今天早上帮同事写了脚本,大致功能:从文本中读取域名,加密存储成按照自己定义的格式。但是一个简单的代码居然出现了错误。初始的代码如下:
# coding:utf-8
import hashlib
import base64
# 使用MD5加密字符串
def entry_md5(text):
md5_object = hashlib.md5()
md5_object.update(text)
test = md5_object.hexdigest().upper()
return test
def write_file(url, entry_code):
# 前五位
code = '[{}]'.format(entry_code)
# url加密
ob = 'v={}|t=w|a=k|'.format(url)
encode = base64.b64encode(ob)
final_code = 'object="{}"'.format(encode)
with open('3.txt', 'a+') as f:
f.writelines(code + '
' + final_code + '
')
with open('2.txt', 'r') as f:
for line in f.readlines():
line = line.strip()
line = line.lstrip()
url_domain = line.split('.')
if len(url_domain) > 2:
fin_domain = url_domain[1]
else:
fin_domain = url_domain[0]
text2 = entry_md5(line.strip())
# 获取前五位数字
text3 = entry_md5(text2)
text4 = text3[0:5]
write_file(fin_domain, text4)
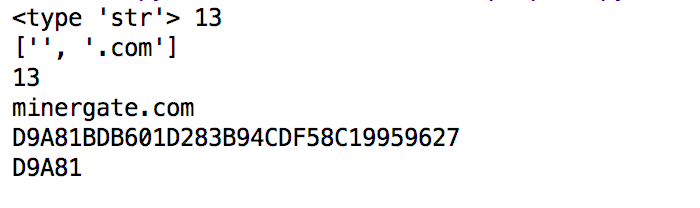
但是在同事那边验证失败了。起始文件我是用set(list)一个列表。但是在minergate这里出错了。通过对line输出
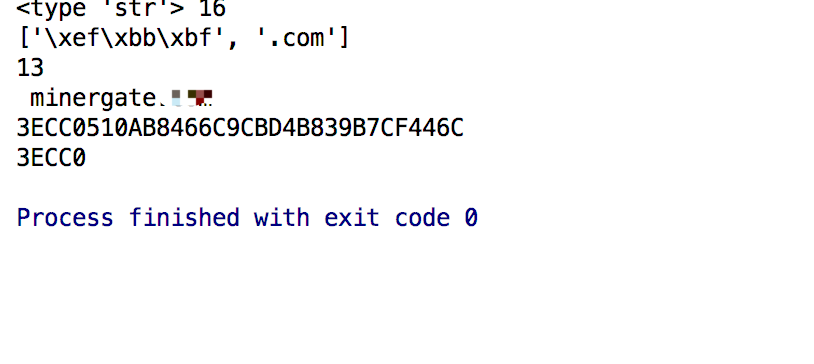
其中我已经对line两边去掉空格,结果在结果集中还是出现空格。一番折腾后,发现我在起始文件minergrate处于头部,会加入utf8编码。需要把编码去掉。
# coding:utf-8
import hashlib
import base64
import codecs
# 使用MD5加密字符串
def entry_md5(text):
md5_object = hashlib.md5()
md5_object.update(text)
test = md5_object.hexdigest().upper()
return test
def write_file(url, entry_code):
# 前五位
code = '[{}]'.format(entry_code)
# url加密
ob = 'v={}|t=w|a=k|'.format(url)
encode = base64.b64encode(ob)
final_code = 'object="{}"'.format(encode)
with open('3.txt', 'a+') as f:
f.writelines(code + '
' + final_code + '
')
with open('2.txt', 'r') as f:
for line in f.readlines():
line = line.strip()
line = line.lstrip()
line = line.replace(codecs.BOM_UTF8, '')
url_domain = line.split('.')
if len(url_domain) > 2:
fin_domain = url_domain[1]
else:
fin_domain = url_domain[0]
text2 = entry_md5(line.strip())
# 获取前五位数字
if 'minergate' in line:
print type(line), len(line)
print line.split('minergate')
print len('minergate.com')
print line
text3 = entry_md5(text2)
print(text3)
text4 = text3[0:5]
print(text4)
#write_file(fin_domain, text4)
最终我们看到结果输出正常了。