一、k8s基本概念
k8s大部分概念比如Node,Pod、RC,service等都可以看做一种资源对象,几乎所有的资源对象都可以通过k8s提供的kubectl工具执行增,删,改,查等操作并将其保存在etcd中持久化存储。
二、master
master指的是集群控制节点,来负责整个集群的管理和控制,基本上k8s的所有控制命令都是发给它。我们后面执行的命令基本都是在master节点上运行的。通常它会占据一个独立的x86服务器(或一个虚拟机)。
master节点上运行一些关键进程:
- k8s API server(kube-apiserver):提供了HTTP Rest接口的关键服务进程,是所有资源的增删改查的唯一入口,也是集群集群控制的入口进程。kubectl的命令会调用到api server,来实现资源的增删查改。
- kube-controller-manager:k8s所有资源对象的自动化控制中心。
- kube-scheduler:pod调度进程。
其实往往还启动了一个etcd server进程。因为k8s里所有资源对象的数据全部是保存在etcd中的。
三、node
k8s集群中其他机器被称为node节点,Node可以是一台物理机,也可以是一台虚拟机。当某个node宕机,其上的工作负载会被master自动转移到其他节点上。
Node运行着一些关键进程:
-
kubelet:负责pod对应的容器创建、启停等任务。
-
kube-porxy:实现service通信的重要组件
-
docker engine:docker引擎,负责本机的容器创建和管理。
node节点可以在运行期间动态增加到k8s集群中,在默认情况下kubelet会将master注册自己,并定时向master汇报自身情报。
可以执行下面命令查看集群中有多少个node:
kubectl get nodes
然后通过下面命令查看某个node的详细信息:
kubectl describe node <node_name>
四、pod

pod的存在主要是让几个紧密连接的几个容器之间共享资源,例如ip地址,共享存储等信息。如果直接调度容器的话,那么几个容器可能运行在不同的主机上,这样就增加了系统的复杂性。
每个pod由一个根容器的pause容器,其他是业务容器。
k8s为每个pod分配了唯一的IP地址,一个pod里的多个容器共享pod IP。
pod其实有两种类型:普通的pod和静态pod,后者比较特殊,它并不存放在etcd存储中,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的pod一旦被创建,就会被放入etcd中存储。随后被master调度到某个具体的Node上并进行绑定,随后该pod被对应的Node上的kubelet进程实例化成一组相关的docker容器并启动起来。
每个pod都可以对其使用的服务器上的计算资源设置限额,当前可以设置限额的源有CPU和memory两种。其中CPU的资源单位为CPU的数量。
一般而言,一个CPU的配额已经算是相当大的一个资源配额,所以在k8s中,通常以千分之一的CPU配额为最小单位,以m来表示,通常一个容器的CPU配额为100-300m,即占用0.1-0.3个CPU。这个配额是个绝对值,不是占比。
在k8s中,一个计算资源进行配额限定需要设定两个参数:
requests,资源的最小申请量,系统必须满足要求
limits,资源最大允许使用的量。
五、label
一个label是一个key=value的键值组合,然后可以通过label selector(标签选择器)查询和筛选拥有某些label的资源对象。
label selector的重要使用场景:
kube-controller进程通过资源对象RC上定义的label selector来筛选要监控的pod的数量,从而实现全自动控制流程。
kube-proxy进程通过service的label selector来选择对应的pod,自动建立起每个service到对应pod的请求转发路由表。从而实现service的智能负载均衡机制。
六、RC
RC主要是为pod进行一些设定,包括副本数,label selector等。总结如下
- 在大多数情况下,我们通过定义一个RC实现pod的创建过程及副本数量的自动控制。
- RC里包括完整的Pod定义模板。
- RC通过label selector机制实现对pod副本的自动控制
- 通过改变RC的pod副本数量,可以实现pod的扩容或缩容
- 通过改变RC中Pod模板的镜像版本,可以实现Pod的滚动升级功能。
七、HPA(horizontal Pod Autoscaler)
通过手动执行kubectl scale命令,可以通过RC实现pod扩容。但并不满足谷歌对k8s的定位模板-自动化。
HPA,pod横向自动扩容,实现原理是通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地挑战目标pod的副本数。
有两种方式作为pod负载的度量指标。
-
CPU utilization percentage
-
应用程序自定义的度量指标,比如服务在每秒内的相应的请求数。
CPU utilization percentage是一个算术平均值,目标pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU使用量除以它的Pod request的值。比如当我们定义一个Pod的pod request为0.4,而当前pod的cpu使用量为0.2,则使用率为50%。如此可以得出一个平均值,如果某一个时刻CPU utilization percentage超过80%,则表示当前副本数不够,需要进行扩容。
CPU utilization percentage计算过程使用到的Pod的CPU使用量通常是1分钟的平均值。
八、service
service就是一个微服务,如下图所示:
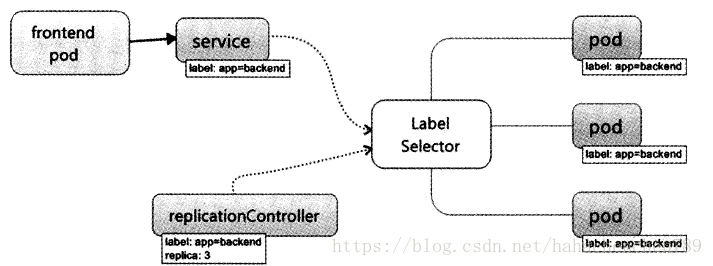
RC的作用实际上是保证service的服务能力和服务质量始终处于预期的标准。
而通过建模系统中的所有服务为微服务-k8s service,最终我们的系统由多个提供不同业务能力而又彼此独立的微服务单元所组成。服务之间通过TCP/IP通信,从而形成强大又灵活的弹性网络,拥有强大的分布式能力,弹性拓展negligence,容错能力等。如下图所示:
每个pod会被分配一个独立的IP地址,也就是每个pod都提供一个独立的endpoint(IP+port)以被访问,那多个pod如何被客户端访问呢,k8s通过运行在每个Node上的kube-proxy进程,负责将对service的请求转发到后端某个pod实例上,也就实现了类似负载均衡器的功能,至于具体转发到哪个pod,则由负载均衡器的算法所决定。
并且service不是共用一个负载均衡器的IP地址,而是每一个service分配了一个全局唯一的虚拟IP,cluster IP,这样每个服务就变成了具有唯一IP的通信节点,服务调用也就变成了最为基础的TCP通信问题。
我们知道,pod的endpoint的地址会随着pod的销毁和创建而改变。而service一旦创建,其cluster IP不会改变,服务发现问题得以解决,只要用service的name和其cluster IP做一个DNS即可。
k8s的服务发现机制
每个service都有一个唯一的cluster IP以及唯一的名字,而名字是由开发者自己定义的,部署的时候也没必要改变,所以完全可以固定在配置中,接下来的问题就是如何通过service的名字找到对应的cluster IP。
最早的时候k8s采用了Linux环境变量的方式解决这个问题,即env,并在每个pod的容器启动时,自动注入这些环境变量。
考虑到环境变量的方式获取service的IP与端口的方式仍然不太方便,不够直观,后来k8s通过add-on增值包的方式引入了DNS系统。
外部系统访问service的问题
k8s中有三种IP
a,Node IP:node节点的IP地址
b,Pod IP:pod的IP地址
c,cluster IP:service IP
首先,Node IP是k8s集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能直接通信,不管属不属于k8s集群。这也表明了k8s集群之外的节点访问k8s集群之内的某个节点后者TCP/IP服务的时候,必须要通过Node IP通信。
其次,pod IP是每个Pod的IP地址,它是docker根据docker网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,因此不同pod之间的通信就是通过Pod IP所在的虚拟二层网络进行通信的。而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
cluster IP是一个虚拟的IP,无法被ping,因为没有实体对象来响应。也就是说无法在集群外部直接使用这个地址,那么矛盾来了:
实际业务中肯定多少有一部分服务是要提供给k8s外部应用来使用的,典型的就是web端的服务模块,比如tomcat-service,那么用户怎么访问它呢?
采用NodePort是最常见的做法,也就是新的端口。
九、Volume 存储卷
Volume是pod中能够被多个容器访问的共同目录。也就是被定义在pod上,然后被一个pod中的多个容器挂载到具体的文件目录下,其次,volume与pod生命周期相同,但与容器生命周期不相关,当容器终止或重启,volume中的数据也不会丢失。
十、namespace
大多数情况下用于实现多租户的资源隔离,namespace通过将集群内部的资源对象分配到不同的namespace中,形成逻辑上分组的不同项目、小组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
namespace的定义很简单,如下所示的yaml定义了名为development的namespace
apiVersion: v1
kind: Namespace
metadata:
name: development
一旦创建了Namespace,我们在创建资源对象时就可以指定这个资源对象属于哪个namespace,比如下面,定义了名为busybox的Pod,放入development这个namespace里:
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: development
当我们给每个租户创建一个Namespace来实现多租户的资源隔离时,还能结合k8s的资源配额管理,限定不同租户能占用的资源,例如CPU,内存。