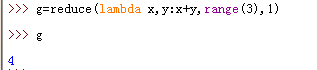一 、推导式:
是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列的结构体。 共有三种推导,在Python2和3中都有支持:
- 列表(list)推导式(或称:列表表达式)
- 字典(dict)推导式
- 集合(set)推导式
1、列表推导式 (使用[]生成list):
基本格式
variable = [out_exp_res for out_exp in input_list if out_exp == 2] out_exp_res: 列表生成元素表达式,也可以是有返回值的函数。 for out_exp in input_list: 迭代input_list将out_exp传入out_exp_res表达式中。 if out_exp == 2: 根据条件过滤哪些值可以。此条件可以不加
例一:
multiples = [i for i in range(30) if i % 3 is 0] print(multiples) # Output: [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
例二: 有返回值的函数
def squared(x):
return x*x
multiples = [squared(i) for i in range(30) if i % 3 is 0]
print multiples
# Output: [0, 9, 36, 81, 144, 225, 324, 441, 576, 729]
2、字典推导式 (使用{}生成dict):
字典推导式和列表推导式类似,只是[]换成{}。
例一:快速更换key和value
mcase = {'a': 10, 'b': 34}
mcase_frequency = {v: k for k, v in mcase.items()} # “for k,v in mcase.items()” 用到python元组拆包
print mcase_frequency
# Output: {10: 'a', 34: 'b'}
例二:大小写key合并

mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys() if k.lower() in ['a','b']}
print mcase_frequency
# Output: {'a': 17, 'b': 34}
3、集合推导式
例一:
squared = {x**2 for x in [1, 1, 2]}
print(squared)
# Output: {1, 4} python3
# Output: set([1, 4]) python2
二、生成器表达式:
生成器表达式和列表推导式类似,只是把[ ] 换成了( ) 。
 生成器表达式
生成器表达式
 列表推导式
列表推导式
 生成器表达式可迭代
生成器表达式可迭代
生成器表达式得到的是一个generator,而列表推导式生成的是一个list,generator是一个生成器对象,可迭代。生成generator的时候,不会在内存中留下一个列表,而在每次for循环运行时才生成一个组合,生成器对象是用到的时候才生成内容的,当数据比较大的时候,生成器表达式能明显的节约内存。
生成器表达式属于“惰性计算”,可以逐个的获取内容:
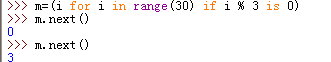 python2中可用generator.next()逐个获取
python2中可用generator.next()逐个获取
 python3中逐个获取用法改成next(generator)
python3中逐个获取用法改成next(generator)
三、生成器表达式可替换map、filter高阶函数
filter:
g=(i for i in range(30) if i % 3 is 0) 等效于 g=filter(lambda x:x%3==0,range(30))
map:
g=(i+2 for i in range(10) ) 等效于 g=map(lambda x:x+2,range(10))
reduce (生成的是一个结果,不是generator)
reduce(function, sequence[, initial]) -> value
function参数是一个有两个参数的函数,reduce依次从sequence中取一个元素,和上一次调用function的结果做参数再次调用function。
第一次调用function时,如果提供initial参数,会以sequence中的第一个元素和initial作为参数调用function,否则会以序列sequence中的前两个元素做参数调用function。
 python3中 reduce()函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里
python3中 reduce()函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里