浅谈HashMap
基本特性
定义
hashMap是一个无序的,非空的容器,而且是非同步的容器会造成线程不安全的这类问题,即有许多人都想要同一份学习资料,系统会复制出多份资料后,给每个人一份资料,而不同的人对这份资料有着不同的看法并对该资料进行修改,再上传到系统中。可想而知资料会有多少个版本,但是系统只能存放一个版本的资料,因而会丢失大量版本信息。线程不安全:简单来说,就是用户读到的信息有一定可能是错误的,从而做出错误的操作(抢票时,可能抢到重票或抢到一张不存在的票)

历遍
HashMap的容量太大或太小,不利于literator(迭代器)查询目标。

HashMap的模型
HashMap是数组和单向列表的结合体,即用数组来装列表的表头,因此在做增删等操作时,所消耗的时间和空间会比数组小,查询容器的中元素的速度会比列表快。类似于下图
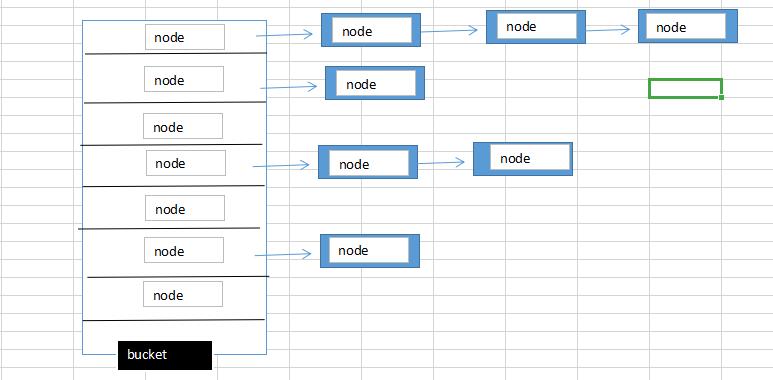
初始化
HashMash中常量:
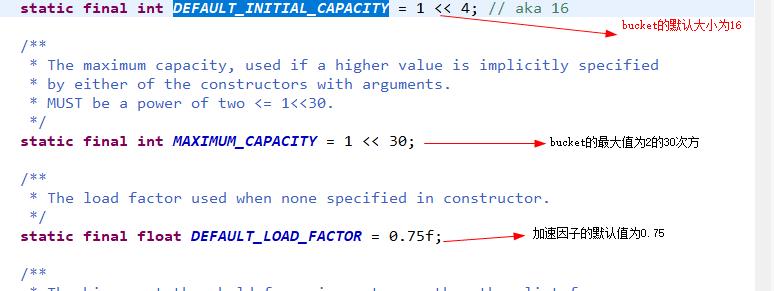

HashMap有4个构造函数;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; //使用默认的加速因子,bucket 的大小为默认的16
}
1 public HashMap(int initialCapacity, float loadFactor) {
2 //initialCapacity是bucket的大小,loadFactor是加速因子
3 if (initialCapacity < 0)
4 throw new IllegalArgumentException("Illegal initial capacity: " +
5 initialCapacity);
6 if (initialCapacity > MAXIMUM_CAPACITY)
7 initialCapacity = MAXIMUM_CAPACITY;//MAXIMUM_CAPACITY为2的30次方
8 if (loadFactor <= 0 || Float.isNaN(loadFactor))
9 throw new IllegalArgumentException("Illegal load factor: " +
10 loadFactor);
11 this.loadFactor = loadFactor;//将设置的加速因子赋给HashMap加速因子
12 this.threshold = tableSizeFor(initialCapacity);//计算bucket的大小
13 }
public HashMap(int initialCapacity) {
//只是设置了HashMap的bucket的大小,加速因子使用默认的
this(initialCapacity, DEFAULT_LOAD_FACTOR);//调用上述的构造函数
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;//将加速因子设为默认值
putMapEntries(m, false);//将Map中的所有值都存放到HashMap中
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {//判断m是否为空
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)//m的容量大于HashMap的界限值时就调用resize来扩容
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {//历遍m,将所有的元素放入hashMap中去
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
Get和Put方法
Get
简单来说,get方法的核心是通过key.hashcode&(bucket.size-1)来确定桶位,再历遍桶位中列表。
注意
一般来,key.hashcode是唯一且不变的。
key.hashcode&(bucket.size-1)和key.hashcode%(bucket.size-1)都能确桶位,但是前者进行的是位运算会比求余要快一些,而且解释了bucket的大小为什么是2的倍数(如果bucket的大小不是2的倍数,位运算的结果就不对,会造成hash表的混乱。)
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;//判断getNode函数返回值来判断是否存在该值
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first, e;
int n;
K k;
if ((tab = table) != null && (n = tab.length) > 0 &&//判断hashmap是否非空
(first = tab[(n - 1) & hash]) != null)//判断目标值的链表头是否非空
{
if (first.hash == hash && // 检查目标值是否和链表头是否相同
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//考虑到树结构的情况
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//历遍链表来查找目标值
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Put
简单来说,put方法的核心是通过key.hashcode&(bucket.size-1)来确定桶位,再历遍桶位中列表,找到合适的位置。
注意
在里边过程中,如果发现两个hashcode重复,hashmap一般会认为是一个值,就不会进行增加的操作。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//判断hashmap是否非空
n = (tab = resize()).length;//将扩容的hashmap的容量赋给n
if ((p = tab[i = (n - 1) & hash/*计算添加值的hashcode所在的链表头*/]) == null)//判断目标值的链表头是否非空
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//判断添加值和头链表中元素是否重复(通过hashcode来判断)
e = p;
//考虑树的情况
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);//找到链表的末端并添加元素
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//判断添加值和链表中元素是否重复(通过hashcode来判断)
break;
p = e;
}
}
if (e != null) { // 节点和添加值重复了
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//元素的数目增加
if (++size > threshold)//元素的数目是否超过阀值
resize();//扩容
afterNodeInsertion(evict);
return null;
}