Redis集群的概念:
RedisCluster是redis的分布式解决方案,在3.0版本后推出的方案,有效地解决了Redis分布式的需求,当一个服务挂了可以快速的切换到另外一个服务,当遇到单机内存、并发等瓶颈时,可使用此方案来解决这些问题
一、分布式数据库概念
1. 分布式数据库把整个数据按分区规则映射到多个节点,即把数据划分到多个节点上,每个节点负责整体数据的一个子集。比如我们库有900条用户数据,有3个redis节点,将900条分成3份,分别存入到3个redis节点
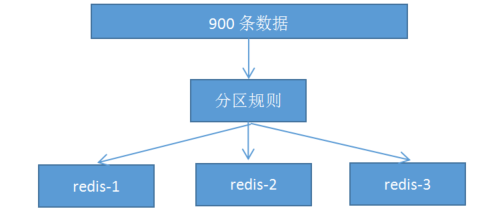
2. 分区规则:
常见的分区规则哈希分区和顺序分区,redis集群使用了哈希分区,顺序分区暂用不到,不做具体说明;
rediscluster采用了哈希分区的“虚拟槽分区”方式(哈希分区分节点取余、一致性哈希分区和虚拟槽分区),其它两种也不做介绍,有兴趣可以百度了解一下
3. 虚拟槽分区(槽:slot)
RedisCluster采用此分区,所有的键根据哈希函数(CRC16[key]&16383)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据
哈希函数: Hash()=CRC16[key]&16383 按位与
槽与节点的关系如下
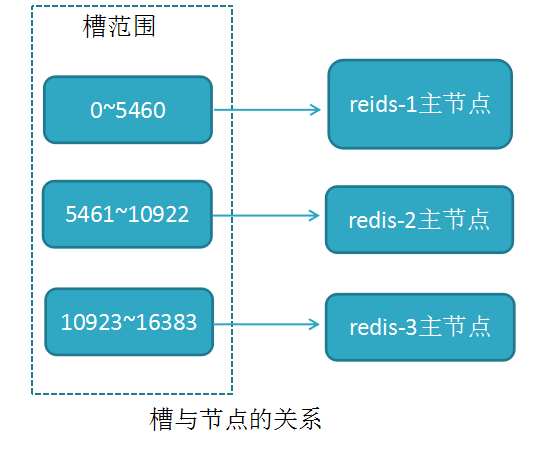
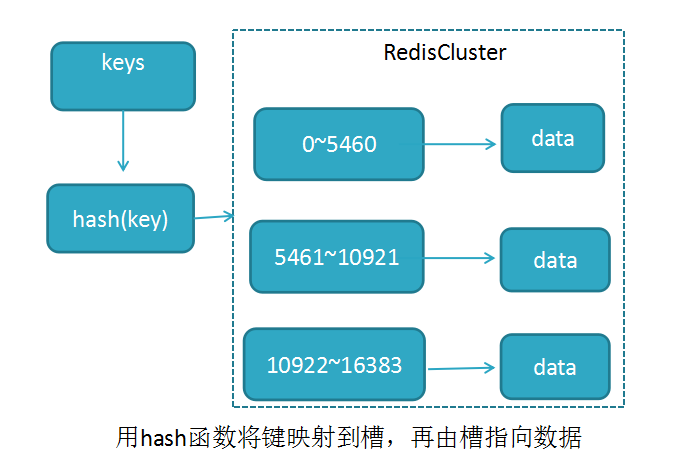
redis用虚拟槽分区原因:解耦数据与节点关系,节点自身维护槽映射关系,分布式存储
4. redisCluster的特点:



5. redisCluster的缺陷:
a,键的批量操作支持有限,比如mset, mget,如果多个键映射在不同的槽,就不支持了
b,键事务支持有限,当多个key分布在不同节点时无法使用事务,同一节点是支持事务
c,键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点
d,不支持多数据库,只有0,select 0
e,复制结构只支持单层结构,不支持树型结构。
二、集群环境搭建
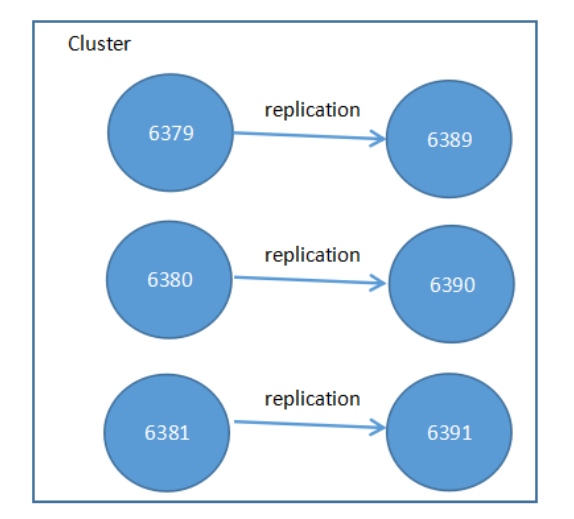
部署结构图:6389为6379的从节点,6390为6380的从节点,6391为6381的从节点
1./opt目录下,下载redis5.0.9版本
yum install gcc-c++
yum install -y gcc make
cd /opt
wget http://download.redis.io/releases/redis-5.0.9.tar.gz tar -zxf redis-5.0.9.tar.gz
cd redis-5.0.9/
make
1.在/opt目录下将下载的redis复制5份,以作集群使用
2. 分别修改6379、 6380、 6381、 6389、 6390、 6391配置文件
以6379的配置为例(修改红色部分),数据存储默认dir ./,会造成存储位置不固定,最好修改成自己的路径:
#bind 127.0.0.1
protected-mode no port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 300 daemonize yes supervised no pidfile /var/run/redis.pid loglevel notice logfile "" databases 16 always-show-logo yes save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir /opt/redis-1/data/ slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no slave-lazy-flush no appendonly no appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes aof-use-rdb-preamble no lua-time-limit 5000 cluster-enabled yes slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-size -2 list-compress-depth 0 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes
其它节点的配置和这个一致,改端口即可
3. 配置完后,启动6个redis服务(启动前保证每个redis没有数据存在,如果有请删除,要不然会启动失败)
/opt/redis-1/src/redis-server /opt/redis-1/redis.conf
/opt/redis-2/src/redis-server /opt/redis-2/redis.conf
/opt/redis-3/src/redis-server /opt/redis-3/redis.conf
/opt/redis-4/src/redis-server /opt/redis-4/redis.conf
/opt/redis-5/src/redis-server /opt/redis-5/redis.conf
/opt/redis-6/src/redis-server /opt/redis-6/redis.conf
4.防火墙开放端口,以6379为例
firewall-cmd --zone=public --add-port=6379/tcp --permanent systemctl stop firewalld.service systemctl start firewalld.service
此时远程就可以访问到我们的redis了,下面就是构建集群。
5.构建集群
这个版本支持集群,不需要安装ruby和gem
进入其中一个redis的src目录
cd /opt/redis-1/src
./redis-cli --cluster create 192.168.222.157:6379 192.168.222.157:6380 192.168.222.157:6381 192.168.222.157:6389 192.168.222.157:6390 192.168.222.157:6391 --cluster-replicas 1
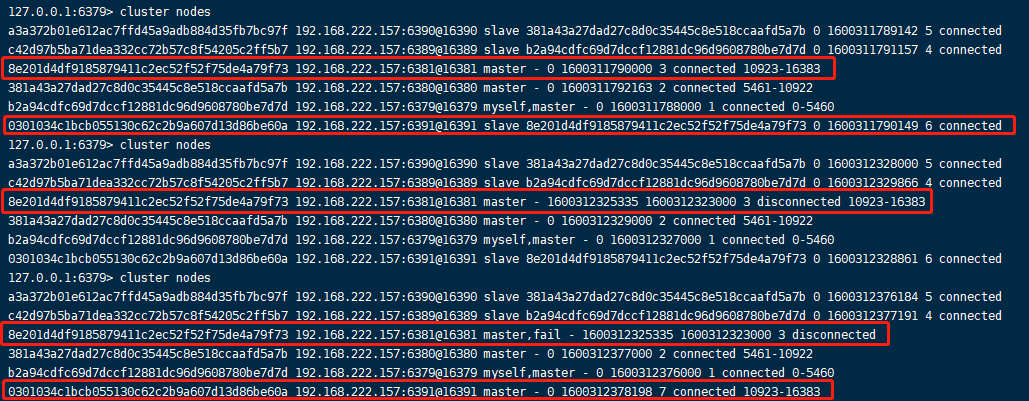
我们可以使用cluster info和cluster nodes查看集群情况(要在客户端下使用 redis-cli -c -p port)
cluster info
cluster nodes
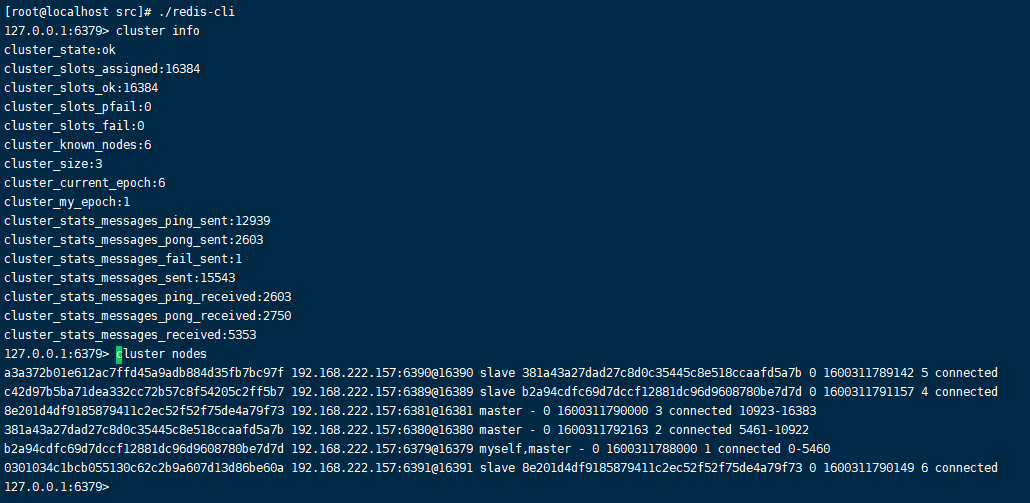
集群中的节点数目和主从关系和我们开头预期的是一致的。
至此集群构建成功!
6.编程测试集群
引入redis的依赖
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 如果使用Lettuce作为连接池,需要引入commons-pool2包,否则会报错bean注入失败 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- Jedis 客户端 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
yml添加redis配置
redis: timeout: 6000 # 连接超时时间(毫秒)默认是2000ms lettuce: pool: max-active: 200 # 连接池最大连接数(使用负值表示没有限制) max-wait: -1ms # 连接池最大阻塞等待时间(使用负值表示没有限制) max-idle: 100 # 连接池中的最大空闲连接 min-idle: 50 # 连接池中的最小空闲连接 shutdown-timeout: 500 cluster: #集群模式 nodes: - 192.168.222.157:6379 - 192.168.222.157:6380 - 192.168.222.157:6381 - 192.168.222.157:6389 - 192.168.222.157:6390 - 192.168.222.157:6391 max-redirects: 3 # 获取失败 最大重定向次数
向redis写100条数据
@Slf4j @RunWith(SpringRunner.class) @SpringBootTest public class ShaobingApplicationTests { @Resource private RedisTemplate redisTemplate; @Test public void testStringRedisTemplate() throws InterruptedException { for (int i = 0; i < 100; i++) { redisTemplate.opsForValue().set(String.valueOf(i + 1), i + 1); } } }
看下存储效果
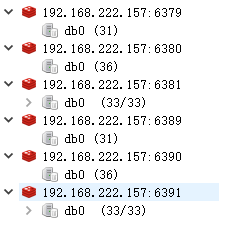
可以看出100条数据均匀分布在3个节点上,每个节点主从也是保持一致
7.redis服务操作命令

systemctl start redis.service #启动redis服务 systemctl stop redis.service #停止redis服务 systemctl restart redis.service #重新启动服务 systemctl status redis.service #查看服务当前状态 systemctl enable redis.service #设置开机自启动 systemctl disable redis.service #停止开机自启动
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
节点
cluster meet <ip> <port> :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽(slot)
cluster addslots <slot> [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。
cluster delslots <slot> [slot ...] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot <slot> node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
键
cluster keyslot <key> :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot <slot> :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot <slot> <count> :返回 count 个 slot 槽中的键