用户端请求步骤:DNS解析URL地址、生成HTTP请求报文、构建TCP连接、使用IP协议选择传输路线、数据链路层保证数据的可靠传输、物理层将数据转换成电子、光学或微波信号进行传输
网络传输: 从客户机到服务器需要通过许多网络设备, 一般地,包括集线器、交换器、路由器等

服务器处理及反向传输:
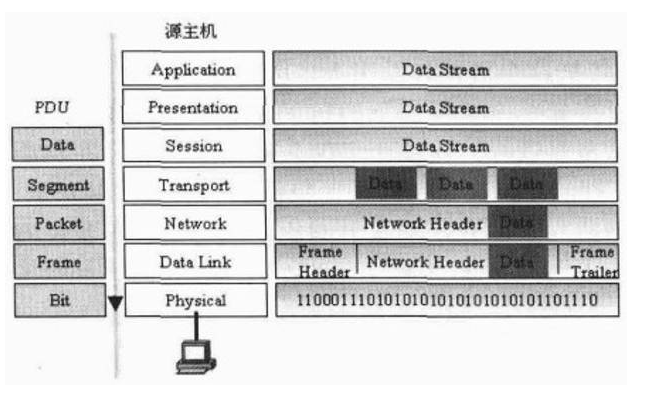
服务器接收到这个比特流,把比特流转换成帧格式,上传到数据链路层,服务器发现数据帧中的目的MAC地址与本网卡的MAC地址相同,服务器拆除数据链路层的封装后,把数据包上传到网络层。服务器的网络层比较数据包中的目的IP地址,发现与本机的IP地址相同,服务器拆除网络层的封装后,把数据分段上传到传输层。传输层对数据分段进行确认、排序、重组,确保数据传输的可靠性。数据最后被传到服务器的应用层
HTTP服务器,如nginx通过反向代理,将其定位到服务器实际的端口位置,如8080。比如,8080端口对应的是一个NodeJS服务,生成响应报文,报文主体内容是google首页的HTML页面
接着,通过传输层、网络层、数据链路层的层层封装,最终将响应报文封装成二进制比特流,并转换成其他信号,如电信号到网络中传输
反向传输的过程与正向传输的过程类似,就不再赘述
浏览器渲染:
客户机接受到二进制比特流之后,把比特流转换成帧格式,上传到数据链路层,客户机发现数据帧中的目的MAC地址与本网卡的MAC地址相同,拆除数据链路层的封装后,把数据包上传到网络层。网络层比较数据包中的目的IP地址,发现与本机的IP地址相同,拆除网络层的封装后,把数据分段上传到传输层。传输层对数据分段进行确认、排序、重组,确保数据传输的可靠性。数据最后被传到应用层
1、如果HTTP响应报文是301或302重定向,则浏览器会相应头中的location再次发送请求
2、浏览器处理HTTP响应报文中的主体内容,首先使用loader模块加载相应的资源
loader模块有两条资源加载路径:主资源加载路径和派生资源加载路径。主资源即google主页的index.html文件 ,派生资源即index.html文件中用到的资源
主资源到达后,浏览器的Parser模块解析主资源的内容,生成派生资源对应的DOM结构,然后根据需求触发派生资源的加载流程。比如,在解析过程中,如果遇到img的起始标签,会创建相应的image元素HTMLImageElement,接着依据img标签的内容设置HTMLImageElement的属性。在设置src属性时,会触发图片资源加载,发起加载资源请求
这里常见的优化点是对派生资源使用缓存