在面试后台开发的过程中,集合是面试的热话题,不仅要知道各集合的区别用法,还要知道集合的扩容机制,今天我们就来谈下ArrayList 和 HashMap的默认大小以及扩容机制。
在 Java 7 中,查看源码可以知道:ArrayList 的默认大小是 10 个元素,HashMap 的默认大小是16个元素(必须是2的幂,为什么呢???下文有解释)。这就是 Java 7 中 ArrayList 和 HashMap 类 的代码片段:
// from ArrayList.java JDK 1.7 private static final int DEFAULT_CAPACITY = 10; //from HashMap.java JDK 7 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
这里要讨论这些常用的默认初始容量和扩容的原因是:
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上,
这无疑使效率大大降低。加载因子的系数小于等于1,意指即当元素个数超过容量长度*加载因子的系数时,进行扩容。另外,扩容也是有默认的倍数的,不同的容器扩容情况不同。
List 元素是有序的、可重复
ArrayList、Vector默认初始容量为10
Vector:线程安全,但速度慢
底层数据结构是数组结构
加载因子为1:即当 元素个数 超过 容量长度 时,进行扩容
扩容增量:原容量的 1倍
如 Vector的容量为10,一次扩容后是容量为20
ArrayList:线程不安全,查询速度快
底层数据结构是数组结构
扩容增量:原容量的 0.5倍+1
如 ArrayList的容量为10,一次扩容后是容量为16
Set(集) 元素无序的、不可重复。
HashSet:线程不安全,存取速度快
底层实现是一个HashMap(保存数据),实现Set接口
默认初始容量为16(为何是16,见下方对HashMap的描述)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
Map是一个双列集合
HashMap:默认初始容量为16
(为何是16:16是2^4,可以提高查询效率,另外,32=16<<1)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
接下来我们来谈谈hashMap的数组长度为什么保持2的次幂?
hashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。
这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了
之前已经散列良好的老数组的数据位置重新调换),还有,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀。
1. static int indexFor(int h, int length) { 2. return h & (length-1); 3. }
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,
为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同
一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的
值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组
长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
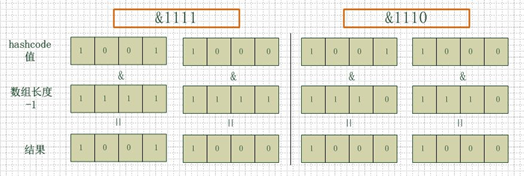
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,
在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。