drf回顾总结
drf基础
drf全称:django-rest framework,drf框架是一个用户构建Web API(API应用程序编程接口)的强大而灵活的工具,drf框架是建立在django框架基础之上
特点:
1.提供了自定义序列化器Serializer的方法,可以快速根据Django ORM或者其他库自动序列化/反序列化
2.具有丰富的类视图,Mixin扩展类,简化视图的编写
3.丰富的定制层级:函数视图,类视图,视图集合到自动生成API,满足各种需要
4.多种身份认证和权限认证方式的支持
5.内置了限流系统
6.直观的API Web界面
7.可扩展性,插件丰富
知识点
"""
1、接口:什么是接口、restful接口规范
2、CBV生命周期源码 - 基于restful规范下的CBV接口
3、请求组件、解析组件、响应组件
4、序列化组件(灵魂)
5、三大认证(重中之重):认证、权限(权限六表)、频率
6、其他组件:过滤、筛选、排序、分页、路由
"""
# 难点:源码分析
1.drf框架安装
安装
>: pip3 install djangorestframework
drf框架规矩的封装风格
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.request import Request
from rest_framework.serializers import Serializer
from rest_framework.settings import APISettings
from rest_framework.filters import SearchFilter
from rest_framework.pagination import PageNumberPagination
from rest_framework.authentication import TokenAuthentication
from rest_framework.permissions import IsAuthenticated
from rest_framework.throttling import SimpleRateThrottle
class Test(APIView):
def get(self, request, *args, **kwargs):
return Response('drf get ok')
drf请求生命周期
"""
1) 请求走的是APIView的as_view函数
2) 在APIView的as_view调用父类(django原生)的as_view,还禁用了 csrf 认证
3) 在父类的as_view中dispatch方法请求走的又是APIView的dispatch
4) 完成任务方法交给视图类的请求函数处理,得到请求的响应结果,返回给前台
"""
2.接口
"""
接口:联系两个物质的媒介,完成信息交互
web程序中:联系前台页面与后台数据库的媒介
web接口组成:
url:长得像放回数据的url链接
请求参数:前台按照指定的key提供数据给后台
响应数据:后台与数据库交互后将数据反馈给前台
"""
3.restful接口规范
接口规范:就是为了采用不同的后台语言,也能使用同样的接口获取到同样的数据
如何写接口:接口规范是 规范化书写接口的,写接口要写 url、响应数据
注:如果将请求参数也纳入考量范围,那就是在写 接口文档
两大部分:
- url
1) 用api关键字标识接口url
api.baidu.com | www.baidu.com/api
2) 接口数据安全性决定优先选择https协议
3) 如果一个接口有多版本存在,需要在url中标识体现
api.baidu.com/v1/... | api.baidu.com/v2/...
4) 接口操作的数据源称之为 资源,在url中一般采用资源复数形式,一个接口可以概括对该资源的多种操作方式
api.baidu.com/books | api.baidu.com/books/(pk)
5) 请求方式有多种,用一个url处理如何保证不混乱 - 通过请求方式标识操作资源的方式
/books get 获取所有
/books post 增加一个(多个)
/books/(pk) delete 删除一个
/books/(pk) put 整体更新一个
/books/(pk) patch 局部更新一个
6) 资源往往涉及数据的各种操作方式 - 筛选、排序、限制
api.baidu.com/books/?search=西&ordering=-price&limit=3
- 响应数据
1) http请求的响应会有响应状态码,接口用来返回操作的资源数据,可以拥有 操作数据结果的 状态码
status 0(操作资源成功) 1(操作资源失败) 2(操作资源成功,但没匹配结果)
注:资源状态码不像http状态码,一般都是后台与前台或是客户约定的
2) 资源的状态码文字提示
status ok '账号有误' '密码有误' '用户锁定'
3) 资源本身
results
注:删除资源成功不做任何数据返回(返回空字符串)
4) 不能直接放回的资源(子资源、图片、视频等资源),返回该资源的url链接
4.基于restful规范的原生Django接口
主路由:url.py
主要是路由分发
from django.conf.urls import url, include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 路由分发
url(r'^api/', include('api.urls'))
]
api组件的子路由:api/url.py
按照restful规范书写路由接口
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^books/', views.Book.as_view()),
url(r'^books/(?P<pk>.*)/$', views.Book.as_view()),
]
模型层:model.py
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=64)
price = models.DecimalField(max_digits=5, decimal_places=2)
class Meta:
db_table = 'old_boy_book'
verbose_name = '书籍'
verbose_name_plural = verbose_name
def __str__(self):
return '《%s》' % self.title
后台层:admin.py
from django.contrib import admin
from . import models
admin.site.register(models.Book)
数据库迁移
>: python manage.py makemigrations
>: python manage.py migrrate
>: python manage.py createsuperuser
视图层:views.py
from django.http import JsonResponse
from django.views import View
from . import models
# 六大基础接口:获取一个 获取所有 增加一个 删除一个 整体更新一个 局部更新一个
# 十大接口:群增 群删 整体改群改 局部改群改
class Book(View):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if not pk: # 群查
# 操作数据库
book_obj_list = models.Book.objects.all()
# 序列化过程
# “序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。
book_list = []
for obj in book_obj_list:
dic = {}
dic['title'] = obj.title
dic['price'] = obj.price
book_list.append(dic)
# 响应数据
return JsonResponse({
'status': 0,
'msg': 'ok',
'results': book_list
}, json_dumps_params={'ensure_ascii': False})
else: # 单查
book_dic = models.Book.objects.filter(pk=pk).values('title', 'price').first()
if book_dic:
return JsonResponse({
'status': 0,
'msg': 'ok',
'results': book_dic
}, json_dumps_params={'ensure_ascii': False})
return JsonResponse({
'status': 2,
'msg': '无结果',
}, json_dumps_params={'ensure_ascii': False})
# postman可以完成不同方式的请求:get | post | put ...
# postman发送数据包有三种方式:form-data | urlencoding | json
# 原生django对urlencoding方式数据兼容最好
def post(self, request, *args, **kwargs):
# 前台通过urlencoding方式提交数据
try:
book_obj = models.Book.objects.create(**request.POST.dict())
if book_obj:
return JsonResponse({
'status': 0,
'msg': 'ok',
'results': {'title': book_obj.title, 'price': book_obj.price}
}, json_dumps_params={'ensure_ascii': False})
except:
return JsonResponse({
'status': 1,
'msg': '参数有误',
}, json_dumps_params={'ensure_ascii': False})
return JsonResponse({
'status': 2,
'msg': '新增失败',
}, json_dumps_params={'ensure_ascii': False})
JsonResponse与HttpResponse的区别
不同的方法还是有点区别的,我们后台给前台返回数据的时候需要通过json格式的
字符串进行传输,因为前后台都有对json格式字符串进行操作的方式
他们的区别就是HttpResponse需要我们自己前后台进行序列化与反序列化
而JasonResponse则把序列化和反序列化封装了起来,我们直接传入可序列化
的字符串,在前台就能收到对应的数据
drf五大模块
1.请求模块:request对象
源码入口
APIView类的dispatch方法中:request = self.initialize_request(request, *args, **kwargs)
源码分析
"""
# 二次封装得到def的request对象
request = self.initialize_request(request, *args, **kwargs) 点进去
# 在rest_framework.request.Request实例化方法中
self._request = request 将原生request作为新request的_request属性
# 在rest_framework.request.Request的__getattr__方法中
try:
return getattr(self._request, attr) # 访问属性完全兼容原生request
except AttributeError:
return self.__getattribute__(attr)
"""
重点总结
# 1) drf 对原生request做了二次封装,request._request就是原生request
# 2) 原生request对象的属性和方法都可以被drf的request对象直接访问(兼容)
# 3) drf请求的所有url拼接参数均被解析到query_params中,所有数据包数据都被解析到data中
class Test(APIView):
def get(self, request, *args, **kwargs):
# url拼接的参数
print(request._request.GET) # 二次封装方式
print(request.GET) # 兼容
print(request.query_params) # 拓展
return Response('drf get ok')
def post(self, request, *args, **kwargs):
# 所有请求方式携带的数据包
print(request._request.POST) # 二次封装方式
print(request.POST) # 兼容
print(request.data) # 拓展,兼容性最强,三种数据方式都可以
print(request.query_params)
return Response('drf post ok')
2.渲染模块:浏览器和Postman请求结果渲染数据的方式不一样
源码入口
APIView类的dispatch方法中:self.response = self.finalize_response(request, response, *args, **kwargs)
源码分析
"""
# 最后解析reponse对象数据
self.response = self.finalize_response(request, response, *args, **kwargs) 点进去
# 拿到运行的解析类的对象们
neg = self.perform_content_negotiation(request, force=True) 点进去
# 获得解析类对象
renderers = self.get_renderers() 点进去
# 从视图类中得到renderer_classes请求类,如何实例化一个个对象形参解析类对象列表
return [renderer() for renderer in self.renderer_classes]
# 重点:self.renderer_classes获取renderer_classes的顺序
# 自己视图类的类属性(局部配置) =>
# APIView类的类属性设置 =>
# 自己配置文件的DEFAULT_RENDERER_CLASSES(全局配置) =>
# drf配置文件的DEFAULT_RENDERER_CLASSES
"""
全局配置:所有视图类统一处理,在项目的settings.py中
REST_FRAMEWORK = {
# drf提供的渲染类
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
],
}
局部配置:某一个或一些实体类单独处理,在views.py视图类中提供对应的类属性
class Test(APIView):
def get(self, request, *args, **kwargs):
return Response('drf get ok')
def post(self, request, *args, **kwargs):
return Response('drf post ok')
# 在setting.py中配置REST_FRAMEWORK,完成的是全局配置,所有接口统一处理
# 如果只有部分接口特殊化,可以完成 - 局部配置
from rest_framework.renderers import JSONRenderer
class Test2(APIView):
# 局部配置
renderer_classes = [JSONRenderer]
def get(self, request, *args, **kwargs):
return Response('drf get ok 2')
def post(self, request, *args, **kwargs):
return Response('drf post ok 2')
3.解析模块
为什么要配置解析模块
"""
1)drf给我们通过了多种解析数据包方式的解析类
2)我们可以通过配置来控制前台提交的哪些格式的数据后台在解析,哪些数据不解析
3)全局配置就是针对每一个视图类,局部配置就是针对指定的视图来,让它们可以按照配置规则选择性解析数据
"""
源码入口
# APIView类的dispatch方法中
request = self.initialize_request(request, *args, **kwargs) # 点进去
# 获取解析类
parsers=self.get_parsers(), # 点进去
# 去类属性(局部配置) 或 配置文件(全局配置) 拿 parser_classes
return [parser() for parser in self.parser_classes]
全局配置:项目settings.py文件
REST_FRAMEWORK = {
# 全局解析类配置
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser', # json数据包
'rest_framework.parsers.FormParser', # urlencoding数据包
'rest_framework.parsers.MultiPartParser' # form-date数据包
],
}
局部配置:应用views.py的具体视图类
from rest_framework.parsers import JSONParser
class Book(APIView):
# 局部解析类配置,只要json类型的数据包才能被解析
parser_classes = [JSONParser]
pass
4.异常模块
为什么要自定义异常模块
"""
1)所有经过drf的APIView视图类产生的异常,都可以提供异常处理方案
2)drf默认提供了异常处理方案(rest_framework.views.exception_handler),但是处理范围有限
3)drf提供的处理方案两种,处理了返回异常现象,没处理返回None(后续就是服务器抛异常给前台)
4)自定义异常的目的就是解决drf没有处理的异常,让前台得到合理的异常信息返回,后台记录异常具体信息
"""
源码分析
# 异常模块:APIView类的dispatch方法中
response = self.handle_exception(exc) # 点进去
# 获取处理异常的句柄(方法)
# 一层层看源码,走的是配置文件,拿到的是rest_framework.views的exception_handler
# 自定义:直接写exception_handler函数,在自己的配置文件配置EXCEPTION_HANDLER指向自己的
exception_handler = self.get_exception_handler()
# 异常处理的结果
# 自定义异常就是提供exception_handler异常处理函数,处理的目的就是让response一定有值
response = exception_handler(exc, context)
如何使用:自定义exception_handler函数如何书写实现体
# 修改自己的配置文件setting.py
REST_FRAMEWORK = {
# 全局配置异常模块
'EXCEPTION_HANDLER': 'api.exception.exception_handler',
}
# 1)先将异常处理交给rest_framework.views的exception_handler去处理
# 2)判断处理的结果(返回值)response,有值代表drf已经处理了,None代表需要自己处理
# 自定义异常处理文件exception,在文件中书写exception_handler函数
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework.views import Response
from rest_framework import status
def exception_handler(exc, context):
# drf的exception_handler做基础处理
response = drf_exception_handler(exc, context)
# 为空,自定义二次处理
if response is None:
# print(exc)
# print(context)
print('%s - %s - %s' % (context['view'], context['request'].method, exc))
return Response({
'detail': '服务器错误'
}, status=status.HTTP_500_INTERNAL_SERVER_ERROR, exception=True)
return response
5.响应模块
响应类构造器:rest_framework.response.Response
def __init__(self, data=None, status=None,
template_name=None, headers=None,
exception=False, content_type=None):
"""
:param data: 响应数据
:param status: http响应状态码
:param template_name: drf也可以渲染页面,渲染的页面模板地址(不用了解)
:param headers: 响应头
:param exception: 是否异常了
:param content_type: 响应的数据格式(一般不用处理,响应头中带了,且默认是json)
"""
pass
使用:常规实例化响应对象
# status就是解释一堆 数字 网络状态码的模块
from rest_framework import status就是解释一堆 数字 网络状态码的模块
# 一般情况下只需要返回数据,status和headers都有默认值
return Response(data={数据}, status=status.HTTP_200_OK, headers={设置的响应头})
序列化组件:
知识点:Serializer(偏底层)、ModelSerializer(重点)、ListModelSerializer(辅助群改)
1.Serializer
序列化准备:
- 模型层:models.py
class User(models.Model):
SEX_CHOICES = [
[0, '男'],
[1, '女'],
]
name = models.CharField(max_length=64)
pwd = models.CharField(max_length=32)
phone = models.CharField(max_length=11, null=True, default=None)
sex = models.IntegerField(choices=SEX_CHOICES, default=0)
icon = models.ImageField(upload_to='icon', default='icon/default.jpg')
class Meta:
db_table = 'old_boy_user'
verbose_name = '用户'
verbose_name_plural = verbose_name
def __str__(self):
return '%s' % self.name
- 后台管理层:admin.py
from django.contrib import admin
from . import models
admin.site.register(models.User)
- 配置层:settings.py
# 注册rest_framework
INSTALLED_APPS = [
# ...
'rest_framework',
]
# 配置数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'day70',
'USER': 'root',
'PASSWORD': '123'
}
}
# media资源
MEDIA_URL = '/media/' # 后期高级序列化类与视图类,会使用该配置
MEDIA_ROOT = os.path.join(BASE_DIR, 'media') # media资源路径
# 国际化配置
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
USE_TZ = False
- 主路由:项目下urls.py
urlpatterns = [
# ...
url(r'^api/', include('api.urls')),
url(r'^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}),
]
- 子路由:应用下urls.py
urlpatterns = [
url(r'^users/$', views.User.as_view()),
url(r'^users/(?P<pk>.*)/$', views.User.as_view()),
]
序列化使用
- 序列化层:api/serializers.py
"""
1)设置需要返回给前台 那些model类有对应的 字段,不需要返回的就不用设置了
2)设置方法字段,字段名可以随意,字段值有 get_字段名 提供,来完成一些需要处理在返回的数据
"""
# 序列化组件 - 为每一个model类通过一套序列化工具类
# 序列化组件的工作方式与django froms组件非常相似
from rest_framework import serializers, exceptions
from django.conf import settings
from . import models
class UserSerializer(serializers.Serializer):
name = serializers.CharField()
phone = serializers.CharField()
# 序列化提供给前台的字段个数由后台决定,可以少提供,
# 但是提供的数据库对应的字段,名字一定要与数据库字段相同
# sex = serializers.IntegerField()
# icon = serializers.ImageField()
# 自定义序列化属性
# 属性名随意,值由固定的命名规范方法提供:
# get_属性名(self, 参与序列化的model对象)
# 返回值就是自定义序列化属性的值
gender = serializers.SerializerMethodField()
# 或者在model.py中使用插拔式自定义字段
# class Car(BaseModel):
# name = models.CharFiled(max_length=64)
# @property
# def my_name(self):
# 自定义字段:可以连表,可以完成数据相关的逻辑
@ return '插拔式字段的值'
@ def get_gender(self, obj):
# choice类型的解释型值 get_字段_display() 来访问
return obj.get_sex_display()
icon = serializers.SerializerMethodField()
def get_icon(self, obj):
# settings.MEDIA_URL: 自己配置的 /media/,给后面高级序列化与视图类准备的
# obj.icon不能直接作为数据返回,因为内容虽然是字符串,但是类型是ImageFieldFile类型
return '%s%s%s' % (r'http://127.0.0.1:8000', settings.MEDIA_URL, str(obj.icon))
- 视图层
"""
1)从数据库中将要序列化给前台的model对象,或是多个model对象查询出来
user_obj = models.User.objects.get(pk=pk) 或者
user_obj_list = models.User.objects.all()
2)将对象交给序列化处理,产生序列化对象,如果序列化的是多个数据,要设置many=True
user_ser = serializers.UserSerializer(user_obj) 或者
user_ser = serializers.UserSerializer(user_obj_list, many=True)
3)序列化 对象.data 就是可以返回给前台的序列化数据
return Response({
'status': 0,
'msg': 0,
'results': user_ser.data
})
"""
class User(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
try:
# 用户对象不能直接作为数据返回给前台
user_obj = models.User.objects.get(pk=pk)
# 序列化一下用户对象
user_ser = serializers.UserSerializer(user_obj)
# print(user_ser, type(user_ser))
return Response({
'status': 0,
'msg': 0,
'results': user_ser.data
})
except:
return Response({
'status': 2,
'msg': '用户不存在',
})
else:
# 用户对象列表(queryset)不能直接作为数据返回给前台
user_obj_list = models.User.objects.all()
# 序列化一下用户对象
user_ser_data = serializers.UserSerializer(user_obj_list, many=True).data
return Response({
'status': 0,
'msg': 0,
'results': user_ser_data
})
反序列化使用
- 反序列层:api/serializers.py
"""
1)设置必填与选填序列化字段,设置校验规则
2)为需要额外校验的字段提供局部钩子函数,如果该字段不入库,且不参与全局钩子校验,可以将值取出校验
3)为有联合关系的字段们提供全局钩子函数,如果某些字段不入库,可以将值取出校验
4)重写create方法,完成校验通过的数据入库工作,得到新增的对象
"""
class UserDeserializer(serializers.Serializer):
# 1) 哪些自动必须反序列化
# 2) 字段都有哪些安全校验
# 3) 哪些字段需要额外提供校验
# 4) 哪些字段间存在联合校验
# 注:反序列化字段都是用来入库的,不会出现自定义方法属性,会出现可以设置校验规则的自定义属性(re_pwd)
name = serializers.CharField(
max_length=64,
min_length=3,
error_messages={
'max_length': '太长',
'min_length': '太短'
}
)
pwd = serializers.CharField()
phone = serializers.CharField(required=False)
sex = serializers.IntegerField(required=False)
# 自定义有校验规则的反序列化字段
re_pwd = serializers.CharField(required=True)
# 小结:
# name,pwd,re_pwd为必填字段
# phone,sex为选填字段
# 五个字段都必须提供完成的校验规则
# 局部钩子:validate_要校验的字段名(self, 当前要校验字段的值)
# 校验规则:校验通过返回原值,校验失败,抛出异常
def validate_name(self, value):
if 'g' in value.lower(): # 名字中不能出现g
raise exceptions.ValidationError('名字非法,是个鸡贼!')
return value
# 全局钩子:validate(self, 系统与局部钩子校验通过的所有数据)
# 校验规则:校验通过返回原值,校验失败,抛出异常
def validate(self, attrs):
pwd = attrs.get('pwd')
re_pwd = attrs.pop('re_pwd')
if pwd != re_pwd:
raise exceptions.ValidationError({'pwd&re_pwd': '两次密码不一致'})
return attrs
# 要完成新增,需要自己重写 create 方法
def create(self, validated_data):
# 尽量在所有校验规则完毕之后,数据可以直接入库
return models.User.objects.create(**validated_data)
- 视图层
"""
1)book_ser = serializers.UserDeserializer(data=request_data) # 数据必须赋值data
2)book_ser.is_valid() # 结果为 通过 | 不通过
3)不通过返回 book_ser.errors 给前台,通过 book_ser.save() 得到新增的对象,再正常返回
"""
class User(APIView):
# 只考虑单增
def post(self, request, *args, **kwargs):
# 请求数据
request_data = request.data
# 数据是否合法(增加对象需要一个字典数据)
if not isinstance(request_data, dict) or request_data == {}:
return Response({
'status': 1,
'msg': '数据有误',
})
# 数据类型合法,但数据内容不一定合法,需要校验数据,校验(参与反序列化)的数据需要赋值给data
book_ser = serializers.UserDeserializer(data=request_data)
# 序列化对象调用is_valid()完成校验,校验失败的失败信息都会被存储在 序列化对象.errors
if book_ser.is_valid():
# 校验通过,完成新增
book_obj = book_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.UserSerializer(book_obj).data
})
else:
# 校验失败
return Response({
'status': 1,
'msg': book_ser.errors,
})
2.序列化与反序列化整合(重点)
序列化层:api/serializers.py
"""
1) fields中设置所有序列化与反序列化字段
2) extra_kwargs划分只序列化或只反序列化字段
write_only:只反序列化
read_only:只序列化
自定义字段默认只序列化(read_only)
3) 设置反序列化所需的 系统、局部钩子、全局钩子 等校验规则
"""
class V2BookModelSerializer(ModelSerializer):
class Meta:
model = models.Book
fields = ('name', 'price', 'img', 'author_list', 'publish_name', 'publish', 'authors')
extra_kwargs = {
'name': {
'required': True,
'min_length': 1,
'error_messages': {
'required': '必填项',
'min_length': '太短',
}
},
'publish': {
'write_only': True
},
'authors': {
'write_only': True
},
'img': {
'read_only': True,
},
'author_list': {
'read_only': True,
},
'publish_name': {
'read_only': True,
}
}
def validate_name(self, value):
# 书名不能包含 g 字符
if 'g' in value.lower():
raise ValidationError('该g书不能出版')
return value
def validate(self, attrs):
publish = attrs.get('publish')
name = attrs.get('name')
if models.Book.objects.filter(name=name, publish=publish):
raise ValidationError({'book': '该书已存在'})
return attrs
视图层:api/views.py
class V2Book(APIView):
# 单查:有pk
# 群查:无pk
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
try:
book_obj = models.Book.objects.get(pk=pk, is_delete=False)
book_data = serializers.V2BookModelSerializer(book_obj).data
except:
return Response({
'status': 1,
'msg': '书籍不存在'
})
else:
book_query = models.Book.objects.filter(is_delete=False).all()
book_data = serializers.V2BookModelSerializer(book_query, many=True).data
return Response({
'status': 0,
'msg': 'ok',
'results': book_data
})
# 单增:传的数据是与model对应的字典
# 群增:传的数据是 装多个 model对应字典 的列表
def post(self, request, *args, **kwargs):
request_data = request.data
if isinstance(request_data, dict):
many = False
elif isinstance(request_data, list):
many = True
else:
return Response({
'status': 1,
'msg': '数据有误',
})
book_ser = serializers.V2BookModelSerializer(data=request_data, many=many)
# 当校验失败,马上终止当前视图方法,抛异常返回给前台
book_ser.is_valid(raise_exception=True)
book_result = book_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.V2BookModelSerializer(book_result, many=many).data
})
# 单删:有pk
# 群删:有pks | {"pks": [1, 2, 3]}
def delete(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
pks = [pk]
else:
pks = request.data.get('pks')
if models.Book.objects.filter(pk__in=pks, is_delete=False).update(is_delete=True):
return Response({
'status': 0,
'msg': '删除成功',
})
return Response({
'status': 1,
'msg': '删除失败',
})
路由层:api/urls.py
urlpatterns = [
url(r'^v2/books/$', views.V2Book.as_view()),
url(r'^v2/books/(?P<pk>.*)/$', views.V2Book.as_view()),
]
3.整体单改
路由层、模型层、序列化层不需要做修改,只需要处理视图层:views.py
"""
1) 单整体改,说明前台要提供修改的数据,那么数据就需要校验,校验的数据应该在实例化“序列化类对象”时,赋值给data
2)修改,就必须明确被修改的模型类对象,并在实例化“序列化类对象”时,赋值给instance
3)整体修改,所有校验规则有required=True的字段,都必须提供,因为在实例化“序列化类对象”时,参数partial默认为False
注:如果partial值设置为True,就是可以局部改
1)单整体修改,一般用put请求:
V2BookModelSerializer(
instance=要被更新的对象,
data=用来更新的数据,
partial=默认False,必须的字段全部参与校验
)
2)单局部修改,一般用patch请求:
V2BookModelSerializer(
instance=要被更新的对象,
data=用来更新的数据,
partial=设置True,必须的字段都变为选填字段
)
注:partial设置True的本质就是使字段 required=True 校验规则失效
"""
class V2Book(APIView):
# 单整体改: 对 v2/books/(pk)/ 传的数据是与model对应的字典{name|price|publish|authors}
def put(self, request, *args, **kwargs):
request_data = request.data
pk = kwargs.get('pk')
old_book_obj = models.Book.objects.filter(pk=pk).first()
# 目的:将众多数据的校验交给序列化类来处理 - 让序列化类扮演反序列化角色,校验成功后,序列化类来帮你入库
book_ser = serializers.V2BookModelSerializer(instance=old_book_obj, data=request_data, partial=False)
book_ser.is_valid(raise_exception=True)
# 校验通过,完成数据的更新:要更新的目标,用来更新的新数据
book_obj = book_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.V2BookModelSerializer(book_obj).data
})
4.单与整体局部修改
序列化层:serializers.py
# 重点:ListSerializer与ModelSerializer建立关联的是:
# ModelSerializer的Meta类的 - list_serializer_class
class V2BookListSerializer(ListSerializer):
def update(self, instance, validated_data):
# print(instance) # 要更新的对象们
# print(validated_data) # 更新的对象对应的数据们
# print(self.child) # 服务的模型序列化类 - V2BookModelSerializer
for index, obj in enumerate(instance):
self.child.update(obj, validated_data[index])
return instance
# 原模型序列化类变化
class V2BookModelSerializer(ModelSerializer):
class Meta:
# ...
# 群改,需要设置 自定义ListSerializer,重写群改的 update 方法
list_serializer_class = V2BookListSerializer
# ...
视图层:views.py
class V2Book(APIView):
# 单局部改:对 v2/books/(pk)/ 传的数据,数据字段key都是选填
# 群局部改:对 v2/books/
# 请求数据 - [{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}]
def patch(self, request, *args, **kwargs):
request_data = request.data
pk = kwargs.get('pk')
# 将单改,群改的数据都格式化成 pks=[要需要的对象主键标识] | request_data=[每个要修改的对象对应的修改数据]
if pk and isinstance(request_data, dict): # 单改
pks = [pk, ]
request_data = [request_data, ]
elif not pk and isinstance(request_data, list): # 群改
pks = []
for dic in request_data: # 遍历前台数据[{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}],拿一个个字典
pk = dic.pop('pk', None)
if pk:
pks.append(pk)
else:
return Response({
'status': 1,
'msg': '数据有误',
})
else:
return Response({
'status': 1,
'msg': '数据有误',
})
# pks与request_data数据筛选,
# 1)将pks中的没有对应数据的pk与数据已删除的pk移除,request_data对应索引位上的数据也移除
# 2)将合理的pks转换为 objs
objs = []
new_request_data = []
for index, pk in enumerate(pks):
try:
# pk对应的数据合理,将合理的对象存储
obj = models.Book.objects.get(pk=pk)
objs.append(obj)
# 对应索引的数据就需要保存下来
new_request_data.append(request_data[index])
except:
# 重点:反面教程 - pk对应的数据有误,将对应索引的data中request_data中移除
# index = pks.index(pk)
# request_data.pop(index)
continue
book_ser = serializers.V2BookModelSerializer(instance=objs, data=new_request_data, partial=True, many=True)
book_ser.is_valid(raise_exception=True)
book_objs = book_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.V2BookModelSerializer(book_objs, many=True).data
})
视图类
视图类传递参数给序列化类
# 1)在视图类中实例化序列化对象时,可以设置context内容
# 2)在序列化类中的局部钩子、全局钩子、create、update方法中,都可以用self.context访问视图类传递过来的内容
# 需求:
# 1) 在视图类中,可以通过request得到登陆用户request.user
# 2) 在序列化类中,要完成数据库数据的校验与入库操作,可能会需要知道当前的登陆用户,但序列化类无法访问request
# 3) 在视图类中实例化序列化对象时,将request对象传递进去
视图层:views.py
class Book(APIView):
def post(self, request, *args, **kwargs):
book_ser = serializers.BookModelSerializer(data=request_data,context={'request':request})
book_ser.is_valid(raise_exception=True)
book_result = book_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.BookModelSerializer(book_result).data
})
序列化层:serializers.py
class BookModelSerializer(ModelSerializer):
class Meta:
model = models.Book
fields = ('name', 'price')
def validate_name(self, value):
print(self.context.get('request').method)
return value
二次封装Response类
"""
Response({
'status': 0,
'msg': 'ok',
'results': [],
'token': '' # 有这样的额外的key-value数据结果
},status=http_status,headers=headers,exception=True|False)
APIResponse() => Response({'status': 0,'msg': 'ok'})
"""
from rest_framework.response import Response
class APIResponse(Response):
def __init__(self, data_status=0, data_msg='ok', results=None, http_status=None, headers=None, exception=False, **kwargs):
# data的初始状态:状态码与状态信息
data = {
'status': data_status,
'msg': data_msg,
}
# data的响应数据体
# results可能是False、0等数据,这些数据某些情况下也会作为合法数据返回
if results is not None:
data['results'] = results
# data响应的其他内容
# if kwargs is not None:
# for k, v in kwargs.items():
# setattr(data, k, v)
data.update(kwargs)
super().__init__(data=data, status=http_status, headers=headers, exception=exception)
视图家族
"""
views:视图
generics:工具视图
mixins:视图工具集
viewsets:视图集
"""
"""
学习曲线
APIView => GenericAPIView => mixins的五大工具类 => generics中的工具视图 => viewsets中的视图集
"""
GenericAPIView基类
# GenericAPIView是继承APIView的,使用完全兼容APIView
# 重点:GenericAPIView在APIView基础上完成了哪些事
# 1)get_queryset():从类属性queryset中获得model的queryset数据
# 2)get_object():从类属性queryset中获得model的queryset数据,再通过有名分组pk确定唯一操作对象
# 3)get_serializer():从类属性serializer_class中获得serializer的序列化类
urlpatterns = [
url(r'^v2/books/$', views.BookGenericAPIView.as_view()),
url(r'^v2/books/(?P<pk>.*)/$', views.BookGenericAPIView.as_view()),
]
from rest_framework.generics import GenericAPIView
class BookGenericAPIView(GenericAPIView):
queryset = models.Book.objects.filter(is_delete=False)
serializer_class = serializers.BookModelSerializer
# 自定义主键的 有名分组 名
lookup_field = 'pk'
# 群取
# def get(self, request, *args, **kwargs):
# book_query = self.get_queryset()
# book_ser = self.get_serializer(book_query, many=True)
# book_data = book_ser.data
# return APIResponse(results=book_data)
# 单取
def get(self, request, *args, **kwargs):
book_query = self.get_object()
book_ser = self.get_serializer(book_query)
book_data = book_ser.data
return APIResponse(results=book_data)
mixins视图工具集 - 辅助GenericAPIView
# 1)mixins有五个工具类文件,一共提供了五个工具类,六个工具方法:单查、群查、单增、单删、单整体改、单局部改
# 2)继承工具类可以简化请求函数的实现体,但是必须继承GenericAPIView,需要GenericAPIView类提供的几个类属性和方法(见上方GenericAPIView基类知识点)
# 3)工具类的工具方法返回值都是Response类型对象,如果要格式化数据格式再返回给前台,可以通过 response.data 拿到工具方法返回的Response类型对象的响应数据
urlpatterns = [
url(r'^v3/books/$', views.BookMixinGenericAPIView.as_view()),
url(r'^v3/books/(?P<pk>.*)/$', views.BookMixinGenericAPIView.as_view()),
]
from rest_framework.mixins import ListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin
class BookMixinGenericAPIView(ListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin, GenericAPIView):
queryset = models.Book.objects.filter(is_delete=False)
serializer_class = serializers.BookModelSerializer
def get(self, request, *args, **kwargs):
if 'pk' in kwargs:
response = self.retrieve(request, *args, **kwargs)
else:
# mixins提供的list方法的响应对象是Response,想将该对象格式化为APIResponse
response = self.list(request, *args, **kwargs)
# response的数据都存放在response.data中
return APIResponse(results=response.data)
def post(self, request, *args, **kwargs):
response = self.create(request, *args, **kwargs)
return APIResponse(results=response.data)
def put(self, request, *args, **kwargs):
response = self.update(request, *args, **kwargs)
return APIResponse(results=response.data)
def patch(self, request, *args, **kwargs):
response = self.partial_update(request, *args, **kwargs)
return APIResponse(results=response.data)
工具视图
# 1)工具视图都是GenericAPIView的子类,且不同的子类继承了不同的工具类,重写了请求方法
# 2)工具视图的功能如果直接可以满足需求,只需要继承工具视图,提供queryset与serializer_class即可
urlpatterns = [
url(r'^v4/books/$', views.BookListCreatePIView.as_view()),
url(r'^v4/books/(?P<pk>.*)/$', views.BookListCreatePIView.as_view()),
]
from rest_framework.generics import ListCreateAPIView, UpdateAPIView
class BookListCreatePIView(ListCreateAPIView, UpdateAPIView):
queryset = models.Book.objects.filter(is_delete=False)
serializer_class = serializers.BookModelSerializer
视图集
# 1)视图集都是优先继承ViewSetMixin类,再继承一个视图类(GenericAPIView或APIView)
# GenericViewSet、ViewSet
# 2)ViewSetMixin提供了重写的as_view()方法,继承视图集的视图类,配置路由时调用as_view()必须传入 请求名-函数名 映射关系字典
# eg: url(r'^v5/books/$', views.BookGenericViewSet.as_view({'get': 'my_get_list'})),
# 表示get请求会交给my_get_list视图函数处理
urlpatterns = [
# View的as_view():将get请求映射到视图类的get方法
# ViewSet的as_view({'get': 'my_get_list'}):将get请求映射到视图类的my_get_list方法
url(r'^v5/books/$', views.BookGenericViewSet.as_view({'get': 'my_get_list'})),
url(r'^v5/books/(?P<pk>.*)/$', views.BookGenericViewSet.as_view({'get': 'my_get_obj'})),
]
from rest_framework.viewsets import GenericViewSet
from rest_framework import mixins
class BookGenericViewSet(mixins.RetrieveModelMixin, mixins.ListModelMixin, GenericViewSet):
queryset = models.Book.objects.filter(is_delete=False)
serializer_class = serializers.BookModelSerializer
def my_get_list(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def my_get_obj(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
GenericAPIView 与 APIView 最为两大继承视图的区别
# 1)GenericViewSet和ViewSet都继承了ViewSetMixin,as_view都可以配置 请求-函数 映射
# 2)GenericViewSet继承的是GenericAPIView视图类,用来完成标准的 model 类操作接口
# 3)ViewSet继承的是APIView视图类,用来完成不需要 model 类参与,或是非标准的 model 类操作接口
# post请求在标准的 model 类操作下就是新增接口,登陆的post不满足
# post请求验证码的接口,不需要 model 类的参与
# 案例:登陆的post请求,并不是完成数据的新增,只是用post提交数据,得到的结果也不是登陆的用户信息,而是登陆的认证信息
工具视图集
urlpatterns = [
url(r'^v6/books/$', views.BookModelViewSet.as_view({'get': 'list', 'post': 'create'})),
url(r'^v6/books/(?P<pk>.*)/$', views.BookModelViewSet.as_view({'get': 'retrieve', 'put': 'update', 'patch': 'partial_update', 'delete': 'destroy'})),
]
from rest_framework.viewsets import ModelViewSet
class BookModelViewSet(ModelViewSet):
queryset = models.Book.objects.filter(is_delete=False)
serializer_class = serializers.BookModelSerializer
# 删不是数据库,而是该记录中的删除字段
def destroy(self, request, *args, **kwargs):
instance = self.get_object() # type: models.Book
if not instance:
return APIResponse(1, '删除失败') # 实际操作,在此之前就做了判断
instance.is_delete = True
instance.save()
return APIResponse(0, '删除成功')
路由组件(了解)
from django.conf.urls import include
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
# 所有路由与ViewSet视图类的都可以注册,会产生 '^v6/books/$' 和 '^v6/books/(?P<pk>[^/.]+)/$'
router.register('v6/books', views.BookModelViewSet)
urlpatterns = [
# 第一种添加子列表方式
url(r'^', include(router.urls)),
]
# 第二种添加子列表方式
# urlpatterns.extend(router.urls)
认证规则演变图
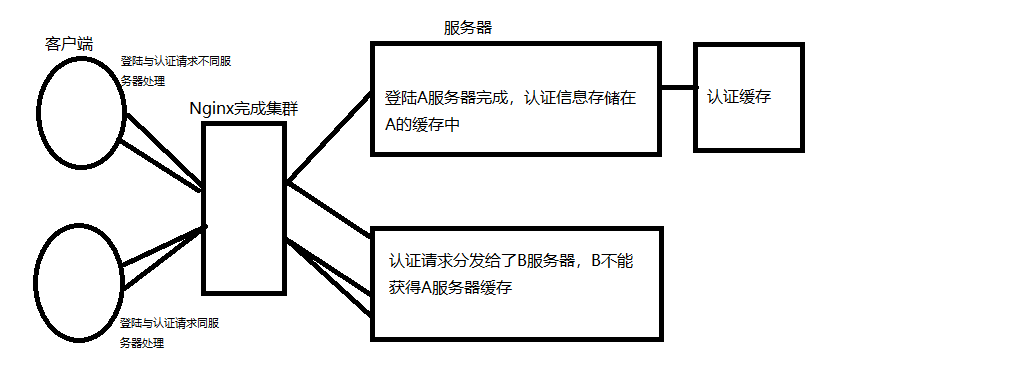
数据库session认证:低效

缓存认证:高效

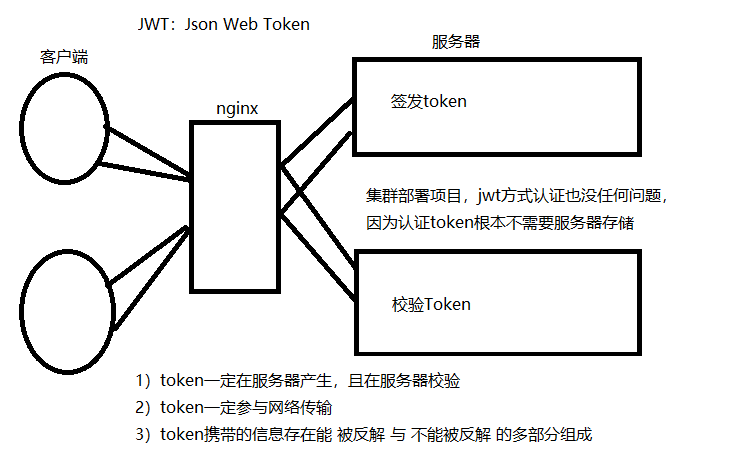
jwt认证:高效

缓存认证:不易并发
jwt认证:易并发
JWT
工作原理
"""
1) jwt = base64(头部).base(载荷).hash256(base64(头部).base(载荷).密钥)
2) base64是可逆的算法、hash256是不可逆的算法
3) 密钥是固定的字符串,保存在服务器
"""
优点
"""
1) 服务器不要存储token,token交给每一个客户端自己存储,服务器压力小
2)服务器存储的是 签发和校验token 两段算法,签发认证的效率高
3)算法完成各集群服务器同步成本低,路由项目完成集群部署(适应高并发)
"""
格式
"""
1) jwt token采用三段式:头部.载荷.签名
2)每一部分都是一个json字典加密形参的字符串
3)头部和载荷采用的是base64可逆加密(前台后台都可以解密)
4)签名采用hash256不可逆加密(后台校验采用碰撞校验)
5)各部分字典的内容:
头部:基础信息 - 公司信息、项目组信息、可逆加密采用的算法
载荷:有用但非私密的信息 - 用户可公开信息、过期时间
签名:头部+载荷+秘钥 不可逆加密后的结果
注:服务器jwt签名加密秘钥一定不能泄露
签发token:固定的头部信息加密.当前的登陆用户与过期时间加密.头部+载荷+秘钥生成不可逆加密
校验token:头部可校验也可以不校验,载荷校验出用户与过期时间,头部+载荷+秘钥完成碰撞检测校验token是否被篡改
"""
drf-jwt
官网
http://getblimp.github.io/django-rest-framework-jwt/
安装:虚拟环境
pip install djangorestframework-jwt
使用:user/urls.py
from django.urls import path
from rest_framework_jwt.views import obtain_jwt_token
urlpatterns = [
path('login/', obtain_jwt_token),
]
测试接口:post请求
"""
postman发生post请求
接口:http://api.luffy.cn:8000/user/login/
数据:
{
"username":"admin",
"password":"admin"
}
"""
drf-jwt开发
配置信息:JWT_AUTH到dev.py中
import datetime
JWT_AUTH = {
# 过期时间
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
# 自定义认证结果:见下方序列化user和自定义response
'JWT_RESPONSE_PAYLOAD_HANDLER': 'user.utils.jwt_response_payload_handler',
}
序列化user:user/serializers.py(自己创建)
from rest_framework import serializers
from . import models
class UserModelSerializers(serializers.ModelSerializer):
class Meta:
model = models.User
fields = ['username']
自定义response:user/utils.py
from .serializers import UserModelSerializers
def jwt_response_payload_handler(token, user=None, request=None):
return {
'status': 0,
'msg': 'ok',
'data': {
'token': token,
'user': UserModelSerializers(user).data
}
}
基于drf-jwt的全局认证:user/authentications.py(自己创建)
import jwt
from rest_framework.exceptions import AuthenticationFailed
from rest_framework_jwt.authentication import jwt_decode_handler
from rest_framework_jwt.authentication import get_authorization_header
from rest_framework_jwt.authentication import BaseJSONWebTokenAuthentication
class JSONWebTokenAuthentication(BaseJSONWebTokenAuthentication):
def authenticate(self, request):
jwt_value = get_authorization_header(request)
if not jwt_value:
raise AuthenticationFailed('Authorization 字段是必须的')
try:
payload = jwt_decode_handler(jwt_value)
except jwt.ExpiredSignature:
raise AuthenticationFailed('签名过期')
except jwt.InvalidTokenError:
raise AuthenticationFailed('非法用户')
user = self.authenticate_credentials(payload)
return user, jwt_value
全局启用:settings/dev.py
REST_FRAMEWORK = {
# 认证模块
'DEFAULT_AUTHENTICATION_CLASSES': (
'user.authentications.JSONWebTokenAuthentication',
),
}
局部启用禁用:任何一个cbv类首行
# 局部禁用
authentication_classes = []
# 局部启用
from user.authentications import JSONWebTokenAuthentication
authentication_classes = [JSONWebTokenAuthentication]
多方式登录:user/utils.py
import re
from .models import User
from django.contrib.auth.backends import ModelBackend
class JWTModelBackend(ModelBackend):
def authenticate(self, request, username=None, password=None, **kwargs):
try:
if re.match(r'^1[3-9]d{9}$', username):
user = User.objects.get(mobile=username)
else:
user = User.objects.get(username=username)
except User.DoesNotExist:
return None
if user.check_password(password) and self.user_can_authenticate(user):
return user
配置多方式登录:settings/dev.py
AUTHENTICATION_BACKENDS = ['user.utils.JWTModelBackend']
手动签发JWT:了解 - 可以拥有原生登录基于Model类user对象签发JWT
from rest_framework_jwt.settings import api_settings
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
针对token操作
登录 - 签发token:api/urls.py
# ObtainJSONWebToken视图类就是通过username和password得到user对象然后签发token
from rest_framework_jwt.views import ObtainJSONWebToken, obtain_jwt_token
urlpatterns = [
# url(r'^jogin/$', ObtainJSONWebToken.as_view()),
url(r'^jogin/$', obtain_jwt_token),
]
认证 - 校验token:全局或局部配置drf-jwt的认证类 JSONWebTokenAuthentication
from rest_framework.views import APIView
from utils.response import APIResponse
# 必须登录后才能访问 - 通过了认证权限组件
from rest_framework.permissions import IsAuthenticated
from rest_framework_jwt.authentication import JSONWebTokenAuthentication
class UserDetail(APIView):
authentication_classes = [JSONWebTokenAuthentication] # jwt-token校验request.user
permission_classes = [IsAuthenticated] # 结合权限组件筛选掉游客
def get(self, request, *args, **kwargs):
return APIResponse(results={'username': request.user.username})
路由与接口测试
# 路由
url(r'^user/detail/$', views.UserDetail.as_view()),
# 接口:/api/user/detail/
# 认证信息:必须在请求头的 Authorization 中携带 "jwt 后台签发的token" 格式的认证字符串
三大认证
源码分析
"""
1)APIView的dispath(self, request, *args, **kwargs)
2)dispath方法内 self.initial(request, *args, **kwargs) 进入三大认证
# 认证组件:校验用户 - 游客、合法用户、非法用户
# 游客:代表校验通过,直接进入下一步校验(权限校验)
# 合法用户:代表校验通过,将用户存储在request.user中,再进入下一步校验(权限校验)
# 非法用户:代表校验失败,抛出异常,返回403权限异常结果
self.perform_authentication(request)
# 权限组件:校验用户权限 - 必须登录、所有用户、登录读写游客只读、自定义用户角色
# 认证通过:可以进入下一步校验(频率认证)
# 认证失败:抛出异常,返回403权限异常结果
self.check_permissions(request)
# 频率组件:限制视图接口被访问的频率次数 - 限制的条件(IP、id、唯一键)、频率周期时间(s、m、h)、频率的次数(3/s)
# 没有达到限次:正常访问接口
# 达到限次:限制时间内不能访问,限制时间达到后,可以重新访问
self.check_throttles(request)
3) 认证组件
Request类的 方法属性 user 的get方法 => self._authenticate() 完成认证
认证的细则:
# 做认证
def _authenticate(self):
# 遍历拿到一个个认证器,进行认证
# self.authenticators配置的一堆认证类产生的认证类对象组成的 list
for authenticator in self.authenticators:
try:
# 认证器(对象)调用认证方法authenticate(认证类对象self, request请求对象)
# 返回值:登陆的用户与认证的信息组成的 tuple
# 该方法被try包裹,代表该方法会抛异常,抛异常就代表认证失败
user_auth_tuple = authenticator.authenticate(self)
except exceptions.APIException:
self._not_authenticated()
raise
# 返回值的处理
if user_auth_tuple is not None:
self._authenticator = authenticator
# 如何有返回值,就将 登陆用户 与 登陆认证 分别保存到 request.user、request.auth
self.user, self.auth = user_auth_tuple
return
# 如果返回值user_auth_tuple为空,代表认证通过,但是没有 登陆用户 与 登陆认证信息,代表游客
self._not_authenticated()
4) 权限组件
self.check_permissions(request)
认证细则:
def check_permissions(self, request):
# 遍历权限对象列表得到一个个权限对象(权限器),进行权限认证
for permission in self.get_permissions():
# 权限类一定有一个has_permission权限方法,用来做权限认证的
# 参数:权限对象self、请求对象request、视图类对象
# 返回值:有权限返回True,无权限返回False
if not permission.has_permission(request, self):
self.permission_denied(
request, message=getattr(permission, 'message', None)
)
"""
认证组件
自定义认证类
"""
1) 创建继承BaseAuthentication的认证类
2) 实现authenticate方法
3) 实现体根据认证规则 确定游客、非法用户、合法用户
4) 进行全局或局部配置
认证规则
i.没有认证信息返回None(游客)
ii.有认证信息认证失败抛异常(非法用户)
iii.有认证信息认证成功返回用户与认证信息元组(合法用户)
"""
utils/authentications.py
# 自定义认证类
# 1)继承BaseAuthentication类
# 2)重新authenticate(self, request)方法,自定义认证规则
# 3)认证规则基于的条件:
# 没有认证信息返回None(游客)
# 有认证信息认证失败抛异常(非法用户)
# 有认证信息认证成功返回用户与认证信息元组(合法用户)
# 4)完全视图类的全局(settings文件中)或局部(确切的视图类)配置
from rest_framework.authentication import BaseAuthentication
from rest_framework.exceptions import AuthenticationFailed
from . import models
class MyAuthentication(BaseAuthentication):
"""
同前台请求头拿认证信息auth(获取认证的字段要与前台约定)
没有auth是游客,返回None
有auth进行校验
失败是非法用户,抛出异常
成功是合法用户,返回 (用户, 认证信息)
"""
def authenticate(self, request):
# 前台在请求头携带认证信息,
# 且默认规范用 Authorization 字段携带认证信息,
# 后台固定在请求对象的META字段中 HTTP_AUTHORIZATION 获取
auth = request.META.get('HTTP_AUTHORIZATION', None)
# 处理游客
if auth is None:
return None
# 设置一下认证字段小规则(两段式):"auth 认证字符串"
auth_list = auth.split()
# 校验合法还是非法用户
if not (len(auth_list) == 2 and auth_list[0].lower() == 'auth'):
raise AuthenticationFailed('认证信息有误,非法用户')
# 合法的用户还需要从auth_list[1]中解析出来
# 注:假设一种情况,信息为abc.123.xyz,就可以解析出admin用户;实际开发,该逻辑一定是校验用户的正常逻辑
if auth_list[1] != 'abc.123.xyz': # 校验失败
raise AuthenticationFailed('用户校验失败,非法用户')
user = models.User.objects.filter(username='admin').first()
if not user:
raise AuthenticationFailed('用户数据有误,非法用户')
return (user, None)
权限组件
系统权限类源码
"""
1)AllowAny:
认证规则全部返还True:return True
游客与登陆用户都有所有权限
2) IsAuthenticated:
认证规则必须有登陆的合法用户:return bool(request.user and request.user.is_authenticated)
游客没有任何权限,登陆用户才有权限
3) IsAdminUser:
认证规则必须是后台管理用户:return bool(request.user and request.user.is_staff)
游客没有任何权限,登陆用户才有权限
4) IsAuthenticatedOrReadOnly
认证规则必须是只读请求或是合法用户:
return bool(
request.method in SAFE_METHODS or
request.user and
request.user.is_authenticated
)
游客只读,合法用户无限制
"""
# api/views.py
from rest_framework.permissions import IsAuthenticated
class TestAuthenticatedAPIView(APIView):
permission_classes = [IsAuthenticated]
def get(self, request, *args, **kwargs):
return APIResponse(0, 'test 登录才能访问的接口 ok')
# 因为默认全局配置的权限类是AllowAny
# settings.py
REST_FRAMEWORK = {
# 权限类配置
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.AllowAny',
],
}
自定义权限类
"""
1) 创建继承BasePermission的权限类
2) 实现has_permission方法
3) 实现体根据权限规则 确定有无权限
4) 进行全局或局部配置
认证规则
i.满足设置的用户条件,代表有权限,返回True
ii.不满足设置的用户条件,代表有权限,返回False
"""
# utils/permissions.py
from rest_framework.permissions import BasePermission
from django.contrib.auth.models import Group
class MyPermission(BasePermission):
def has_permission(self, request, view):
# 只读接口判断
r1 = request.method in ('GET', 'HEAD', 'OPTIONS')
# group为有权限的分组
group = Group.objects.filter(name='管理员').first()
# groups为当前用户所属的所有分组
groups = request.user.groups.all()
r2 = group and groups
r3 = group in groups
# 读接口大家都有权限,写接口必须为指定分组下的登陆用户
return r1 or (r2 and r3)
# 游客只读,登录用户只读,只有登录用户属于 管理员 分组,才可以增删改
from utils.permissions import MyPermission
class TestAdminOrReadOnlyAPIView(APIView):
permission_classes = [MyPermission]
# 所有用户都可以访问
def get(self, request, *args, **kwargs):
return APIResponse(0, '自定义读 OK')
# 必须是 自定义“管理员”分组 下的用户
def post(self, request, *args, **kwargs):
return APIResponse(0, '自定义写 OK')
频率组件
频率类源码
入口
# 1)APIView的dispath方法中的 self.initial(request, *args, **kwargs) 点进去
# 2)self.check_throttles(request) 进行频率认证
# 频率组件核心源码分析
def check_throttles(self, request):
throttle_durations = []
# 1)遍历配置的频率认证类,初始化得到一个个频率认证类对象(会调用频率认证类的 __init__() 方法)
# 2)频率认证类对象调用 allow_request 方法,判断是否限次(没有限次可访问,限次不可访问)
# 3)频率认证类对象在限次后,调用 wait 方法,获取还需等待多长时间可以进行下一次访问
# 注:频率认证类都是继承 SimpleRateThrottle 类
for throttle in self.get_throttles():
if not throttle.allow_request(request, self):
# 只要频率限制了,allow_request 返回False了,才会调用wait
throttle_durations.append(throttle.wait())
if throttle_durations:
# Filter out `None` values which may happen in case of config / rate
# changes, see #1438
durations = [
duration for duration in throttle_durations
if duration is not None
]
duration = max(durations, default=None)
self.throttled(request, duration)
自定义频率类
# 1) 自定义一个继承 SimpleRateThrottle 类 的频率类
# 2) 设置一个 scope 类属性,属性值为任意见名知意的字符串
# 3) 在settings配置文件中,配置drf的DEFAULT_THROTTLE_RATES,格式为 {scope字符串: '次数/时间'}
# 4) 在自定义频率类中重写 get_cache_key 方法
# 限制的对象返回 与限制信息有关的字符串
# 不限制的对象返回 None (只能放回None,不能是False或是''等)
短信接口 1/min 频率限制
频率:api/throttles.py
from rest_framework.throttling import SimpleRateThrottle
class SMSRateThrottle(SimpleRateThrottle):
scope = 'sms'
# 只对提交手机号的get方法进行限制
def get_cache_key(self, request, view):
mobile = request.query_params.get('mobile')
# 没有手机号,就不做频率限制
if not mobile:
return None
# 返回可以根据手机号动态变化,且不易重复的字符串,作为操作缓存的key
return 'throttle_%(scope)s_%(ident)s' % {'scope': self.scope, 'ident': mobile}
配置:settings.py
# drf配置
REST_FRAMEWORK = {
# 频率限制条件配置
'DEFAULT_THROTTLE_RATES': {
'sms': '1/min'
},
}
视图:views.py
# drf配置
REST_FRAMEWORK = {
# 频率限制条件配置
'DEFAULT_THROTTLE_RATES': {
'sms': '1/min'
},
}
路由:api/url.py
url(r'^sms/$', views.TestSMSAPIView.as_view()),
限制的接口
# 只会对 /api/sms/?mobile=具体手机号 接口才会有频率限制
# 1)对 /api/sms/ 或其他接口发送无限制
# 2)对数据包提交mobile的/api/sms/接口无限制
# 3)对不是mobile(如phone)字段提交的电话接口无限制