背景
互联网、传统企业级软件等应用,每天产生海量的日志信息,然而很多情况下被企业和员工所无视,只有遇到线上bug等情况下才会绞尽脑汁索要或者下载有用的日志。挑选有用日志的过程是无比辛苦的,你需要先远程到服务器上,找到日志目录,查看日志文件最后修改时间,比对bug出现时间,ok,下载,怎么会没有呢?会不会被load balancer导到另外一台了呢?噩梦又要重新上演... 经过一个下午的定位,终于找到bug的原因了,好吧,只能晚上加班改了... 苦逼的循环,这只是开始。
我们可以做些什么改变现状呢?
1. log记录在服务器 -> 保存于日志管理系统,如splunk;
2. log记录到文件 -> 导出到stdout/stderr。
第一个比较好理解,日志文件保存在日志管理系统,集中存储,便于索引和查询。第二个呢?就需要提一下SaaS(软件即服务)设计和开发的一个优秀的方法论,[12-factor](https://12factor.net/zh_cn/logs)。12-factor 中将日志当作事件流,将所有运行中进程和后端服务的输出流按照时间顺序收集起来,12-factor应用本身从不考虑存储自己的输出流,不应该试图去写或者管理日志文件,而是通过stdout输出事件流,在测试和产品环境下,输出流由运行环境截获,发送给日志处理程序。
日志管理的功能分类
- 数据/日志采集和传输;
- 日志的索引和存储;
- 日志检索、分析及数据可视化。
splunk日志管理系统
组件
- splunk forwarder (heavy, light, universal*)
- splunk enterprise
- splunk cloud (saas)
部署
单机模式
本文的部署是基于Docker的。请阅读下面内容之前确保掌握docker的基本知识如image、container、docker compose等。
app日志通过Splunk HTTP Event Collector 流入Splunk Enterprise。
app的docker-compose.yml文件如下:
version: '2'
services:
nginx:
hostname: app
image: nginx
ports:
- 80:80
- 443:443
logging:
driver: splunk
options:
splunk-token: 7937D648-3506-4217-8DE2-EEF4F4DBCADC
splunk-url: "http://172.22.0.3:8088"
splunk-source: docker
splunk-sourcetype: docker1
splunk-index: main
tag: "{{.Name}}/{{.FullID}}"
splunk enterprise的docker-compose.yml如下:
version: '2'
services:
vsplunk:
image: busybox
volumes:
- /opt/splunk/etc
- /opt/splunk/var
splunk:
hostname: splunk
image: splunk/splunk:latest
environment:
SPLUNK_START_ARGS: --accept-license
SPLUNK_ENABLE_LISTEN: 9997
SPLUNK_ADD: tcp 1514
volumes_from:
- vsplunk
ports:
- "8000:8000" # web access
- "9997:9997" # for forwarder
- "8088:8088"
app使用的image为nginx,当访问nginx服务时,会输出访问信息到标准输出。splunk enterprise使用的是splunk公司提供的image。docker提供了logging的功能,driver有很多,较为常用的是splunk和fluentd,本文以splunk driver为例。
splunk-token由splunk enterprise提供,配置token的方式有以下3种:
* Web ui,参考http://dev.splunk.com/view/event-collector/SP-CAAAE7C
* CLI,参考http://dev.splunk.com/view/event-collector/SP-CAAAE7D
* 配置文件,路径为/opt/splunk/etc/apps/splunk_httpinput/local/inputs.conf
distributed indexers 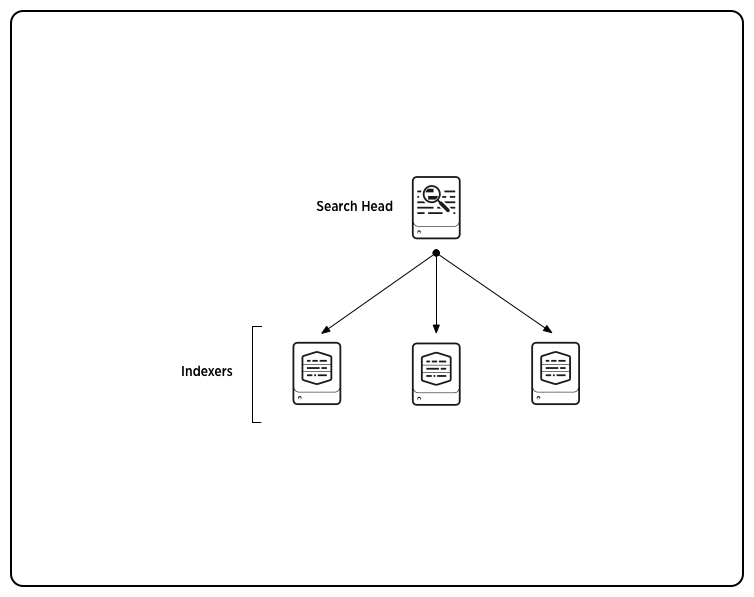
分布式部署和单机部署相比,横向拓展良好。
cluster indexers 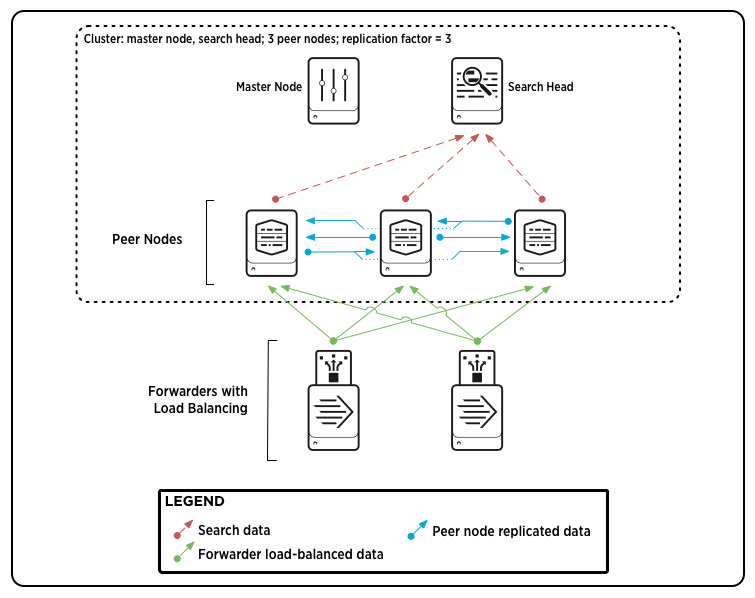
集群部署可以实现灾备,横向拓展,提高检索速度等。
extend reading:
- fluentd/ElasticSearch/kibana
Reference
http://docs.fluentd.org/articles/free-alternative-to-splunk-by-fluentd
http://docs.splunk.com/Documentation/Splunk/6.5.1/Indexer/Aboutclusters
http://docs.splunk.com/Documentation/Splunk/6.5.1/Indexer/HowSplunkstoresindexes
http://docs.fluentd.org/articles/quickstart