1、Python基础知识
在Python中的两种注释方法,分别是#注释和引号(''' ''')注释,#注释类似于C语言中的//注释,引号注释类似于C语言中的/* */注释。接着在Python中标识符第一次字符必须是字母或下划线,除第一个字符意外其他的字符可以使字母、下划线和数字。在Python中的数据类型包括:数、字符串、列表(list)、元组(tuple)、集合(set)和字典(dictionary){key1:value1,key2:value2}。列表[" "," "]中的元素支持修改,而元(" "," ")组中的元素不支持修改。求商://,求余数:%。
1.1Python基础知识运用
将乘法表顺序输出和逆序输出:

1.2Python模块导入
模块导入主要用到两种方法,分别是:import 模块名和from···import····。模块导入这部分的理解是首先要导入已经建好的模块,比如request,将request的路径找到,接着在调用request里面的urlopen函数,下面给出三种导入类型,并对百度的首页进行内容获取。

2、Python文件操作
read(size):未指定size则返回整个文件;
readline():返回一行;
readlines(size):返回size行
write("文件地址","r、w等"):写入数据
close()关闭文件

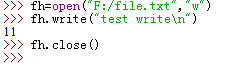
注意在write()后面需要加上close()。在上述操作中,若原file.txt中已有内容,在进行写入操作后,原有内容将被覆盖,全部替换为write后的内容。
异常处理的格式:
try:
代码
except Exception as error:
print(在这里可以输出error的提示)
3、正则表达式
3.1符号及语法
^:匹配字符串开头,若^放在[]中则是取反的意思,如:[^s]+是匹配除了空白字符以外的任意字符
$:匹配字符串结尾
*:匹配前面表达式的0次、一次或多次
?:匹配前面表达式的0次或一次
+:匹配前面表达式的一次或多次
.:匹配除换行符 以外的所有字符串
{m,n}:匹配前一个字符出现至少m次,至多出现7n
/d:匹配任意十进制数
/s:匹配空白字符
/w:匹配字母和数字 # /W、/S、/D匹配与/w、/s、/d为互补关系
3.2常见的re函数
re.match():从起始位置开始匹配,若不成功则返回none
re.rearch():扫描全部字符串返回第一个成功的匹配
re.sub():替换匹配到的字符串
re.compile().findall():全局匹配函数
实例:爬取https://read.douban.com/provider/all提供的所有出版社名称,并写入"出版社.txt"。

其中(.*?)是懒惰模式,表示尽可能少的匹配;(.*)是贪婪模式,表示尽可能多的匹配。在这个代码的最后还需加上fh.close()。“utf-8”将爬取的网页数据解码。在循环中,由于ret中为字符串,所以用len(ret)来将之转换成长度。