从2017年11月9号起,总结面试所遇到的问题。
1.问:数据库中左联和右联的区别
答:
左联: 首先取出a表中所有数据,然后再加上与a,b匹配的的数据,b中没有的数据为null
内联:两个表a,b相连接,要取出id相同的字段
右联:指的是首先取出b表中所有数据,然后再加上与a,b匹配的的数据,a中没有的数据为null
假如有student表和result表,

左联:SELECT * FROM student s LEFT JOIN result r ON s.id=r.student_id,
结果: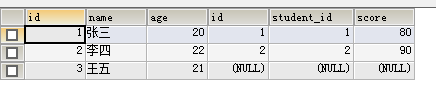
右联:SELECT * FROM student s RIGHT JOIN result r ON s.id=r.student_id,
结果:
内联:SELECT * FROM student s INNER JOIN result r ON s.id=r.student_id,
结果:
2.spring的核心是什么?
答:
一、 Spring框架的核心组件有三个:Core、Context、Beans。其中最核心的组件就是Beans,最核心的功能就是BeanFactory。
二、Spring解决了的最核心的问题:把对象之间的依赖关系转为用配置文件来管理,也就是Spring的依赖注入机制。这个注入机制是在IOC容器中进行管理的。
三、Bean 组件是在 Spring 的 org.springframework.beans 包下。这个包主要解决了如下功能:Bean 的定义、Bean 的创建以及对 Bean 的解析。对 Spring 的使用者来说唯一需要关心的就是 Bean 的创建,其他两 个由 Spring 内部机制完成。Bean 的定义就是完整的描述了在 Spring 的配置文件中你定义的 <bean/> 节点中所有的信息,包括各种子节点。当 Spring 成功解析你定义的一个 <bean/> 节点后,在 Spring 的内部他就被转化成 BeanDefinition 对象。以后所有的操作都是对这个对象完成的。Bean 的解析过程非常复杂,功能被分的很细,因为这里需要被扩展的地方很多,必须保证有足够的灵活性,以应对可能的变化。Bean 的解析主要就是对 Spring 配置文件的解析。SpringBean的创建采用典型的工厂模式,他们的顶级接口BeanFactory。
四、Spring主要核心是:
- 控制反转(IOC):在以前传统的Java开发模式中,当需要一个对象时我们,我们会自己使用new或者getInstance等直接或者间接调用构造方法创建一个对象,而在Spring开发模式中,Spring容器使用工厂模式为我们创建了所需要的对象,我们使用时不需要自己去创建,直接调用Spring为我们提供的对象即可,这就是控制反转的思想。实例化一个Java对象有三种方式:使用类构造器,使用静态工厂方法,使用实例工厂方法。当使用Spring时我们就不需要关心通过何种方式实例化一个对象,Spring通过控制反转机制自动为我们实例化一个对象。
- 依赖注入(DI):Spring使用JavaBean对象的Set方法或者带参数的构造方法为我们在创建所需对象时将其属性自动设置所需要的值的过程就是依赖注入的基本思想。
- 面向切面编程(AOP):在面向对象编程(OOP)思想中,我们将事物纵向抽象成一个个的对象。而在面向切面编程中,我们将一个个对象某些类似的方面横向抽象成一个切面,对这个切面进行一些如权限验证,事物管理,记录日志等公用操作处理的过程就是面向切面编程的思想。
五、使用Spring的目的:就是让对象与对象或者模块与模块之间的关系没有通过代码关联,都是通过配置类说明管理的(Spring根据这些配置内部通过反射去动态的组装对象)。
3.问:struts2的核心是什么?
答:
Struts 2框架由3个部分组成:核心控制器FilterDispatcher、业务控制器和用户实现的业务逻辑组件。在这3个部分里,Struts 2框架提供了核心控制器FilterDispatcher,而用户需要实现业务控制器和业务逻辑组件.
其中主要核心是:核心控制器:FilterDispatcher ,该控制器作为一个Filter运行在Web应用中,它负责拦截所有的用户请求,当用户请求到达时,该Filter会过滤用户请求。如果用户请求以action结尾,该请求将被转入Struts 2框架处理。
工作原理:
1.客户端初始化一个指向Servlet容器(例如Tomcat)的请求
2.这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过滤器对于Struts2和其他框架的集成很有帮助,例如:SiteMesh Plugin)
3.接着FilterDispatcher被调用,FilterDispatcher询问ActionMapper来决定这个请是否需要调用某个Action
4.如果ActionMapper决定需要调用某个Action,FilterDispatcher把请求的处理交给ActionProxy
5.ActionProxy通过Configuration Manager询问框架的配置文件,找到需要调用的Action类
6.ActionProxy创建一个ActionInvocation的实例。
7.ActionInvocation实例使用命名模式来调用,在调用Action的过程前后,涉及到相关拦截器(Intercepter)的调用。
8.一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果。返回结果通常是(但不总是,也可 能是另外的一个Action链)一个需要被表示的JSP或者FreeMarker的模版。在表示的过程中可以使用Struts2 框架中继承的标签。在这个过程中需要涉及到ActionMapper
工作流程:
1.客户端浏览器发出HTTP请求.
2.根据web.xml配置,该请求被FilterDispatcher接收
3.根据struts.xml配置,找到需要调用的Action类和方法, 并通过IoC方式,将值注入给Aciton
4.Action调用业务逻辑组件处理业务逻辑,这一步包含表单验证。
5.Action执行完毕,根据struts.xml中的配置找到对应的返回结果result,并跳转到相应页面
6.返回HTTP响应到客户端浏览器。
具体步骤:
1.当用户请求到达时,该Filter会过滤用户请求。如果用户请求以action结尾,该请求将被转入Struts 2框架处理。
2.Struts 2框架获得了*.action请求后,将根据*.action请求的前面部分决定调用哪个业务逻辑组件,例如,对于login.action请求,Struts 2调用名为login的Action来处理该请求。
3.Struts 2应用中的Action都被定义在struts.xml文件中,在该文件中定义Action时,定义了该Action的name属性和class属性,其中name属性决定了该Action处理哪个用户请求,而class属性决定了该Action的实现类。
4.Struts 2用于处理用户请求的Action实例,并不是用户实现的业务控制器,而是Action代理——因为用户实现的业务控制器并没有与Servlet API耦合,显然无法处理用户请求。而Struts 2框架提供了系列拦截器,该系列拦截器负责将HttpServletRequest请求中的请求参数解析出来,传入到Action中,并回调Action 的execute方法来处理用户请求。
4.问:什么是依赖注入?
答:
Spring 能有效地组织J2EE应用各层的对象。不管是控制层的Action对象,还是业务层的Service对象,还是持久层的DAO对象,都可在Spring的 管理下有机地协调、运行。Spring将各层的对象以松耦合的方式组织在一起,Action对象无须关心Service对象的具体实现,Service对 象无须关心持久层对象的具体实现,各层对象的调用完全面向接口。当系统需要重构时,代码的改写量将大大减少。
上面所说的一切都得宜于Spring的核心机制,依赖注入。依赖注入让bean与bean之间以配置文件组织在一起,而不是以硬编码的方式耦合在一起。理解依赖注入
依赖注入(Dependency Injection)和控制反转(Inversion of Control)是同一个概念。具体含义是:当某个角色(可能是一个Java实例,调用者)需要另一个角色(另一个Java实例,被调用者)的协助时,在 传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在Spring里,创建被调用者的工作不再由调用者来完成,因此称为控制反转;创建被调用者 实例的工作通常由Spring容器来完成,然后注入调用者,因此也称为依赖注入
5.问:&和&&区别?
答:
&和&&都是按位与运算符(and),&表示两边都是true是结果是true,&&表示只要前面的结果是true时,结果就是true,具有短路的效果。
1 public static void main(String[] args) { 2 int a = 80; 3 int b = 50; 4 int c = 90; 5 6 //结果是条件不满足! 7 if (a > 60 & b > 60) { 8 System.out.println("a:" + a + " b:" + b); 9 } else { 10 System.out.println("条件不满足!"); 11 } 12 13 //结果是a:80 c:90 14 if (a > 60 & c > 60) { 15 System.out.println("a:" + a + " c:" + c); 16 } else { 17 System.out.println("条件不满足!"); 18 } 19 20 21 //结果是a:80 c:90 22 if (a > 60 && c > 60) { 23 System.out.println("a:" + a + " c:" + c); 24 } else { 25 System.out.println("条件不满足!"); 26 } 27 28 //结果是条件不满足! 29 if (b > 60 && c > 60) { 30 System.out.println("b:" + b + " c:" + c); 31 } else { 32 System.out.println("条件不满足!"); 33 } 34 35 }
6.问:int和Integer的区别?
答:
int是8中基本数据类型之一,Integer是int的包装类,是一个类。
所以创建一个对象可以用:Integer a=new Integer(128)。
int的默认值是0,Integer的默认值是null。
Integer的存在是为了数据类型的转换,例如:
1 String str="123"; 2 int aa=Integer.parseInt(str);//将字符串参数作为有符号的十进制整数进行解析。 3 Integer bb=Integer.valueOf(str);//返回保存指定的 String 的值的 Integer 对象。 4 System.out.println(aa+123);//结果:246 5 System.out.println(bb+123);//结果:246
1 int a=128; 2 Integer b=128;//相当于int b= Integer.valueOf(128); 3 Integer c=128; 4 Integer b1=127; 5 Integer c1=127; 6 Integer d=new Integer(128); 7 Integer e=new Integer(128); 8 9 System.out.println(a==b);//true 10 System.out.println(b==c);//false 11 System.out.println(b1==c1);//true 12 System.out.println(a==d);//true 13 System.out.println(c==d);//false 14 System.out.println(d==e);//false
7.问:数据库中关于重复记录的问题
答:
1.去重
W3school中关于去重关键字distinct的简单介绍:http://www.w3school.com.cn/sql/sql_distinct.asp
2.查询重复的记录
| id | name | age |
| 1 | 张三 | 20 |
| 2 | 李四 | 22 |
| 3 | 王五 | 21 |
| id | student_id | score |
| 1 | 1 | 80 |
| 2 | 2 | 90 |
| 3 | 5 | 80 |
| 4 | 2 | 60 |
| 5 | 2 | 40 |
| 6 | 1 | 88 |
单表查询:
SELECT * FROM result WHERE student_id IN (SELECT student_id FROM result GROUP BY student_id HAVING COUNT(student_id)>1)
结果:
| id | student_id | score |
| 1 | 1 | 80 |
| 2 | 2 | 90 |
| 4 | 2 | 60 |
| 5 | 2 | 40 |
| 6 | 1 | 88 |
联表查询:
SELECT s.name,r.score FROM result r INNER JOIN student s ON s.id=r.student_id WHERE student_id IN (SELECT student_id FROM result GROUP BY student_id HAVING COUNT(student_id)>1) ORDER BY s.name
结果:
| name | score |
| 张三 | 80 |
| 张三 | 88 |
| 李四 | 90 |
| 李四 | 60 |
| 李四 | 40 |
更多方法点击:http://www.jb51.net/article/34820.htm