李建忠老师有一个设计模式的课程,其中在讲到模板方法模式曾说:如果你只想学习一种设计模式就学习模板方法吧。由此可见它使用的广泛性。 今天咱们就来一起学习模板方法模式。
那什么是模板方法模式呢?
在回答这个问题前,咱们先来看看模板。提到模板,相信大家马上能够想到一些东西,如ppt的模板,报表导出的excel模板,简历的模板等等。使用它们的好处当然是显而易见的:它们可以给我们提供特定的结构和样式,我们就只需关心填充数据内容。将模板的思想发散到编程上,就是我们今天的主题了。
1.定义
首先看下模板方法模式的定义:
在一个方法中定义算法的骨架,将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重新定义该算法的某些特定步骤。
2.类图
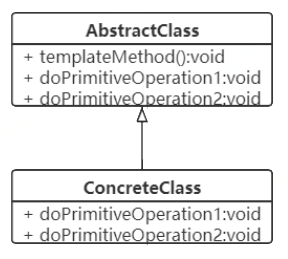
通过模板方法模式的类图,可以看到包括两个角色,抽象的父类、具体的子类。 模板方法模式的意思就是说,在父类里面有一个方法templateMethod,是模板方法,在这个方法中,调用了doPrimitiveOperation1以及doPrimitiveOperation2。在子类里面,如果想改变doPrimitiveOperation1和doPrimitiveOperation2的内容,直接重写父类里的这两个方法,实现自己的那部分实现就可以了,而这部分代码在父类的templateMethod模板方法中会自动调用到。
3.简单案例
我们来看一个关于数据处理的简单案例。
1 abstract class DataParser { 2 3 // 模板方法,通用数据处理流程模板,final方法,子类不能重载 4 public final void process() { 5 readData(); 6 processData(); 7 writeData(); 8 } 9 10 // 由子类实现的抽象方法 11 abstract void readData(); 12 // 由子类实现的抽象方法 13 abstract void processData(); 14 15 // 所有子类都相同的实现 16 public void writeData() { 17 System.out.println("Ouput generated, writing to CSV"); 18 } 19 }
假设有一个类叫DataParser的抽象类,是做数据处理的。我们用模板方法来做数据处理,在DataParser抽象类里首先有一个叫process的模板方法,这个process方法规范了数据处理的一个流程。做数据处理有三步,读数据、处理数据、写数据,整个共享的流程就被规范在这个process方法里头。
下面有两个抽象方法,一个是叫readData,一个是叫processData。这两个都是抽象方法,就是说具体怎么读数据,怎么处理数据,是需要由子类来覆盖,来实现这个抽象方法。
还有一个叫writeData的方法,也是流程的一部分,对所有子类是一样的,所以在父类中直接就实现了。
所以模板方法模式的核心或者说关键点就是,规范了一个流程,读数据,处理数据,写数据。然后这些具体的工作,读数据,处理数据,声明成模板里的抽象的方法,由具体的子类来覆盖。
然后是两个子类的实现。一个是CSVDataParser。
public class CSVDataParser extends DataParser { @Override void readData() { System.out.println("Reading data from csv file"); } @Override void processData() { System.out.println("Looping through loaded csv file"); } }
CSVDataParser继承扩展自DataParser。只需要实现读数据,处理数据的方法。读数据用csv的方法,处理数据用csv的方法处理。
另外一个子类的实现是DatabaseDataParser。
public class DatabaseDataParser extends DataParser { @Override void readData() { System.out.println("Reading data from database"); } @Override void processData() { System.out.println("Looping through records in DB"); } }
DatabaseDataParser,数据库的数据处理。也是扩展自DataParser。读数据从数据库里读,对数据库的数据进行处理。
这两个从模板方法继承下来的实现子类,他们覆盖两个抽象方法,一个是read,一个是process。
再看下客户端代码。
public class TemplateMethodMain { public static void main(String[] args) { CSVDataParser csvDataParser = new CSVDataParser(); csvDataParser.process(); System.out.println("**********************"); DatabaseDataParser databaseDataParser = new DatabaseDataParser(); databaseDataParser.process(); } }
首先new一个CSVDataParser,然后调process方法,这个process方法的流程是在父类里规范的,但是具体的步骤的实现是在子类里实现的。
4.好处
用了模板方法模式,到底给我们带来什么好处呢?
主要是三点。
首先扩展比较灵活,子类可以扩展定制的一些行为。在模板里我们定义了公共的行为,有些是具体实现,大部分是抽象的。这些抽象的方法由子类自己去扩展,根据具体的需要,是读数据库还是CSV文件,这些具体的定制的行为由子类去扩展。
第二是复用,避免了代码的重复,总的流程只实现一次,在父类里已经规范好了。每个子类不需要再去实现这个流程。
第三是规范化,规范流程和不能改变的步骤,意思就是在父类里把一些关键的步骤或者流程已经规范好了,这些是子类不能改变的。子类只能去改变某些步骤。就是可以扩展某些定制的行为。所以有规范,同时也有扩展。
5.原理
模板方法模式涉及到软件开发的一些基本原理。
首先是开闭原则,类应该对修改关闭,对扩展开放,是solid中比较基本的一个原则。模板方法模式就是遵循这个开闭原则,通过子类扩展的方式去扩展,但是不能修改父类的流程,父类对修改是封闭的,由子类去扩展。
另外还遵循好莱坞原理。你不要来叫我,有事情干的时候我会来叫你。当我们用模板方法模式编写一个程序时,就意味着子类放弃了对自己的控制权,而是改为父类通知子类,哪些方法应该在什么时候被调用。作为子类,只负责提供一些设计上的细节。好莱坞原则也是IOC的核心原则。所有的组件都是被动的(Passive),所有的组件初始化和调用都由Spring容器负责,控制对象的生命周期和对象间的关系。
6.实际应用
1)JUnit TestCase
JUnit 框架通过模板模式提供了一些功能扩展点(setUp()、tearDown() 等),让框架用户可以在这些扩展点上扩展功能。
在使用 JUnit 测试框架来编写单元测试的时候,我们编写的测试类都要继承框架提供的 TestCase 类。在 TestCase 类中,runBare() 函数是模板方法,它定义了执行测试用例的整体流程:先执行 setUp() 做些准备工作,然后执行 runTest() 运行真正的测试代码,最后执行 tearDown() 做扫尾工作。
TestCase 类的具体代码如下所示。尽管 setUp()、tearDown() 并不是抽象函数,还提供了默认的实现,不强制子类去重新实现,但这部分也是可以在子类中定制的,所以也符合模板模式的定义。
public abstract class TestCase extends Assert implements Test { public void runBare() throws Throwable { Throwable exception = null; setUp(); try { runTest(); } catch (Throwable running) { exception = running; } finally { try { tearDown(); } catch (Throwable tearingDown) { if (exception == null) exception = tearingDown; } } if (exception != null) throw exception; } /** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } }
2)HttpServlet
HttpServlet 的 service() 方法就是一个模板方法,它实现了整个 HTTP 请求的执行流程,doGet()、doPost() 是模板中可以由子类来定制的部分。这就相当于 Servlet 框架提供了一个扩展点(doGet()、doPost() 方法),让框架用户在不用修改 Servlet 框架源码的情况下,将业务代码通过扩展点镶嵌到框架中执行。
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException { HttpServletRequest request; HttpServletResponse response; if (!(req instanceof HttpServletRequest && res instanceof HttpServletResponse)) { throw new ServletException("non-HTTP request or response"); } request = (HttpServletRequest) req; response = (HttpServletResponse) res; service(request, response); } protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String method = req.getMethod(); if (method.equals(METHOD_GET)) { long lastModified = getLastModified(req); if (lastModified == -1) { // servlet doesn't support if-modified-since, no reason // to go through further expensive logic doGet(req, resp); } else { long ifModifiedSince = req.getDateHeader(HEADER_IFMODSINCE); if (ifModifiedSince < lastModified) { // If the servlet mod time is later, call doGet() // Round down to the nearest second for a proper compare // A ifModifiedSince of -1 will always be less maybeSetLastModified(resp, lastModified); doGet(req, resp); } else { resp.setStatus(HttpServletResponse.SC_NOT_MODIFIED); } } } else if (method.equals(METHOD_HEAD)) { long lastModified = getLastModified(req); maybeSetLastModified(resp, lastModified); doHead(req, resp); } else if (method.equals(METHOD_POST)) { doPost(req, resp); } else if (method.equals(METHOD_PUT)) { doPut(req, resp); } else if (method.equals(METHOD_DELETE)) { doDelete(req, resp); } else if (method.equals(METHOD_OPTIONS)) { doOptions(req,resp); } else if (method.equals(METHOD_TRACE)) { doTrace(req,resp); } else { String errMsg = lStrings.getString("http.method_not_implemented"); Object[] errArgs = new Object[1]; errArgs[0] = method; errMsg = MessageFormat.format(errMsg, errArgs); resp.sendError(HttpServletResponse.SC_NOT_IMPLEMENTED, errMsg); } }
我们只需要定义一个继承 HttpServlet 的类,并且重写其中的 doGet() 或 doPost() 方法,来分别处理 get 和 post 请求。具体的代码示例如下所示:
public class HelloServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { this.doPost(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { resp.getWriter().write("Hello World."); } }
我们还需要在配置文件 web.xml 中做如下配置。Tomcat、Jetty 等 Servlet 容器在启动的时候,会自动加载这个配置文件中的 URL 和 Servlet 之间的映射关系。
<servlet>
<servlet-name>HelloServlet</servlet-name>
<servlet-class>com.xzg.cd.HelloServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloServlet</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
当我们在浏览器中输入网址(比如,http://127.0.0.1:8080/hello )的时候,Servlet 容器会接收到相应的请求,并且根据 URL 和 Servlet 之间的映射关系,找到相应的 Servlet(HelloServlet),然后执行它的 service() 方法。service() 方法定义在父类 HttpServlet 中,它会调用 doGet() 或 doPost() 方法,然后输出数据(“Hello world”)到网页。
3) InputStream
Java IO 类库中,有很多类的设计用到了模板模式,比如 InputStream、OutputStream、Reader、Writer。我们拿 InputStream 来举例说明一下。
InputStream抽象类代码中,read() 方法是一个模板方法,定义了读取数据的整个流程,并且暴露了一个可以由子类来定制的抽象方法。不过这个方法也被命名为了 read(),只是参数跟模板方法不同。
public abstract class InputStream implements Closeable { //...省略其他代码... public int read(byte b[], int off, int len) throws IOException { if (b == null) { throw new NullPointerException(); } else if (off < 0 || len < 0 || len > b.length - off) { throw new IndexOutOfBoundsException(); } else if (len == 0) { return 0; } int c = read(); if (c == -1) { return -1; } b[off] = (byte)c; int i = 1; try { for (; i < len ; i++) { c = read(); if (c == -1) { break; } b[off + i] = (byte)c; } } catch (IOException ee) { } return i; } public abstract int read() throws IOException; } public class ByteArrayInputStream extends InputStream { //...省略其他代码... @Override public synchronized int read() { return (pos < count) ? (buf[pos++] & 0xff) : -1; } }
InputStream的子类比如ByteArrayInputStream,重写read抽象方法,来实现个性化处理。
4) AbstractList
在 Java AbstractList 类中,addAll() 函数可以看作模板方法,add() 是子类需要重写的方法,尽管没有声明为 abstract 的,但函数实现直接抛出了 UnsupportedOperationException 异常。前提是,如果子类不重写是不能使用的。
public boolean addAll(int index, Collection<? extends E> c) { rangeCheckForAdd(index); boolean modified = false; for (E e : c) { add(index++, e); modified = true; } return modified; } public void add(int index, E element) { throw new UnsupportedOperationException(); }
比如AbstractList抽象类的子类ArrayList,通过重写add方法,来实现添加数组元素的个性化处理。
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; }
子类LinkedList,重写add方法,来实现添加链表元素的个性化处理。
public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); }
5) JDBCTemplate
Spring 提供了很多 Template 类,比如,JdbcTemplate、RedisTemplate、RestTemplate。尽管都叫作 xxxTemplate,但它们并非基于模板模式来实现的,而是基于回调来实现的,确切地说应该是同步回调。而同步回调从应用场景上很像模板模式,所以,在命名上,这些类使用 Template(模板)这个单词作为后缀。
这些 Template 类的设计思路都很相近,我们拿 JdbcTemplate 来举例分析一下。
Java 提供了 JDBC 类库来封装不同类型的数据库操作。不过,直接使用 JDBC 来编写操作数据库的代码,还是有点复杂的。比如,下面这段是使用 JDBC 来查询用户信息的代码。
public class JdbcDemo { public User queryUser(long id) { Connection conn = null; Statement stmt = null; try { //1.加载驱动 Class.forName("com.mysql.jdbc.Driver"); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/demo", "xzg", "xzg"); //2.创建statement类对象,用来执行SQL语句 stmt = conn.createStatement(); //3.ResultSet类,用来存放获取的结果集 String sql = "select * from user where id=" + id; ResultSet resultSet = stmt.executeQuery(sql); String eid = null, ename = null, price = null; while (resultSet.next()) { User user = new User(); user.setId(resultSet.getLong("id")); user.setName(resultSet.getString("name")); user.setTelephone(resultSet.getString("telephone")); return user; } } catch (ClassNotFoundException e) { // TODO: log... } catch (SQLException e) { // TODO: log... } finally { if (conn != null) try { conn.close(); } catch (SQLException e) { // TODO: log... } if (stmt != null) try { stmt.close(); } catch (SQLException e) { // TODO: log... } } return null; } }
queryUser() 函数包含很多流程性质的代码,跟业务无关,比如,加载驱动、创建数据库连接、创建 statement、关闭连接、关闭 statement、处理异常。针对不同的 SQL 执行请求,这些流程性质的代码是相同的、可以复用的,我们不需要每次都重新敲一遍。
针对这个问题,Spring 提供了 JdbcTemplate,对 JDBC 进一步封装,来简化数据库编程。使用 JdbcTemplate 查询用户信息,我们只需要编写跟这个业务有关的代码,其中包括,查询用户的 SQL 语句、查询结果与 User 对象之间的映射关系。其他流程性质的代码都封装在了 JdbcTemplate 类中,不需要我们每次都重新编写。用 JdbcTemplate 重写上面的例子,代码简单了很多,如下所示:
public class JdbcTemplateDemo { private JdbcTemplate jdbcTemplate; public User queryUser(long id) { String sql = "select * from user where id="+id; return jdbcTemplate.query(sql, new UserRowMapper()).get(0); } class UserRowMapper implements RowMapper<User> { public User mapRow(ResultSet rs, int rowNum) throws SQLException { User user = new User(); user.setId(rs.getLong("id")); user.setName(rs.getString("name")); user.setTelephone(rs.getString("telephone")); return user; } } }
dbcTemplate 通过回调的机制,将不变的执行流程抽离出来,放到模板方法 execute() 中,将可变的部分设计成回调 StatementCallback,由用户来定制。query() 函数是对 execute() 函数的二次封装,让接口用起来更加方便。
@Override public <T> List<T> query(String sql, RowMapper<T> rowMapper) throws DataAccessException { return query(sql, new RowMapperResultSetExtractor<T>(rowMapper)); } @Override public <T> T query(final String sql, final ResultSetExtractor<T> rse) throws DataAccessException { Assert.notNull(sql, "SQL must not be null"); Assert.notNull(rse, "ResultSetExtractor must not be null"); if (logger.isDebugEnabled()) { logger.debug("Executing SQL query [" + sql + "]"); } class QueryStatementCallback implements StatementCallback<T>, SqlProvider { @Override public T doInStatement(Statement stmt) throws SQLException { ResultSet rs = null; try { rs = stmt.executeQuery(sql); ResultSet rsToUse = rs; if (nativeJdbcExtractor != null) { rsToUse = nativeJdbcExtractor.getNativeResultSet(rs); } return rse.extractData(rsToUse); } finally { JdbcUtils.closeResultSet(rs); } } @Override public String getSql() { return sql; } } return execute(new QueryStatementCallback()); } @Override public <T> T execute(StatementCallback<T> action) throws DataAccessException { Assert.notNull(action, "Callback object must not be null"); Connection con = DataSourceUtils.getConnection(getDataSource()); Statement stmt = null; try { Connection conToUse = con; if (this.nativeJdbcExtractor != null && this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativeStatements()) { conToUse = this.nativeJdbcExtractor.getNativeConnection(con); } stmt = conToUse.createStatement(); applyStatementSettings(stmt); Statement stmtToUse = stmt; if (this.nativeJdbcExtractor != null) { stmtToUse = this.nativeJdbcExtractor.getNativeStatement(stmt); } T result = action.doInStatement(stmtToUse); handleWarnings(stmt); return result; } catch (SQLException ex) { // Release Connection early, to avoid potential connection pool deadlock // in the case when the exception translator hasn't been initialized yet. JdbcUtils.closeStatement(stmt); stmt = null; DataSourceUtils.releaseConnection(con, getDataSource()); con = null; throw getExceptionTranslator().translate("StatementCallback", getSql(action), ex); } finally { JdbcUtils.closeStatement(stmt); DataSourceUtils.releaseConnection(con, getDataSource()); } }