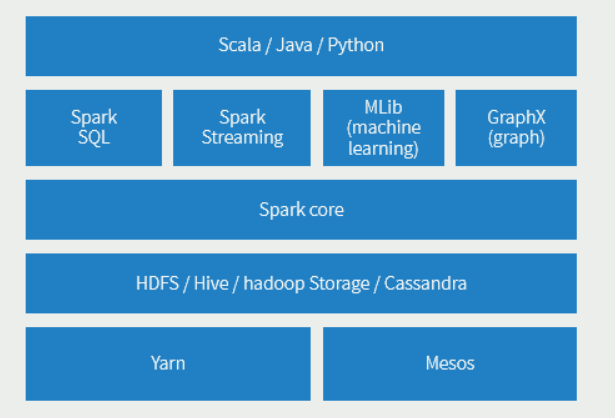
Spark的架构图
1、RDD(弹性分布式数据集)
RDD是对象的分布式集合。
RDD以并行方式应用和记录数据转换
RDD也提供数据沿袭——以图形形式给出每个中间步骤的祖先树,当RDD的一个分区丢失,可以根据祖先树重建该分区。
RDD有两组操作,转换(transformation)和行动(action),RDD转换是有惰性的,宽窄依赖。
2、SparkSession
本质上是对SparkConf、SparkContext、SQLContext、SQLContext、HiveContext和StreamingContext等的组合。
SparkSession是读取数据、处理元数据、配置会话和管理集群资源的入口。
3、Dataset和DataFrame
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。DataSet是在Spark1.6中添加的新的接口。
它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作。
DataFrame开始被定义为指定到列的数据集(Dataset),DF可以生成临时表,使用SQL语言。
Dataset和DataFrame的之间可以相互转换。
4、Spark SQL
Spark SQL使用的是Catalyst优化器,基本支持大多数SQL语法。
5、Spark Streaming
Spark Streaming是一个准实时的流式处理工具,按照时间切分,批处理一个个切分后的文件。底层依然是Spark离线处理的逻辑。