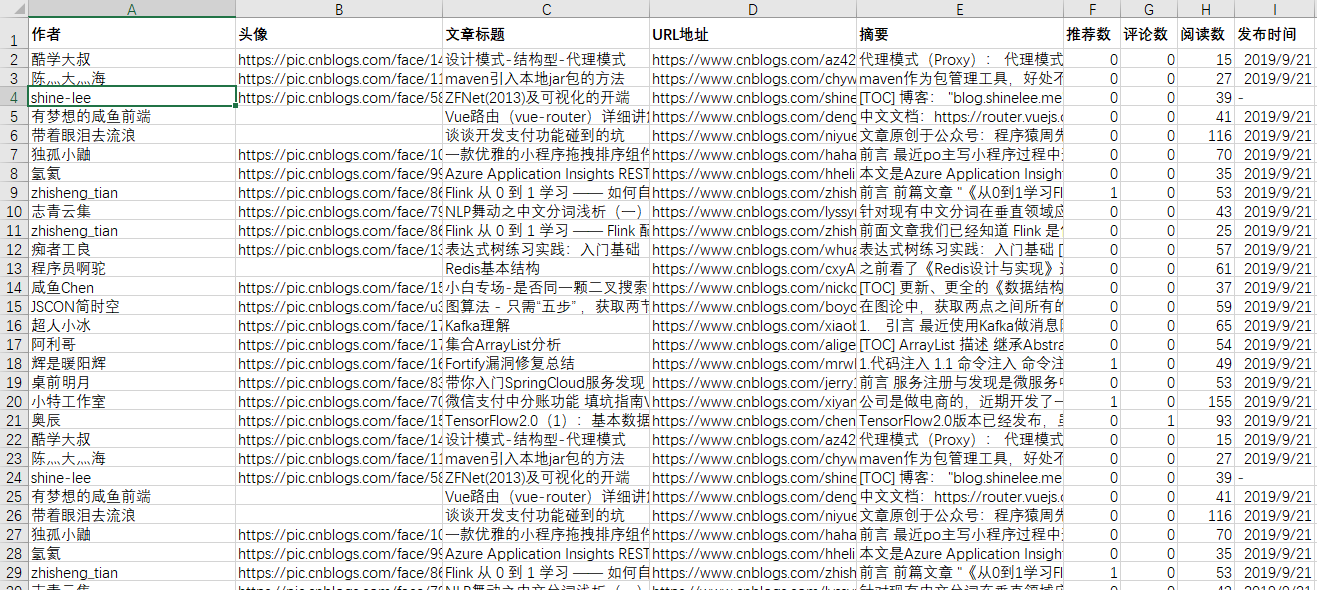
爬虫主要抓取首页文档列表中的信息如:作者、头像、文章标题、摘要、发布时间、推荐次数、评论次数、阅读次数。 采用协程方式进行抓取页面,然后把信息保存到"博客园.csv"文件中。
采用了 第三方库 aiohttp、beautifulsoup4
如图:
部分代码
import csv import asyncio from httprequest import Http from blogs import Blogs ''' 生成采集列表 ''' def create_url_list(s, e): items = [] for n in range(s, e): items.append('https://www.cnblogs.com/sitehome/p/%s' % n) return items ''' 异步 ''' async def async_task(urls: list): core = [Http.request(u) for u in urls] return await asyncio.gather(*core) ''' 采集 ''' urls = create_url_list(0, 20) result = asyncio.run(async_task(urls)) ''' 保存 ''' with open('博客园.csv', 'w', encoding='utf_8_sig', newline='') as f: fields = None ''' 写入信息 ''' for text in result: for t in Blogs(text).run(): if not fields: # 写入字段 fields = t.keys() w = csv.DictWriter(f, fields) w.writeheader() w.writerow(t) print('采集完成')
百度网盘下载:
链接:https://pan.baidu.com/s/1rb4O1ubSvXSIMi68yGv1gQ
提取码:x8ip