Tensorflow2.0笔记
本博客为Tensorflow2.0学习笔记,感谢北京大学微电子学院曹建老师
4.4 InceptionNet
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense,
GlobalAveragePooling2D
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/Inception10.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '
')
file.write(str(v.shape) + '
')
file.write(str(v.numpy()) + '
')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
借鉴点:一层内使用不同尺寸的卷积核,提升感知力(通过padding实现输出特征面积一致);使用1 * 1卷积核,改变输出特征channel数(减少网络参数)。
InceptionNet即GoogLeNet,诞生于2015年,旨在通过增加网络的宽度来提升网络的能力,与VGGNet通过卷积层堆叠的方式(纵向)相比,是一个不同的方向(横向)。
显然,InceptionNet模型的构建与VGGNet及之前的网络会有所区别,不再是简单的纵向堆叠,要理解InceptionNet的结构,首先要理解它的基本单元,如图5- 27所示。
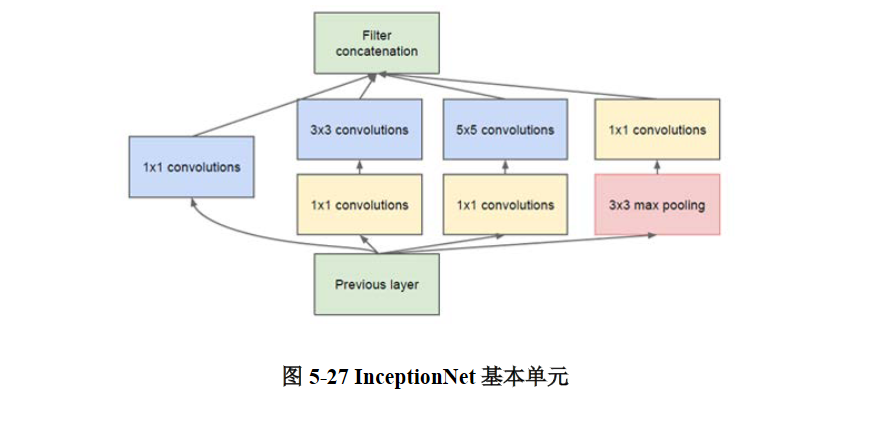
可以看到,InceptionNet的基本单元中,卷积部分是比较统一的C、B、A典型结构,即卷积→BN→激活,激活均采用Relu激活函数 ,同时包含最大池化操作。
在Tensorflow框架下利用Keras构建InceptionNet模型时,可以将C、B、A结构封装在一起,定义成一个新的ConvBNRelu类,以减少代码量,同时更便于阅读。
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
参数ch代表特征图的通道数,也即卷积核个数;kernelsz代表卷积核尺寸;strides代表卷积步长;padding代表是否进行全零填充。
完成了这一步后,就可以开始构建InceptionNet的基本单元了,同样利用class定义的方式,定义一个新的InceptionBlk类,如5- 28所示。
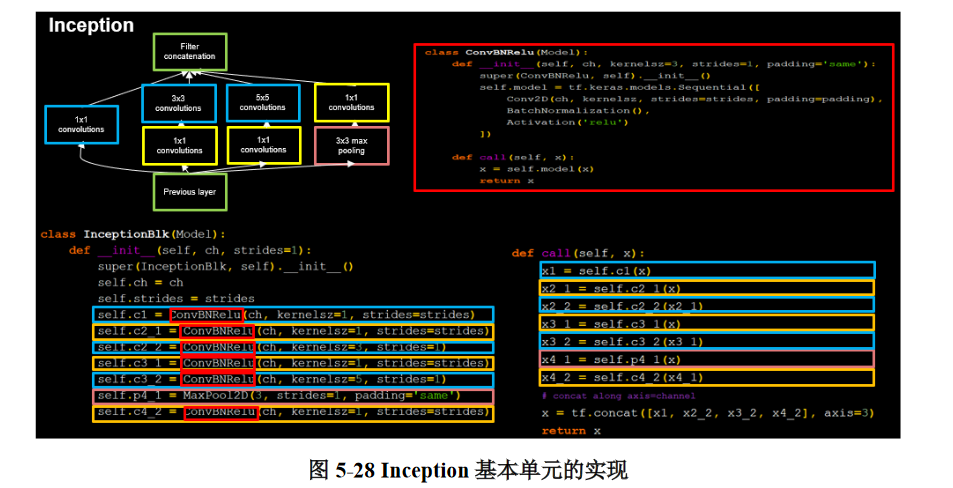
参数ch仍代表通道数,strides代表卷积步长,与ConvBNRelu类中一致;tf.concat函数将四个输出连接在一起,x1、x2_2、x3_2、x4_2分别代表图5- 27中的四列输出,结合结构图和代码很容易看出二者的对应关系。
可以看到,InceptionNet的一个显著特点是大量使用了1 * 1的卷积核,事实上,最原始的InceptionNet的结构是不包含1 * 1卷积的,如图5- 29所示。
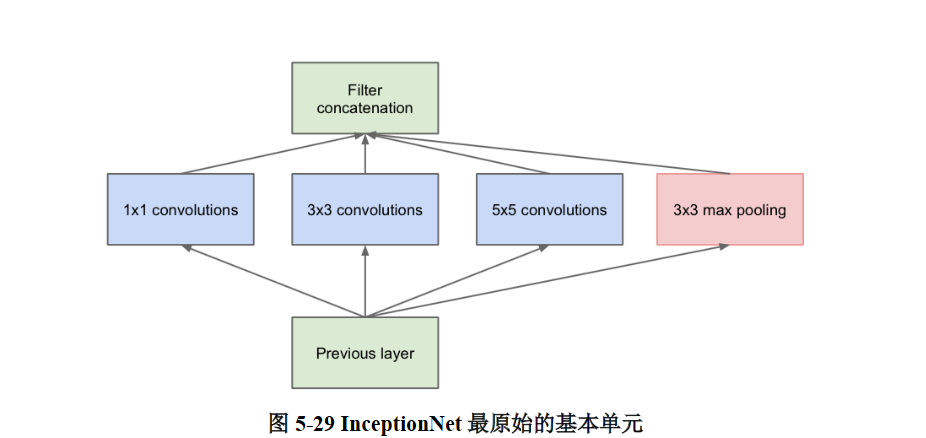
由图5- 29可以更清楚地看出InceptionNet最初的设计思想,即通过不同尺寸卷积层和池化层的横向组合(卷积、池化后的尺寸相同,通道可以相加)来拓宽网络深度,可以增加网络对尺寸的适应性。但是这样也带来一个问题,所有的卷积核都会在上一层的输出上直接做卷积运算,会导致参数量和计算量过大(尤其是对于5 * 5的卷积核来说)。因此,InceptionNet在3 * 3、5 * 5的卷积运算前、最大池化后均加入了1 * 1的卷积层,形成了图5- 24中的结构,这样可以降低特征的厚度,一定程度上避免参数量过大的问题。
那么1 * 1的卷积运算是如何降低特征厚度的呢?下面以5 * 5的卷积运算为例说明这个问题。假设网络上一层的输出为100 * 100 * 128(H * W * C),通过32 * 5 * 5(32个大小为5 * 5的卷积核)的卷积层(步长为1、全零填充)后,输出为100 * 100 * 32,卷积层的参数量为32 * 5 * 5 * 128 = 102400;如果先通过32 * 1 * 1的卷积层(输出为100 * 100 * 32),再通过32 * 5 * 5的卷积层,输出仍为100 * 100 * 32,但卷积层的参数量变为32 * 1 * 1 * 128 + 32 * 5 * 5 * 32 = 29696,仅为原参数量的30 %左右,这就是小卷积核的降维作用。
InceptionNet网络的主体就是由其基本单元构成的,其模型 结构如图5- 30所示。
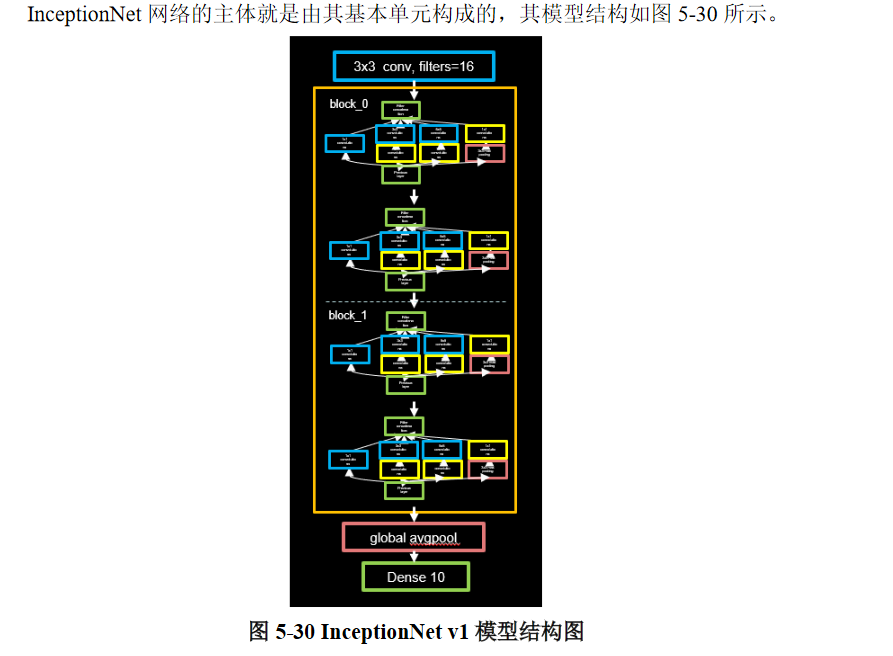
图中橙色框内即为InceptionNet的基本单元,利用之前定义好的InceptionBlk类堆叠而成,模型的实现代码如下。
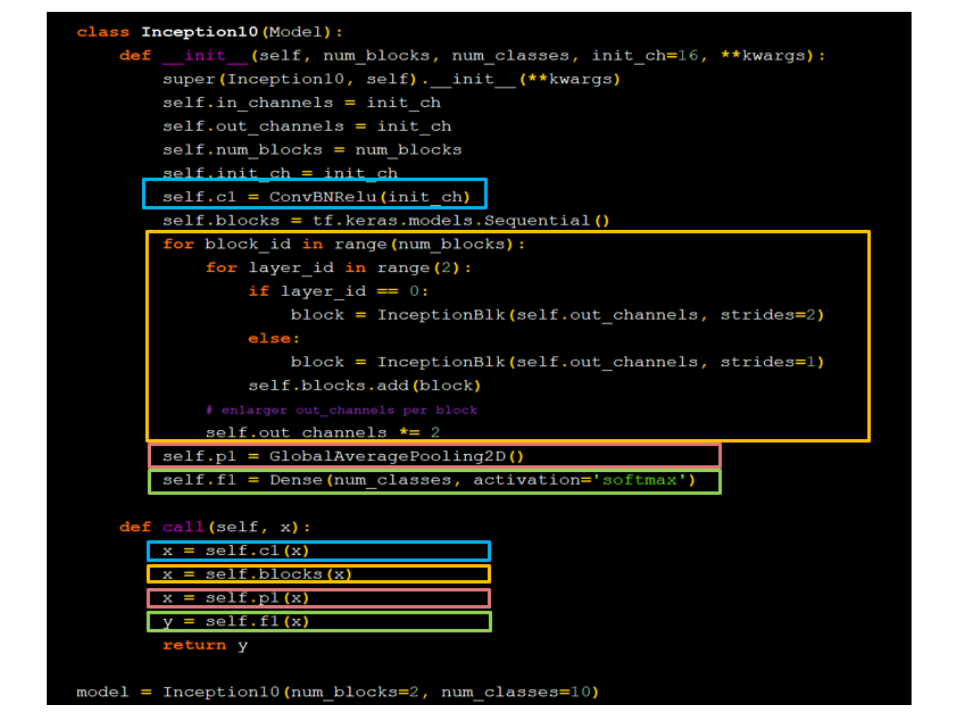
参数num_layers代表InceptionNet的Block数,每个Block由两个基本单元构成,每经过一个Block,特征图尺寸变为1/2,通道数变为2倍;num_classes代表分类数,对于cifar10数据集来说即为10;init_ch代表初始通道数,也即InceptionNet基本单元的初始卷积核个数。
InceptionNet网络不再像VGGNet一样有三层全连接层(全连接层的参数量占VGGNet总参数量的90 %),而是采用“全局平均池化+全连接层”的方式 ,这减少了大量的参数。
这里介绍一下全局平均池化,在tf.keras中用GlobalAveragePooling2D函数实现,相比于平均池化(在特征图上以窗口的形式滑动,取窗口内的平均值为采样值),全局平均池化不再以窗口滑动的形式取均值,而是直接针对特征图取平均值,即每个特征图输出一个值。通过这种方式,每个特征图都与分类概率直接联系起来,这替代了全连接层的功能,并且不产生额外的训练参数,减小了过拟合的可能,但需要注意的是,使用全局平均池化会导致网络收敛的速度变慢。
总体来看,InceptionNet采取了多尺寸卷积再聚合的方式拓宽网络结构,并通过1 * 1的卷积运算来减小参数量,取得了比较好的效果,与同年诞生的VGGNet相比,提供了卷积神经网络构建的另一种思路。但InceptionNet的问题是,当网络深度不断增加时,训练会十分困难,甚至无法收敛(这一点被ResNet很好地解决了)。