前言
接上文,继续学习后续章节。细心的同学已经发现,我整理的并不一定是作者讲的内容,更多是结合自己的理解,加以阐述,所以建议结合原文一起理解。
第九章《普通索引和唯一索引,如何选择》
从查询和更新效率上看
通过唯一索引查询时:找到对应主键索引,就停止检索,返回数据。
通过普通索引查询时:找到第一个符合要求的记录后,还要继续往下查找,直至找到第一个不满足条件的记录。
从流程上看,似乎通过普通索引查询的效率比唯一索引低,当实际上这个差距微乎其微的,因为MySQL是以数据页为读取单位的。找到记录后,将记录所在的整个数据页都读到内存,找内存中查询的效率是很快的,两者的差距可以忽略不计的。
描述更新流程之前先跟你介绍下插入缓存change buffer(insert buffer):
change buffer 使用的缓冲池的内存。
当有数据要更新时,如果这个数据就在内存中,那么直接修改内存即可。如果不在内存中,则把更新的操作记录在change buffer中,当再来查询这个条更新的数据时,查询在内存的时候便可直接返回,不在内存的数据,需要先将数据页读取到内存,并依据change buffer的数据合并修正为最新的数据返回。
显然如果只更新内存,当MySQL宕机,数据是没有保障的,下面我们结合redo log、undo log,缓冲区,change buffer,表空间,梳理下当有数据要更新时,都做了哪些事?
1、当我们根据非唯一索引更新时,会先开启事务,然后查询内存中该条数据所在的数据页是否在内存中。
2、若存在时,直接更新内存,并同时将该条数据的最新结果记入在redo log中处于prepared状态,将更新前的数据状态记入在undo log中。
3、当undo log保存成功后,将redo log中状态改为commit状态,事务提交后,清除undo log,至此更新结束,返回结果。
4、若更新的数据不在内存中,那么就直接记入在change buffer中,后面的流程就是一样的。
这里只是大致的描述了下,一个更新流程,实际上还会涉及bin log,redo log buffer等,后面会继续更深入的梳理。
索引的选择
通过上面讲解可知由于唯一索引用不上change buffer的优化机制,因此如果业务可以接受,从性能角度出发我建议你优先考虑非唯一索引。当然,业务优先。
第十章《MySQL为什么有时候会选错索引》
我们知道索引的选择取决于优化器选择索引。
而优化器选择索引的目的,是找到一个最优的执行方案,并采用最小的代价去执行语句。比如扫描行数,扫描行数越少意味着访问磁盘的次数越少,消耗CPU资源越少。除此之外,是否使用临时表,是否排序等因素也是优化器的衡量标准之一。
若优化器选错了索引,大多情况下,是因为统计预计扫描行数出错导致的,文中模拟了一个导致扫描出错的场景,向我们展示了,选错索引导致的查询耗时变大的情况。
知道了问题出在哪,那针对的方法有:
1、通过analyze table 表名,命令来修正统计信息。
2、通过force index 强行指定使用哪个索引.
3、删除不必要的索引,或者通过SQL语句引导优化器选择正确的索引。
其实这章阐述的问题意义不在于,我们如何解决索引选错的问题,主要大家得理解其本质,本身这类问题发生的概率极其小,即使发生了我们也有排查的思路。
第十一章《怎么给字符串字段加索引?》
当你需要给一个长字符串加索引时,怎么如何处理?比如邮箱,身份证等。
首先当我们给一个字符串加索引时,应该考量的是改字段的区分度高不高,比如邮箱这个字段,我们可以发现邮箱的后面几位@XX.COM大部分是一致的市面上常用邮箱可能也就十几种。如果我们给整个邮箱字段加索引,那么索引说占的空间就打,一页上存储的索引数量也就小。
所以我们以考虑建立前缀索引:
mysql> alter table SUser add index index2(email(6));
但具体截取几位,还是得再库里通过distinct验证下区分度.选择合适的位数。
那么使用前缀索引会有哪些问题?
当我们使用覆盖索引的时候,通过email字段检索,就不需要回表查询,但是使用前缀索引,邮箱字段不全,还需要回表查询一次,便多了一次查询。
所以前缀索引不适合可以覆盖索引的场景。
那么当身份证这样的字段,如何建索引?
我们可以发现身份证前6位很多地区都是一致的,索引如果使用前缀索引,显然不合适,然后一般后面的几位区分度是很大的,所以我们可以考虑,存储的时候,倒序存储再建立前缀索引。这样索引占用的空间就大大减少了。
还有一种方案就是新建一个字段,存储身份证的hash值,通过crc32函数计算。但是hash之后还是有可能不一样的身份证算出来的结果一样,但是这个概念很小很小, 所以查询需要再验证身份证是否一样。
其实通过上面的例子,可以总结出,我们创建索引的最终目的,一是尽量让区分度大的字段,提升查询效率,二在不影响查询效率的情况下,尽量索引字段小一点。这个可以是以后我们将索引时总要的衡量标准。
总结:
1 . 直接创建完整索引,这样可能比较占用空间;
2 . 创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引;
3 . 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题;
4 . 创建hash字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
第十二章《为什么我的MySQL会“抖”一下》
通过之前的学习我们知道,当你要插入或更新一条数据时,MySQ并不一定会立即写入到表数据中,一般会做两个操作,一更新缓冲池中对应的数据,二记录在redo log中。然后会选择合适的时机,再写入到磁盘。
这样实际表中的数据和缓冲池中的数据是不一致的,这就所谓的脏页。
所以当MySQL需要刷新脏页的时候,就可能出现我们所谓的“抖”了一下。
那么MySQL什么时候会触发刷脏页呢?
1、当redo log日志满的时候,这时候为了能继续记录,就需要把redo log中清理部分数据,这个清理的前提就需要把不一致的数据刷新到磁盘。这个时候由于redo log已满,就不能再写了,需要停止一些更新操作,等待清理,这是很严重的,所以MySQL一般会尽量避免redo log被写满的情况。
2、内存满了,当需要读取的数据不再内存中是,就需要从磁盘中读取数据页并加载到内存中,这时候发现内存已经满了,就需要腾出内存,淘汰一些数据页(最久不使用的),如果是脏页就需要,刷磁盘。当然实际中,我们便不会等内存满了才会刷脏页。
3、当mysql觉得系统空闲了,也会主动刷新脏页。
4、当MySQL要退出时,也会把脏页刷新到磁盘。
InnoDB刷脏页的控制策略
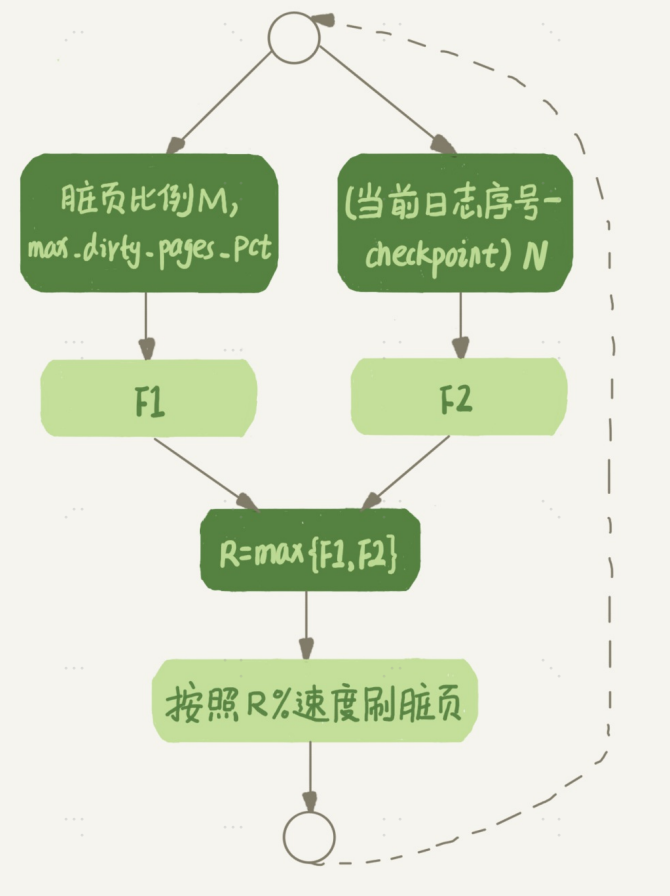
InnoDB的刷盘速度就是要参考这两个因素:一个是脏页比例,一个是redo log写盘速度。
参数innoDB_max_dirty_pages_pct是脏页上限比例,默认是75%
InnoDB每次写入的日志都有一个序号,当前写入的序号跟checkpoin t对应的序号之间的差值,我们假设为N 。InnoDB会根据这个N 算出一个范围在0到100之间的数字,这个计算公式可以记为F2 ( N ) 。F2 ( N ) 算法比较复杂,你只要知道N 越大,算出来的值越大就好了。
然后,根据上述算得的 根据上述算得的 F1(M) F1(M) 和F2(N) F2(N) 两个值,取其中较大的值记为 两个值,取其较大的值记为 R,之后引擎就可以按 ,之后引擎就可以按照innodb_io_capacit y innodb_io_capacit y定义的能力乘以 定义的能力乘以 R%来控制刷脏页的速度。