整数集合
Redis 中当一个集合(set)中只包含整数,并且元素不多时,底层使用整数集合实现,否则使用字典实现。
那么:
- 为什么会出现整数集合呢?都使用字典存储不行吗?
- 整数集合在 Redis 中的结构是怎样的呢?
- 引入整数集合之后,会不会出现什么弊端?Redis 又是如何去解决的呢?
为什么会出现整数集合呢?都使用字典存储不行吗?
说起无序集合(set),很自然的就想起哈希表,而哈希表表现也很好,提供了查询为 O(1) 的时间复杂度。但任何事物有优点,就必然会伴随着一些缺点,哈希表的缺点就是使用的储存空间大,其实哈希表本身就是空间换取时间的一种方式。
Redis 作为一个缓存,考虑到内存的使用,所以出现了整数集合这一数据结构。然而整数集合虽然相比哈希表很节约内存,但它也是牺牲了速度作为代价的。所以 Redis 中也只是在数据量少的条件下才会去使用整数集合代替哈希表。
整数集合在 Redis 中的结构是怎样的呢?
Redis 中的整数集合由 intset.h/intset 表示,具体结构如下:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
length属性表示整数集合包含的元素数量,即是contents数组的长度。
contents 数组是整个整数集合最核心的部分,元素就存储在这个数组中,各个元素从小到大有序排列,并且没有重复元素。虽然 contents 数组是声明成int8_t的类型,但是存储元素的真正类型并不是 int8_t 而是由 encoding 属性来表示 contents 数组真正的类型。比如:
- 如果 encoding 属性的值为 INTSET_ENC_NT16,那么 contents 就是一个 int16_t 类型的数组,数组里的每个项都是一个 int16_t 类型的整数值(最小值为 -32768,最大值为 32767)。
- 如果 encoding 属性的值为 INTSET_ENC_NT32,那么 contents 就是一个 int32_t 类型的数组,数组里的每个项都是一个 int32_t 类型的整数值(最小值为 -2^31,最大值为 2^31-1)。
引入整数集合之后,会不会出现什么弊端?
当我们向集合中插入元素时,Redis 并没有让我们指定插入的数值是几个字节的,那么如果我们先插入了 int16_t 的元素,然后插入了一个 int32_t 的元素,那么这时候原来的 contents 存不了新插入的值,这个时候该怎么做呢? 这也就是 Redis 引入整数集合之后所要解决的问题。
Redis 为了解决这个问题,于是引入了升级。
升级
每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有所有元素的类型都要长时,整数集合需要先进行升级,然后才能将新元素添加到整数集合里面。具体步骤如下:
- 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素
- 将新元素添加到底层数组(contents)里面。
升级的时间复杂度是 O(n),又每次向整数集合添加新元素都可能引发升级,所以整数集合添加新元素的时间复杂度是 O(n)。
而为整数集合引入升级之后,主要带来了两点好处:
第一:提升了程序的灵活性。
第二:节约内存。
看到这里,可能有的人会想,有了升级,那么有没有降级呢?很遗憾,Redis 中的整数集合没有降级,也就是说只能扩容,不能缩容。
压缩列表
本篇只是简单介绍一下压缩列表,所以暂不深入讲解,感兴趣的可以自行查阅其他资料。
Redis 在什么情况下会使用压缩列表作为底层实现呢?
- 列表只包含少量元素,并且每个列表项要么是小整数值,要么是长度较短的字符串。
- 哈希键中只包含少量键值对,并且每个键值对的键和值要么是小整数值,要么是长度较短的字符串。
其实看到压缩二字,就能联想到节约内存。所以本篇介绍的整数集合和压缩列表都是为了节约内存而存在的。那么,压缩列表的大致结构是什么?
压缩列表的大致结构
压缩列表是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组(字符串)或者一个整数值。
它的各个组成部分和说明如下(出自《Redis设计与实现第二版》第7章:压缩列表):
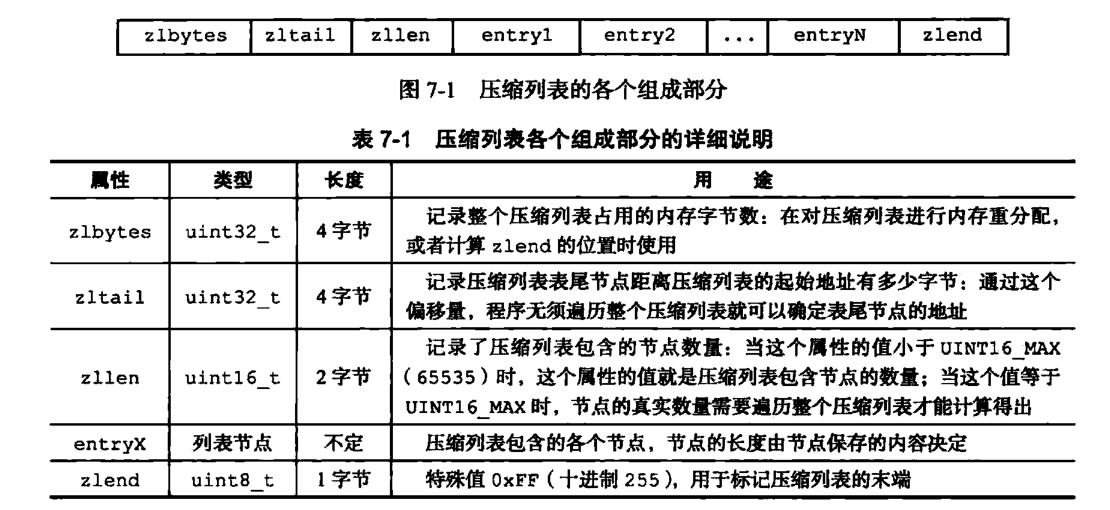
压缩列表更像是一种存储方式,和 Java 字节码中常量池的存储比较类似。感兴趣的可以去查一下。
压缩列表的节点主要由 previous_entry_length、encoding、content 三部分组成。如下图(出自《Redis设计与实现第二版》第7章:压缩列表):

- previous_entry_length 表示压缩列表中前一个节点的长度,单位为字节。
- encoding 记录了节点的 content 属性所保存数据的类型及长度。
- content 则负责保存节点的值。可以使一个字节数组(字符串)或者整数。