在慕课网看了正则表达式和requests的课程后,为了加深学习记忆,决定简单记录。
实现步骤:
1、先打开你要下载的网页,查看源码找出图片位置
2、编写正则匹配图片url
3、保存图片到本地
图文步骤:
1、以图虫网为例(https://tuchong.com/),随便点进去个主题(https://mrpig.tuchong.com/14390318/)
定位图片

2、写出正则
通过观察可以发现图片url是以 // 开头以 .jpg结尾的
则正则表达式为 “//.+.jpg”
1 import requests 2 import re 3 4 url='https://mrpig.tuchong.com/14390318/' 5 response = requests.get(url) 6 url_lst = re.findall(r"//.+.jpg",response.text) 7 print url_lst
输出
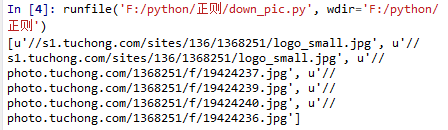
通过拷贝到浏览器,发现前面两个图片不是我们感兴趣的,则把他们切掉 [2:]
3、最后使用一个遍历,将图片保存到本地。
完整代码:
1 import requests 2 import re 3 4 url='https://mrpig.tuchong.com/14390318/' 5 response = requests.get(url) 6 url_lst = re.findall(r"//.+.jpg",response.text)[2:] 7 i=0 8 for url in url_lst: 9 with open(str(i)+".jpg","wb") as fd: 10 #在url前面加上http 11 response=requests.get("http:"+url) 12 fd.write(response.content) 13 print '图片',i,"保存成功 " 14 i+=1