一、 Re
1. 常用的正则表达式符号
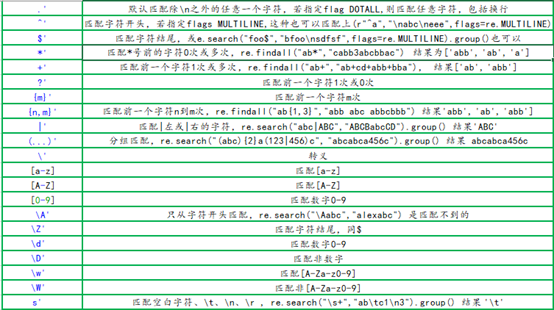

2. 常用的匹配方法
1) re.match(pattern, string, flags=0)
说明:在string的开始处匹配模式
>>> import re
>>> a = re.match('in',"inet addr:10.161.146.134") #从头开始匹配in字符
>>> a.group()
'in'
>>> a = re.match('addr',"inet addr:10.161.146.134")
#开头匹配不到,所以返回none
>>> print(a)
None
2) re.search(pattern, string, flags=0)
说明:在string中寻找模式
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134") #在字符串中寻找
>>> a.group()
'addr'
3) re.findall(pattern, string, flags=0)
说明:把匹配到的字符以列表的形式返回
>>> import re
>>> re.findall('[0-9]{1,3}',"inet addri:10.161.146.134")
['10', '161', '146', '134'] #符合条件的以列表的形式返回
4) re.split(pattern, string, maxsplit=0, flags=0)
说明:匹配到的字符被当做列表分割符
>>> import re
>>> re.split('.',"inet addri:10.161.146.134")
['inet addri:10', '161', '146', '134']
5) re.sub(pattern, repl, string, count=0, flags=0)
说明:匹配字符并替换
>>> import re
>>> re.sub('.','-',"inet addri:10.161.146.134")
'inet addri:10-161-146-134' #默认全部替换
>>> re.sub('.','-',"inet addri:10.161.146.134",count=2)
'inet addri:10-161-146.134' #用count控制替换次数
6) finditer(pattern, string)
说明:返回迭代器
>>> import re
>>> re.finditer('addr',"inet addr:10.161.146.134")
<callable_iterator object at 0x00000000030C4BE0> #返回一个迭代器
3. 常用方法
1) group([group1, ...])
说明:获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.group(0)
'addr'
2) groups(default=None)
说明:以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。这个要跟分组匹配结合起来使用'(...)'
>>> import re
>>> a = re.search("(d{2})(d{2})(d{2})(d{4})","320922199508083319") #一个小括号表示一个组,有4个括号,就是4个组
>>> a.groups()
('32', '09', '22', '1995')
3) groupdict(default=None)
说明:返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。这个是跟另外一个分组匹配结合起来用的,即:'(?P<name>...)'
>>> import re
>>> a = re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242")
#以下两种情况获取的值都是一样的
>>> a.groupdict()
{'birthday': '1993', 'city': '81', 'province': '3714'}
>>> a.groupdict("city")
{'birthday': '1993', 'city': '81', 'province': '3714'}
4) span([group])
说明:返回(start(group), end(group))
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span() #获取'addr'在字符串中的开始位置和结束位置
(5, 9)
5) start([group])
说明:返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引),group默认值为0。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span()
(5, 9)
>>> a.start() #获取字符串的起始索引
5
6) end([group])
说明:返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1),group默认值为0。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span()
(5, 9)
>>> a.end() #获取string中的结束索引
9
7) compile(pattern[, flags])
说明:根据包含正则表达式的字符串创建模式对象
>>> import re
>>> m = re.compile("addr") #创建正则模式对象
>>> n = m.search("inet addr:10.161.146.134") #通过模式对象去匹配
>>> n.group()
'addr'
4. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> import re
>>> a = re.split("\\","C: wushuaishuaiyhd_settings")
>>> a
['C:', ' ', 'wushuaishuai', 'yhd_settings']
>>> re.findall('\','abccom')
Traceback (most recent call last)
>>> re.findall('\\','abccom')
['\']
>>> re.findall(r'\','abccom')
['\']
5. 其他匹配模式
1) re.I(re.IGNORECASE)
说明:忽略大小写(括号内是完整的写法,下同)
>>> import re
>>> a = re.search('addr',"inet Addr:10.161.146.134",flags=re.I)
>>> a.group()
'Addr' #忽略大小写
2) re.M(MULTILINE)
说明:多行模式,改变'^'和'$'的行为,详细请见第2点
>>> import re
>>> a = re.search('^a',"inet addr:10.161.146.134",flags=re.M)
>>> a.group()
'a'
3) re.S(DOTALL)
说明:点任意匹配模式,改变'.'的行为
>>> import re
>>> a = re.search('.+',"inet addr:10.161.146.134",flags=re.S)
>>> a.group()
'inet addr:10.161.146.134'
6. 总结
1、用r''的方式表示的字符串叫做raw字符串,用于抑制转义。
2、正则表达式使用反斜杆()来转义特殊字符,使其可以匹配字符本身,而不是指定其他特殊的含义。
3、这可能会和python字面意义上的字符串转义相冲突,这也许有些令人费解,比如,要匹配一个反斜杆本身,你也许要用'\\'来做为正则表达式的字符串,因为正则表达式要是\,而字符串里,每个反斜杆都要写成\。
4、你也可以在字符串前加上 r 这个前缀来避免部分疑惑,因为 r 开头的python字符串是 raw 字符串,所以里面的所有字符都不会被转义,比如r' '这个字符串就是一个反斜杆加上一字母n,而' '我们知道这是个换行符。因此,上面的'\\'你也可以写成r'\',这样,应该就好理解很多了。