引入
看个例子:
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
这段代码实现了一个往数组里插入数据的功能。当数组满了之后,就是代码的count==array.length时,会用for循环遍历数组求和,并清空数组,将求和之后的sum值放到数组的第一个位置,然后再将新的数据插入。但如果一开始就有空闲空间,则直接将数据插入数组。
最好时间复杂度:数组中有空闲空间,只需要将数据插入到数组下标为count的位置即可,所以最好情况时间复杂度为O(1)
最坏时间复杂度:数组没有空闲空间,就需要先做一次数组的遍历求和,然后再将数据插入,所以最坏情况时间复杂度为O(n)
平均时间复杂度:答案是O(1),通过概率论的方法来分析
假设数组的长度是n,更加数据插入的位置的不同,可以分为n种情况,每种情况的时间复杂度是O(1),除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,此时时间复杂度是O(n),而且,这个n+1中情况发生的概率一样,都是1/(n+1),所以,更具加权平均的计算方法,求得的平均时间复杂度就是:
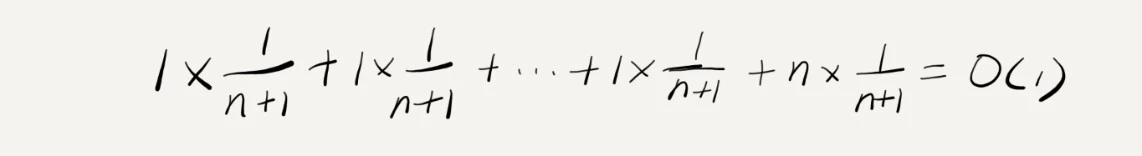
面的最好、最坏、平均时间复杂度的计算,理解起来应该都没有问题。但是这个例子里的平均复杂度分析其实并不需要这么复杂,不需要引入概率论的知识。
insert()函数在大部分情况下,时间复杂度都是O(1),只有个别情况下,复杂度才比较高,此外,O(1)时间复杂度的插入和O(n)时间复杂度的插入,出现的频率非常有规律,而且有一定的前后时序关系,一般都是一个O(n)插入之后,紧跟n-1个O(1) 的插入操作,循环往复。
针对这种情况,引入一种更加简单的分析方法:摊还分析法,通过瘫痪分析法得到的时间复杂度叫做:均摊时间复杂度
均摊时间复杂度
仍以上述数组中插入数据为例。每一次O(n)的插入操作,都会跟着n-1次O(1)的插入操作,所以把耗时多的那次操作均摊到接下来的n-1次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是O(1),这就是均摊分析的大致思路
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。