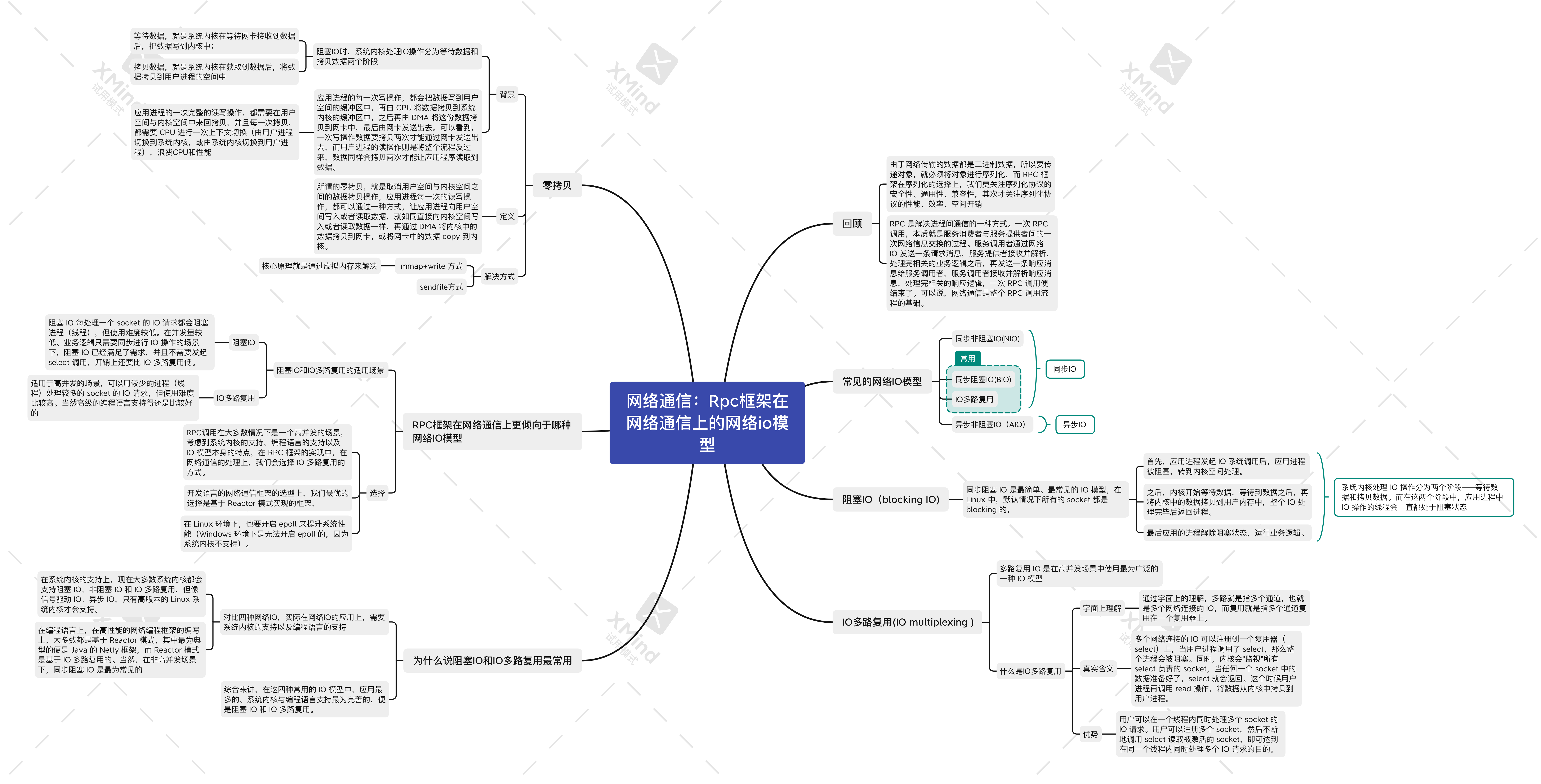
网络通信:RPC框架在网络通信上的网络IO模型
回顾
由于网络传输的数据都是二进制数据,所以要传递对象,就必须将对象进行序列化,而 RPC 框架在序列化的选择上,我们更关注序列化协议的安全性、通用性、兼容性,其次才关注序列化协议的性能、效率、空间开销
RPC 是解决进程间通信的一种方式。一次 RPC 调用,本质就是服务消费者与服务提供者间的一次网络信息交换的过程。服务调用者通过网络 IO 发送一条请求消息,服务提供者接收并解析,处理完相关的业务逻辑之后,再发送一条响应消息给服务调用者,服务调用者接收并解析响应消息,处理完相关的响应逻辑,一次 RPC 调用便结束了。可以说,网络通信是整个 RPC 调用流程的基础。
常见的网络IO模型
同步非阻塞IO(NIO)
同步阻塞IO(BIO)
IO多路复用
异步非阻塞IO(AIO)
同步IO
异步IO
阻塞IO(blocking IO)
同步阻塞 IO 是最简单、最常见的 IO 模型,在 Linux 中,默认情况下所有的 socket 都是 blocking 的,
首先,应用进程发起 IO 系统调用后,应用进程被阻塞,转到内核空间处理。
之后,内核开始等待数据,等待到数据之后,再将内核中的数据拷贝到用户内存中,整个 IO 处理完毕后返回进程。
最后应用的进程解除阻塞状态,运行业务逻辑。
系统内核处理 IO 操作分为两个阶段——等待数据和拷贝数据。而在这两个阶段中,应用进程中 IO 操作的线程会一直都处于阻塞状态
IO多路复用(IO multiplexing )
多路复用 IO 是在高并发场景中使用最为广泛的一种 IO 模型
什么是IO多路复用
字面上理解
通过字面上的理解,多路就是指多个通道,也就是多个网络连接的 IO,而复用就是指多个通道复用在一个复用器上。
真实含义
多个网络连接的 IO 可以注册到一个复用器(select)上,当用户进程调用了 select,那么整个进程会被阻塞。同时,内核会“监视”所有 select 负责的 socket,当任何一个 socket 中的数据准备好了,select 就会返回。这个时候用户进程再调用 read 操作,将数据从内核中拷贝到用户进程。
优势
用户可以在一个线程内同时处理多个 socket 的 IO 请求。用户可以注册多个 socket,然后不断地调用 select 读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。
为什么说阻塞IO和IO多路复用最常用
对比四种网络IO,实际在网络IO的应用上,需要系统内核的支持以及编程语言的支持
在系统内核的支持上,现在大多数系统内核都会支持阻塞 IO、非阻塞 IO 和 IO 多路复用,但像信号驱动 IO、异步 IO,只有高版本的 Linux 系统内核才会支持。
在编程语言上,在高性能的网络编程框架的编写上,大多数都是基于 Reactor 模式,其中最为典型的便是 Java 的 Netty 框架,而 Reactor 模式是基于 IO 多路复用的。当然,在非高并发场景下,同步阻塞 IO 是最为常见的
综合来讲,在这四种常用的 IO 模型中,应用最多的、系统内核与编程语言支持最为完善的,便是阻塞 IO 和 IO 多路复用。
RPC框架在网络通信上更倾向于哪种网络IO模型
阻塞IO和IO多路复用的适用场景
阻塞IO
阻塞 IO 每处理一个 socket 的 IO 请求都会阻塞进程(线程),但使用难度较低。在并发量较低、业务逻辑只需要同步进行 IO 操作的场景下,阻塞 IO 已经满足了需求,并且不需要发起 select 调用,开销上还要比 IO 多路复用低。
IO多路复用
适用于高并发的场景,可以用较少的进程(线程)处理较多的 socket 的 IO 请求,但使用难度比较高。当然高级的编程语言支持得还是比较好的
选择
RPC调用在大多数情况下是一个高并发的场景,考虑到系统内核的支持、编程语言的支持以及 IO 模型本身的特点,在 RPC 框架的实现中,在网络通信的处理上,我们会选择 IO 多路复用的方式。
开发语言的网络通信框架的选型上,我们最优的选择是基于 Reactor 模式实现的框架,
在 Linux 环境下,也要开启 epoll 来提升系统性能(Windows 环境下是无法开启 epoll 的,因为系统内核不支持)。
零拷贝
背景
阻塞IO时,系统内核处理IO操作分为等待数据和拷贝数据两个阶段
等待数据,就是系统内核在等待网卡接收到数据后,把数据写到内核中;
拷贝数据,就是系统内核在获取到数据后,将数据拷贝到用户进程的空间中
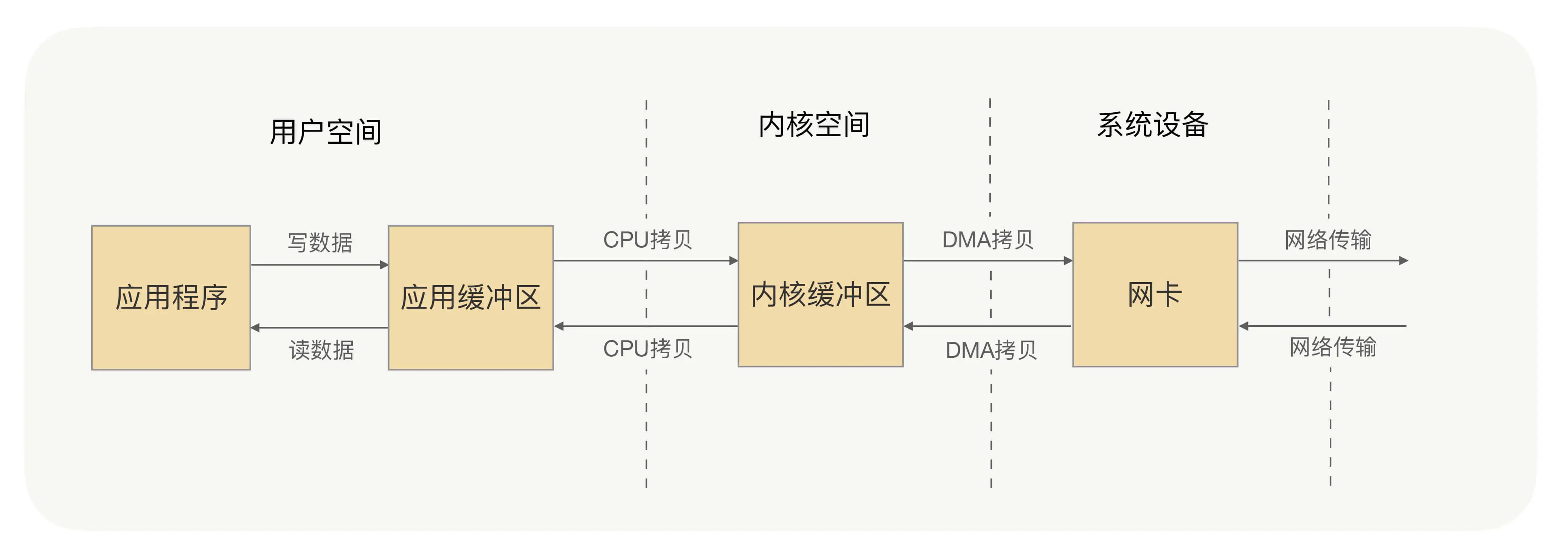
应用进程的每一次写操作,都会把数据写到用户空间的缓冲区中,再由 CPU 将数据拷贝到系统内核的缓冲区中,之后再由 DMA 将这份数据拷贝到网卡中,最后由网卡发送出去。可以看到,一次写操作数据要拷贝两次才能通过网卡发送出去,而用户进程的读操作则是将整个流程反过来,数据同样会拷贝两次才能让应用程序读取到数据。
应用进程的一次完整的读写操作,都需要在用户空间与内核空间中来回拷贝,并且每一次拷贝,都需要 CPU 进行一次上下文切换(由用户进程切换到系统内核,或由系统内核切换到用户进程),浪费CPU和性能
定义
所谓的零拷贝,就是取消用户空间与内核空间之间的数据拷贝操作,应用进程每一次的读写操作,都可以通过一种方式,让应用进程向用户空间写入或者读取数据,就如同直接向内核空间写入或者读取数据一样,再通过 DMA 将内核中的数据拷贝到网卡,或将网卡中的数据 copy 到内核。
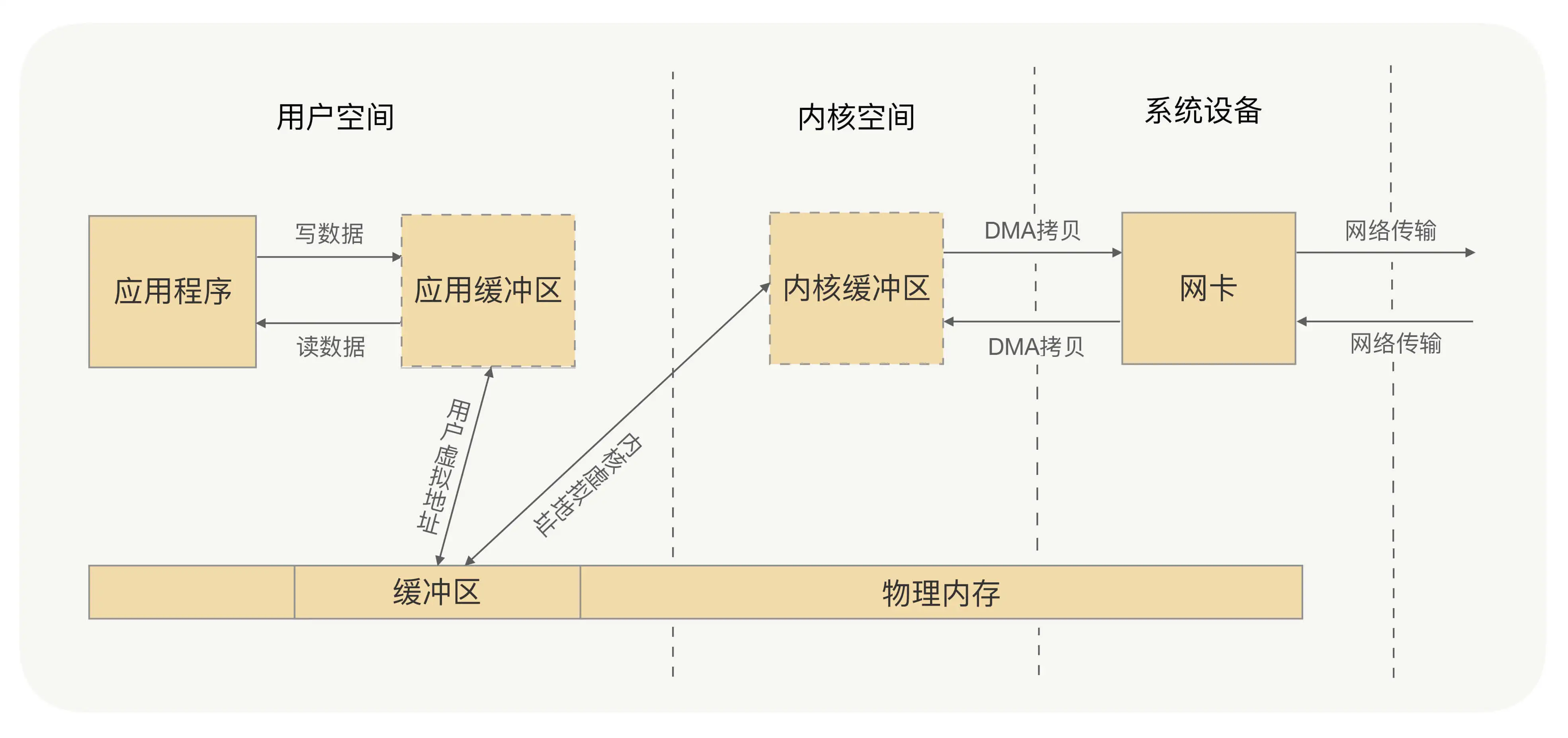
解决方式
1、mmap+write 方式
核心原理就是通过虚拟内存来解决
2、sendfile方式
Reactor可参考:https://www.cnblogs.com/whiteBear/p/15731844.html