基本过程图:
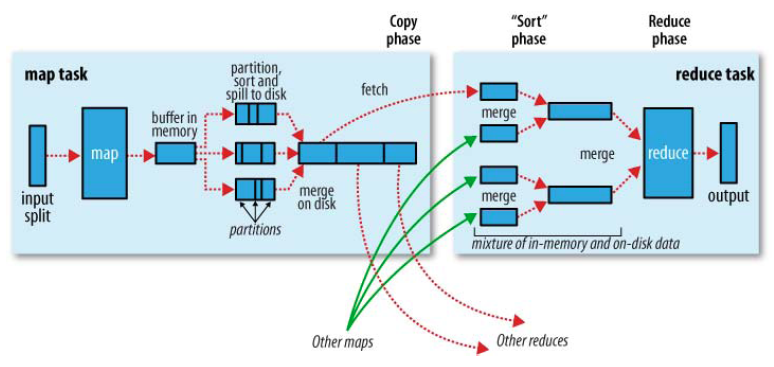
详细过程图:
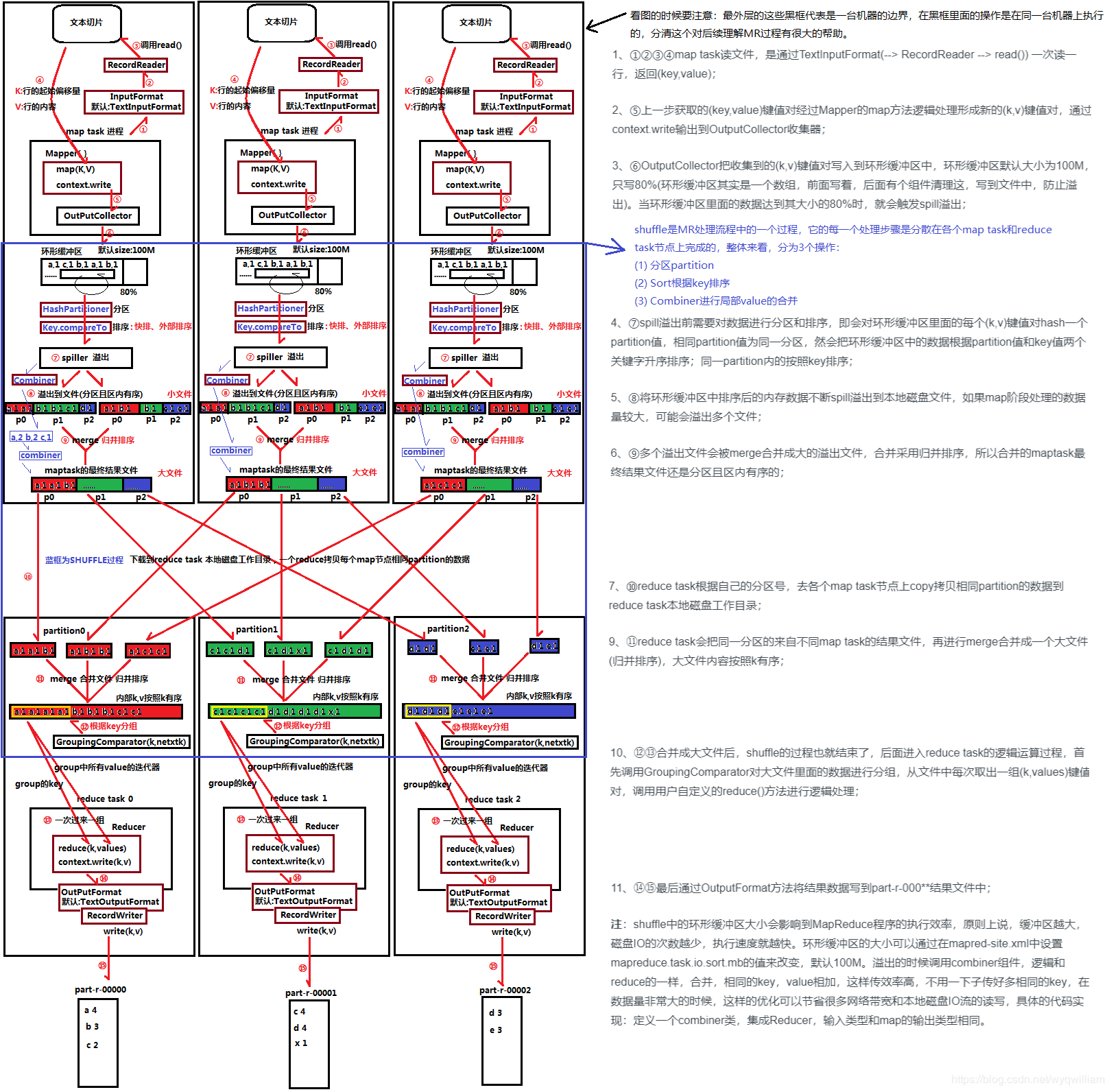
简单流程:
Clinet ->request ResourceManager -> get Resource -> Job start ->InputFormat->Write InputSplit->Split[0...M]-> Mapper get split[M]-> ->MapWorkers[]->loop the split -> <K,V> records->map()
map()-> (K,V) -> p=hash(K)%NumOfReducr ->write to buffer memory(100M)-> spill when 80%loaded =>sort by p=> Part[0...R] =>sort by K ->write to spill file recycle->spill untill file drain->combine when spill file Num great than setting -> mertge spill file-> Part[0...R]
Part[R] copy to->
ReducersWorkers ->merge the Part[x] from variety mapper workers by sort->read file-> (K,V...) ->reduce()->(file,part-r-00000)
工作流程:
(1) 最先开始工作的是Mapper,Mapper从InputSplit取得一个数据分片,逐行读入数据记录(分隔符可自定义,默认为换行符),数据为键值对形式,K为行号(字符偏移量),V为这一行的文本。
(数据分片的大小默认就是HDFS文件块的大小,且Mapper分配的分片一般就是本计算机上的Block)
(3) 当缓冲区达到阈值(80%)或文件读完时发生数据spill溢出,溢出指将数据写入磁盘。关于spill的过程有两种说法(弄不清):
- 其一认为:进行两重排序,一重排序是按P分区号排序,二重排序是在一重的基础上在各分区内按照K值进行排序,然后一轮遍历按Partition分段输出数据到文件。
- 其二认为:对缓冲区的数据按照K值进行排序,然后多轮遍历排序后的数据,每轮遍历输出一个partition段的数据到文件。
但不论是两次排序还是一次,最终生成的文件结构是一样。生成的文件按P值分段,每个partition段的又有一个索引,索引存储在一个三元组中,包括起始位置、数据长度、压缩后的数据长度。
(阈值设置为80%是为了使缓冲区在写出(清理)数据时,map函数同时还能写)
(4) 多次spill将会产生多个分段(区)且段内按key值有序的spill文件,当map彻底完成后,将会对这个文件进行合并,合并文件采用分区归并快排的方式,最终产生一个大文件。
(这个大文件的结构与spill溢出的文件结构基本相同,也有一个三元组索引)
(如果定义了combine函数会在合并时发生聚合,但只有spill文件数目达到设定值才会运行)
(5) Reducer在Map完成后受到ApplicationMaster的通知开始工作,首先会向各个Mapper发送Http请求,下载对应的分区内的数据,并合并来自各个Mapper的文件,合并方式也是按key值进行归并排序。
(归并排序时会发生分组,默认是按照key值进行分组,分组生成了每个key的values表)
(6) Reducer依次对每个key值及其values表调用reduce函数,函数将按key值逐行输出结果,此处输出到也会先输出到环形缓冲区,处理完成后合并文件。
(每个Reducer都会产生一个文件,一般不会再进行合并)
环形缓冲区:环型数组,一个赤道变量,向上(正)是数据存储的方向,向下是元数据存储的方向。
详情见: