将txt、csv等文本文件导入Hive
00.数据在虚拟机外
如果数据在虚拟机内,请跳过此步,直接执行接下来的操作。
推荐使用SecureCTR的SFTP传输至虚拟机。
具体操作步骤:使用SecureCTR连接Hadoop虚拟机,在标题栏右击,
选择SFTP传输:
然后将txt或者csv文件拖拽至新打开的窗口即可。
检验:连接虚拟机在根目录下使用ls命令即可看到你传入的文件。
01.启动hadoop、hdfs
Hadoop所在文件
cd /usr/local/hadoop/
启动关闭Hdfs
sbin/start-dfs.sh
sbin/stop-dfs.sh
启动yarn
sbin/start-yarn.sh
sbin/stop-yarn.sh
02.将文件放置在hdfs目录下
我们以txt文件为例,我们要操作的文件是sale_count.txt

使用下列命令将文件放到tmp文件夹下:
hadoop fs -put sale_count.txt /tmp
查看tmp文件夹下的文件:
hadoop fs -ls -h /tmp
03.登录hive并进入指定数据库
进入到hive目录下的bin目录:
cd /usr/local/hive/bin
启动hive:
hadoop@dblab-VirtualBox:/usr/local/hive/bin$ hive
对数据库操作:
//查看数据库
show databases;
//创建数据库
create database test;
//使用test数据库
use test;
04.根据文件创建表
文件:
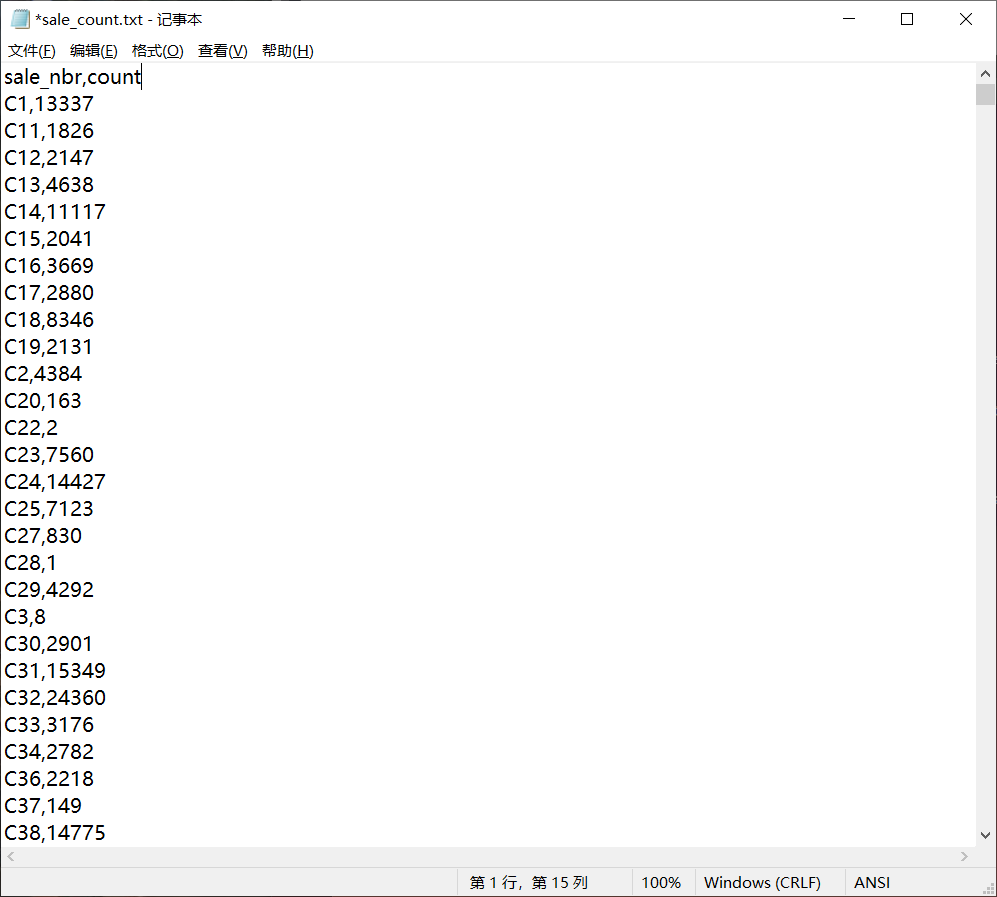
create external table if not exists sale_count(
sale_nbr string,
count string
)row format delimited fields terminated by ',' stored as textfile;
主要部分是最后一部分:row format delimited fields terminated by ',' stored as textfile;
查看表结构:
desc sale_count;
05.执行导入语句
load data inpath '/tmp/sale_count.txt' into table sale_count;
load data local inpath '/tmp/sale_count.txt' into table sale_count;
如果有local关键字,这个路径应该为本地文件系统,数据会被拷贝到目标位置。
入股省略local关键字,这个路径应该是分布式文件系统的路径,数据是从这个路径转移到目标路径。