Hadoop安装有三种模式,单机模式、伪分布式和分布式安装
伪分布式安装
1、去hadoop官网下载 .tar.gz 文件,并拷贝到虚拟机中
增加hadoop环境变量,
export HADOOP_HOME=/home/wdd/hadoop-2.9.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
上面两句分别在.bash_profile和/etc/profile中增加。
.bash_profile 是限制于用户,
/etc/profile 是全局用户
2、解压,tar -xzf hadoop-2.9.0.tar.gz
压缩、解压命令:
tar –cvf jpg.tar *.jpg //将目录里所有jpg文件打包成tar.jpg
tar –czf jpg.tar.gz *.jpg //将目录里所有jpg文件打包成jpg.tar后,并且将其用gzip压缩,生成一个gzip压缩过的包,命名为jpg.tar.gz
tar –cjf jpg.tar.bz2 *.jpg //将目录里所有jpg文件打包成jpg.tar后,并且将其用bzip2压缩,生成一个bzip2压缩过的包,命名为jpg.tar.bz2
tar –cZf jpg.tar.Z *.jpg //将目录里所有jpg文件打包成jpg.tar后,并且将其用compress压缩,生成一个umcompress压缩过的包,命名为jpg.tar.Z
tar –xvf file.tar //解压 tar包
tar -xzvf file.tar.gz //解压tar.gz
tar -xjvf file.tar.bz2 //解压 tar.bz2
tar –xZvf file.tar.Z //解压tar.Z
unrar e file.rar //解压rar
unzip file.zip //解压zip
3、 配置Hadoop,一般需要配置5个文件,配置文件路径在etc/hadoop
1) 编辑 vi hadoop-env.sh
增加java环境变量,如下
export JAVA_HOME=/home/jdk/ 或者 export JAVA_HOME=${JAVA_HOME}
2) 编辑 vi core-site.xml,配置如下:
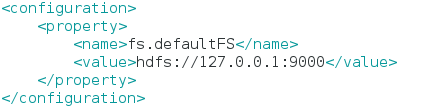
3) 编辑 vi hdfs-site.xml,datanode可以配置多个

4) 编辑vi mapred-site.xml,需要根据mapred-site.xml.template创建(cp mapred-site.xml.template mapred-site.xml)
编辑如下:

5) 编辑 vi yarn-site.xml

6) 然后创建上述配置中出现的目录,并分配读写权限
7)启动hdfs namenode -format,报错如下:
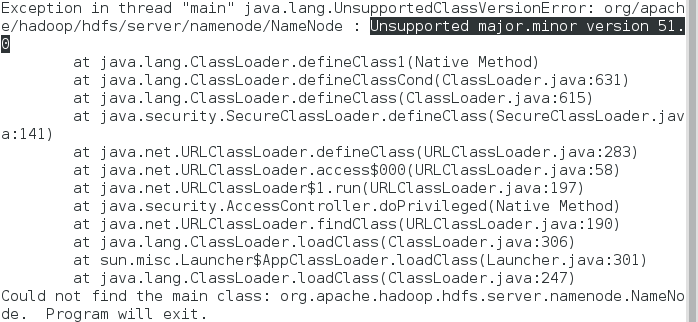
原因,版本不匹配所致,不同的JDK使用不同的 major.minor.
Hadoop版本高于2.7应该用jdk1.7
低于2.6应该用jdk1.6
8) 更换jdk版本,成功执行
4、启动hadoop
1) 启动hdfs集群
hadoop-daemon.sh start namenode 启动主节点
hadoop-daemon.sh start datanode 启动从节点

2) 启动yarn集群
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager

3)启动作业历史服务器
mr-jobhistory-daemon.sh start historyserver

4) jps查看是否启动成功,成功启动
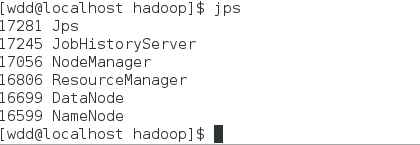
5) 查看是否启动成功,
http://localhost:50070
http://localhost:8088