Tensorflow2.0笔记
本博客为Tensorflow2.0学习笔记,感谢北京大学微电子学院曹建老师
2.7Batch Normalization(批标准化):
对一小批数据在网络各层的输出做标准化处理,其具体实现方式如图 5-10 所示。(标准化:使数据符合 0 均值,1 为标准差的分布。)
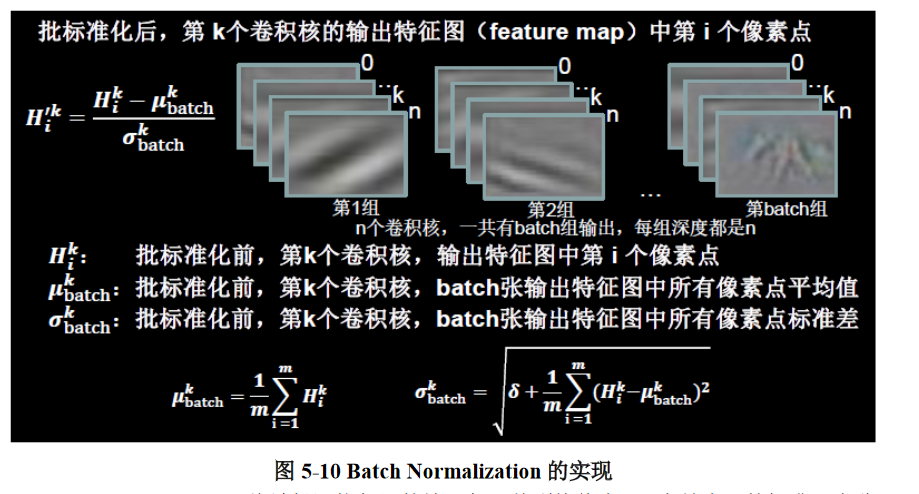
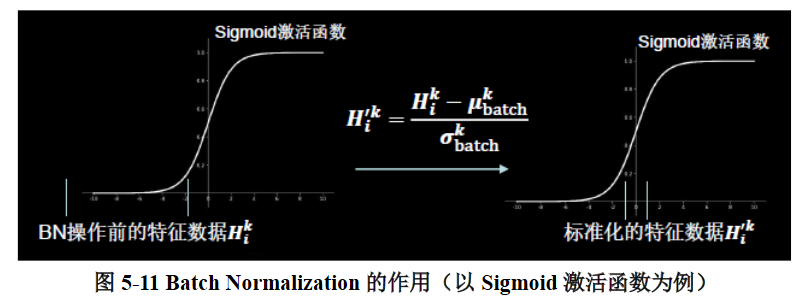
Batch Normalization 将神经网络每层的输入都调整到均值为 0,方差为 1 的标准正态分布,其目的是解决神经网络中梯度消失的问题,如图 5-11 所示。
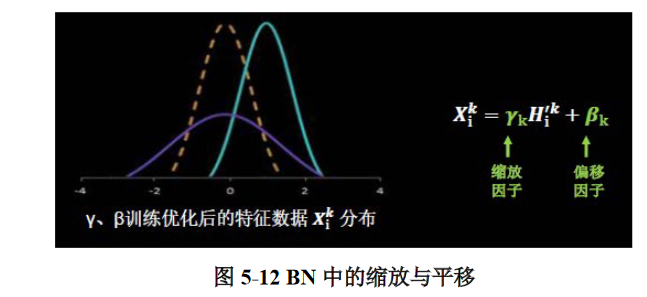
BN 操作的另一个重要步骤是缩放和偏移,值得注意的是,缩放因子 γ 以及偏移因子 β都是可训练参数,其作用如图 5-12 所示。
BN 操作通常位于卷积层之后,激活层之前,在 Tensorflow 框架中,通常使用 Keras 中的tf.keras.layers.BatchNormalization 函数来构建 BN 层。
在调用此函数时,需要注意的一个参数是 training,此参数只在调用时指定,在模型进行前向推理时产生作用,当 training = True 时,BN 操作采用当前 batch 的均值和标准差;当training = False 时,BN 操作采用滑动平均(running)的均值和标准差。在 Tensorflow 中, 通常会指定 training = False,可以更好地反映模型在测试集上的真实效果。
滑动平均(running)的解释:滑动平均,即通过一个个 batch 历史的叠加,最终趋向数据集整体分布的过程,在测试集上进行推理时,滑动平均的参数也就是最终保存的参数。
此外,Tensorflow 中的 BN 函数其实还有很多参数,其中比较常用的是 momentum,即动量参数,与 sgd 优化器中的动量参数含义类似但略有区别,具体作用为滑动平均 running = momentum * running + (1 – momentum) * batch,一般设置一个比较大的值,在Tensorflow 框架中默认为 0.99。
2.8池化(pooling)
池化的作用是减少特征数量(降维)。最大值池化可提取图片纹理,均值池化可保留背景特征,如图 5-13 所示。

在Tensorflow 框架下,可以利用 Keras 来构建池化层,使用的是 tf.keras.layers.MaxPool2D 函 数 和tf.keras.layers.AveragePooling2D 函 数 , 具 体 的 使 用 方 法 如 下 :
tf.keras.layers.MaxPool2D(
pool_size = 池化核尺寸, strides = 池化步长,
padding = ‘SAME’ or ‘VALID’
)
tf.keras.layers.AveragePooling2D(
pool_size = 池化核尺寸,
strides = 池化步长,
padding = ‘SAME’ or ‘VALID’
)
2.9舍弃(Dropout)
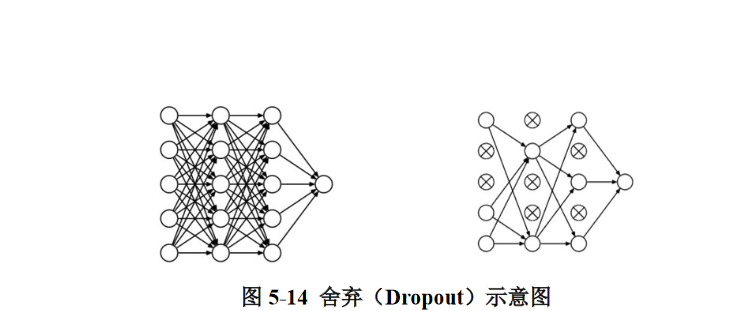
舍弃(Dropout):在神经网络的训练过程中,将一部分神经元按照一定概率从神经网络中暂时舍弃,使用时被舍弃的神经元恢复链接,如图 5-14 所示。
在 Tensorflow 框架下,利用 tf.keras.layers.Dropout 函数构建 Dropout 层,参数为舍弃的概率(大于 0 小于 1)。
利用上述知识,就可以构建出基本的卷积神经网络(CNN)了,其核心思路为在 CNN中利用卷积核(kernel)提取特征后,送入全连接网络。
2.10CNN的主要模块
一般包括上述的卷积层、BN 层、激活函数、池化层以及全连接层,如图 5-15 所示。

在此基础上,可以总结出在 Tensorflow 框架下,利用 Keras 来搭建神经网络的“八股”套路,在主干的基础上,还可以添加其他内容,来完善神经网络的功能,如利用自己的图片和标签文件来自制数据集;通过旋转、缩放、平移等操作对数据集进行数据增强;保存模型文件进行断点续训;提取训练后得到的模型参数以及准确率曲线,实现可视化等。