
参数设置:
-e:选择性能事件
-i:禁止子任务继承父任务的性能计数器。
-r:重复执行 n 次目标程序,并给出性能指标在n 次执行中的变化范围。
-n:仅输出目标程序的执行时间,而不开启任何性能计数器。
-a:指定全部cpu
-C:指定某个cpu
-A:将给出每个处理器上相应的信息。
-p:指定待分析的进程id
-t:指定待分析的线程id
-----------------------------------------------------------------------------------------------------
Perf record
记录一段时间内系统/进程的性能时间
参数:
-e:选择性能事件
-p:待分析进程的id
-t:待分析线程的id
-a:分析整个系统的性能
-C:只采集指定CPU数据
-c:事件的采样周期
-o:指定输出文件,默认为perf.data
-A:以append的方式写输出文件
-f:以OverWrite的方式写输出文件
-g:记录函数间的调用关系
-----------------------------------------------------------------------------------------------------
Perf Report
读取perf record生成的数据文件,并显示分析数据
参数
-i:输入的数据文件
-v:显示每个符号的地址
-d <dos>:只显示指定dos的符号
-C:只显示指定comm的信息(Comm. 触发事件的进程名)
-S:只考虑指定符号
-U:只显示已解析的符号
-g[type,min,order]:显示调用关系,具体等同于perf top命令中的-g
-c:只显示指定cpu采样信息
-M:以指定汇编指令风格显示
–source:以汇编和source的形式进行显示
-p<regex>:用指定正则表达式过滤调用函数
uptime
uptime是一个简单获取系统总共运行多长时间,以及最近1分钟、5分钟、15分钟的平均负载。
uptime通过/proc/uptime和/proc/loadavg获取相关信息。
up前是当前系统时间,up后是系统运行时长。
load average后是1分钟、5分钟、15分钟平均负载。
11:15:41 up 82 days, 20:34, 8 users, load average: 0.28, 0.40, 0.43