注:本文是在Hadoop单机环境部署完毕,mysql安装完毕的情况下进行。点击下面链接可查看。(感觉之前做的笔记有点杂乱。。。。。。。。)
mysql安装(版本5.7)
目录:
准备工作
1.开启hadoop相关进程。hdfs 和 yarn 以及历史服务器
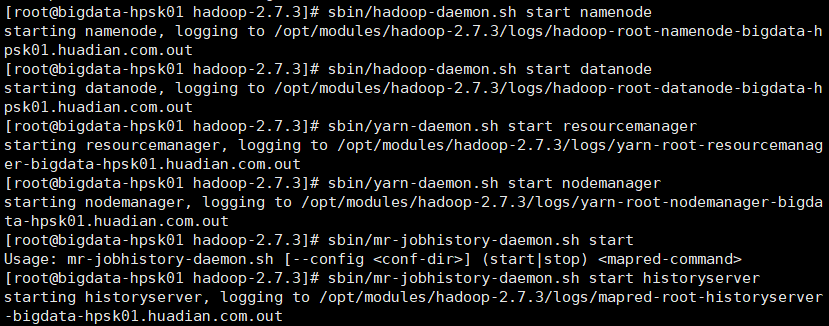
2.开启Mysql服务
service mysqld start
hive简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,提交应用到YARN集群上,读取存储在HDFS上的数据,进行分析处理,所以说hive是建立在hadoop框架之上的提供sql方式分析数据的框架。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
官网:hive.apache.org 部分配置参考官网案例。
hive安装
我的版本:1.2.1 底层使用MapReduce 下载地址:http://archive.apache.org/dist/hive/ 2.x版本底层使用mapreduce spark(官方推荐) Tez
1.上传解压并重命名
用Linux自带的上传工具上传hive压缩包。

解压后重命名为hive1.2。用mv命令

2.创建数据仓库并赋予写权限。先到hadoop-2.7.3安装目录下执行下面命令。 因为hive-default.xml.template配置文件中默认设置的的数据仓库就是/user/hive/warehouse
bin/hdfs dfs -mkdir /tmp bin/hdfs dfs -mkdir /user/hive/warehouse bin/hdfs dfs -chmod g+w /tmp bin/hdfs dfs -chmod g+w /user/hive/warehouse
hive-default.xml.template中


3.配置文件
到hive安装目录下的conf文件夹中复制hive-env.sh.template,粘贴为hive-env.sh

编辑hive-env.sh。配置hadoop安装路径和hive的配置目录

4.配置全局环境变量
vim /etc/profile
在末尾添加如下配置:
# HIVE HOME
export HIVE_HOME=/opt/modules/hive1.2
export PATH=${PATH}:${HIVE_HOME}/bin:${HIVE_HOME}/conf
使配置生效
source /etc/profile
5.启动hive bin/hive
跳坑里去了。。。一连串错误 都提示元数据数据库metastore_db不能创建
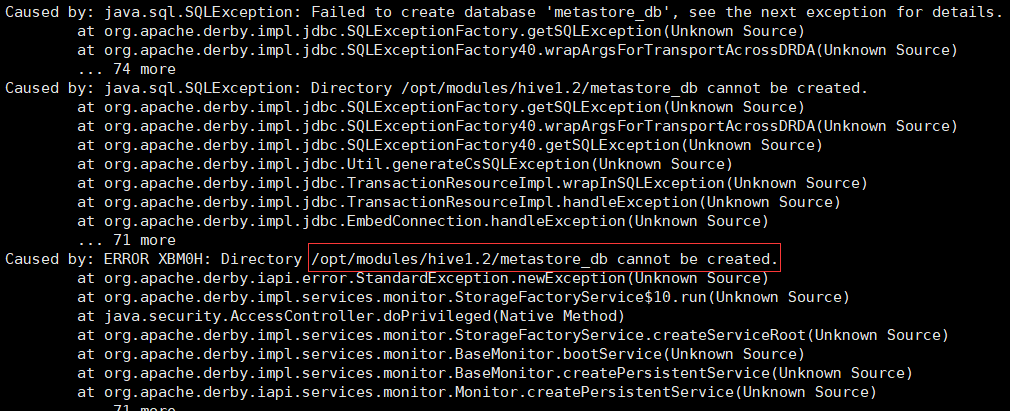
后来发现hive安装目录的文件权限全是root
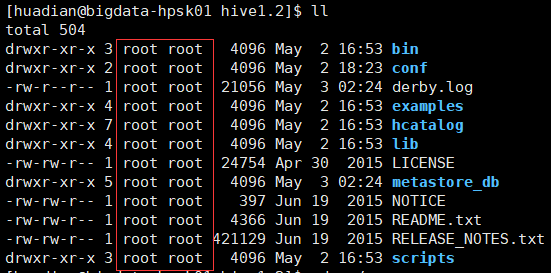
修改用户和用户组为huadian用户
chown -R huadian:huadian /opt/modules/hive1.2
出现下图就成功

hive入门
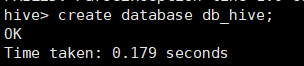
1.创建表
创建数据库
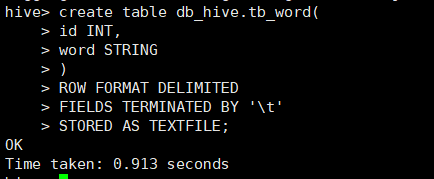
创建表
create table db_hive.tb_word( id INT, word STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' # 这句话表示字段之间用制表符分割 STORED AS TEXTFILE;
2.导入数据
首先在datas目录下创建一个测试文件 并编辑

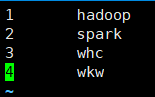
最后导入数据
LOAD DATA LOCAL INPATH '/opt/datas/word.data' INTO TABLE db_hive.tb_word;

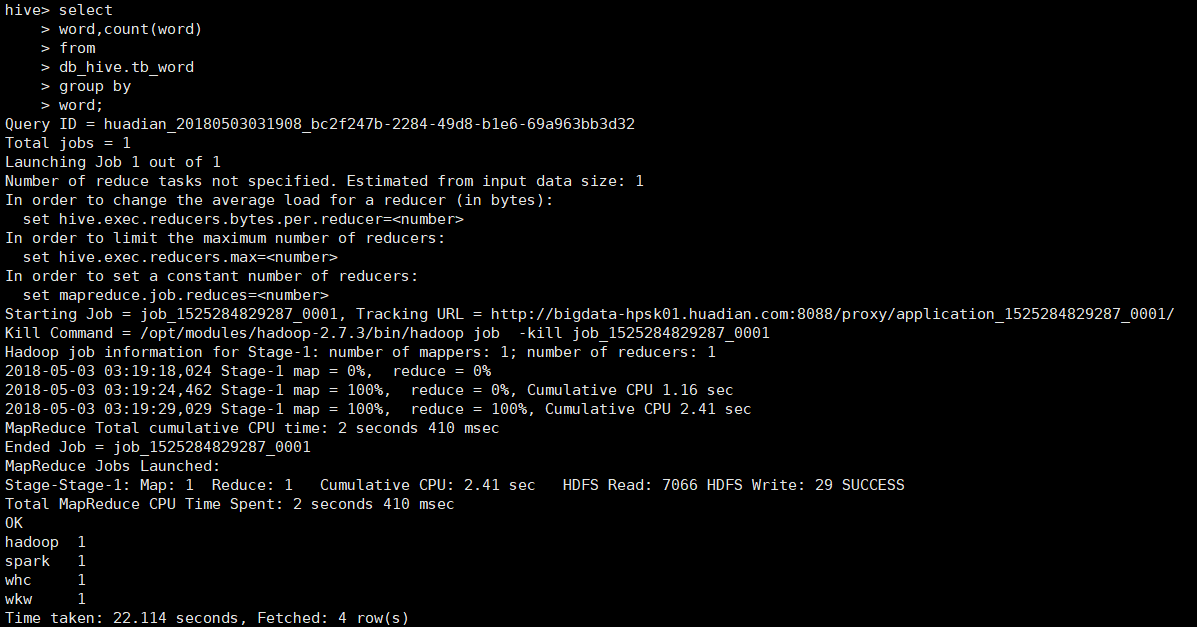
3.实现业务(写sql)
使用hive来统计word出现次数
select word,count(word) from db_hive.tb_word GROUP BY word
使用Mysql存储元数据
因为hive默认使用derby属于嵌入式数据,每次只支持一个会话。通常将元数据metaStore存储在Mysql中,同时支持了多个会话进入hive
1.修改hive配置文件 复制模板重命名为hive-site.xml

具体配置:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata-hpsk01.huadian.com/metaStore?createDatabaseIfNotExist=true<value/>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver<value/>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root<value/>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456<value/>
</property>
</configuration>
2.在hive安装目录下的lib文件夹下导入mysql数据库驱动jar包
3.重新进入hive
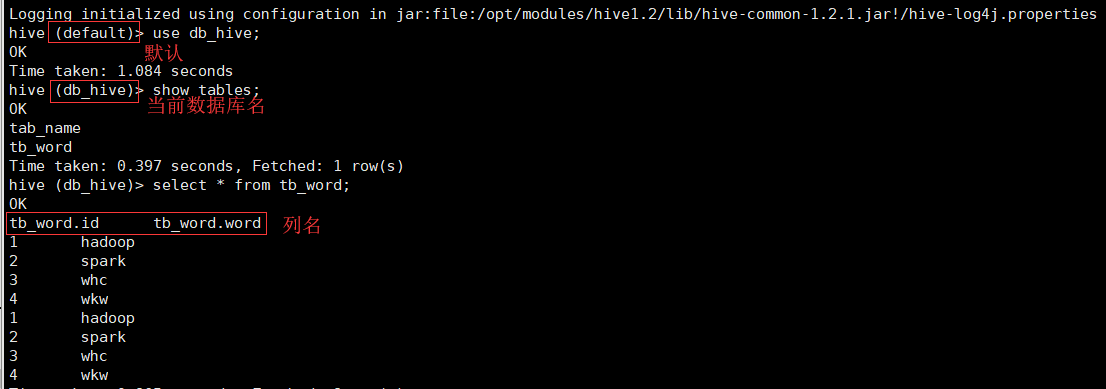
额外配置方便开发调试
在hive-site.xml中添加配置:
<!--显示列名-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<!--显示当前操作的数据库-->
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
bin/hive 重新进入Hive
案例
Python和R语言,谁更适用于大数据Spark/Hadoop和深度学习?
数据下载链接:http://www.kdnuggets.com/aps/sw17-top11-dl-sh.anon.csv
下载数据后上传到 /opt/datas目录下
1.在db_hive数据库下创建表
CREATE TABLE db_hive.tb_language_count ( id_number string, area string, python string, r string, sql_str string, rapidminer string, excel string, spark string, mangshe string, tensorflow string, scikit_learn string, tableau string, knime string, deep string, spark_hadoop string, ntools int, votetools string )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY ' '
2.导入数据 有三种方式 这里我用了第一种
(1)导入本地路径下的文件 刚才已经上传到了/opt/datas目录下
LOAD DATA LOCAL INPATH '/opt/datas/sw17-top11-dl-sh.anon.csv' INTO TABLE db_hive.tb_language_count;
(2)导入hdfs下的文件 先上传文件到hdfs系统中(往hdfs上传文件的代码我就不贴了)。注:导入后hdfs上的文件会不见 相当于剪切
LOAD DATA INPATH '/user/huadian/sw17-top11-dl-sh.anon.csv' INTO TABLE db_hive.tb_language_count
(3)直接上传文件到HDFS对应的数据库,对应的数据表目录下
3.统计使用python开发大数据的人数
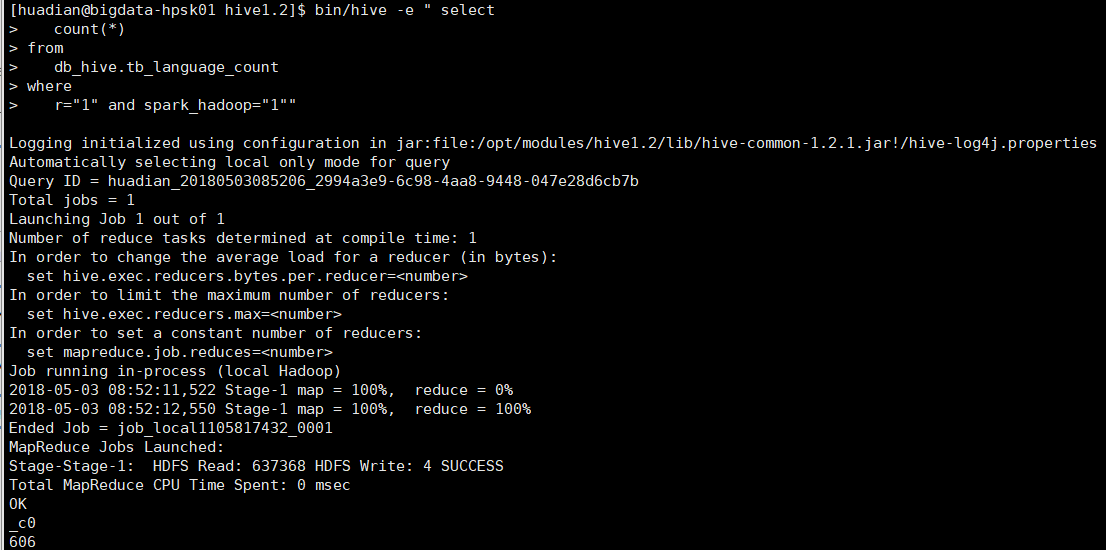
select count(*) from db_hive.tb_language_count where python="1" and spark_hadoop="1"
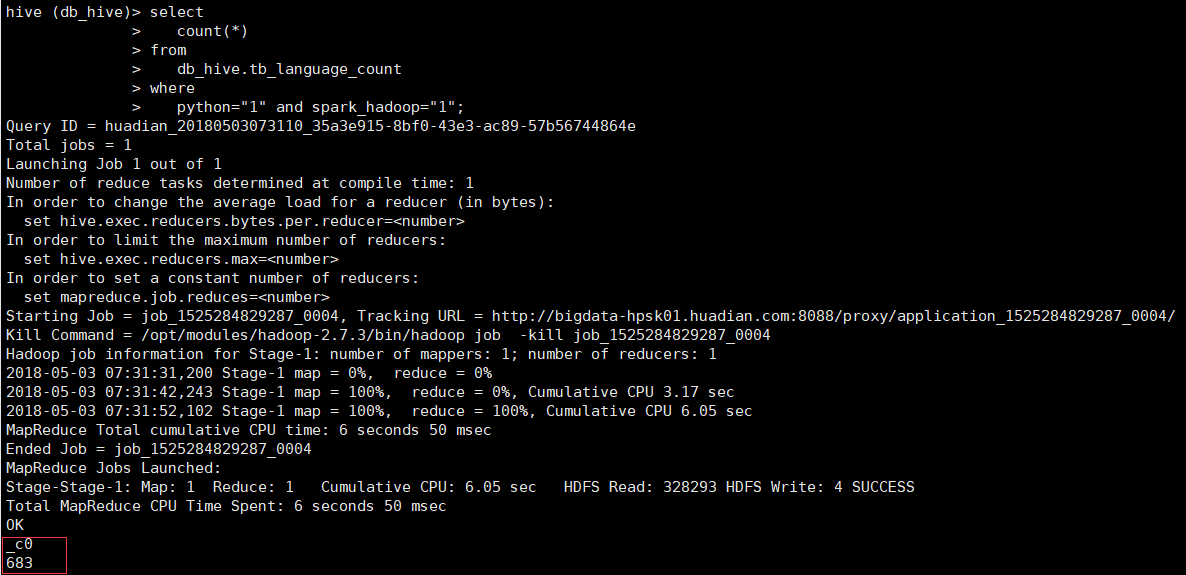
4.统计R语言开发大数据的人数
select count(*) from db_hive.tb_language_count where r="1" and spark_hadoop="1"
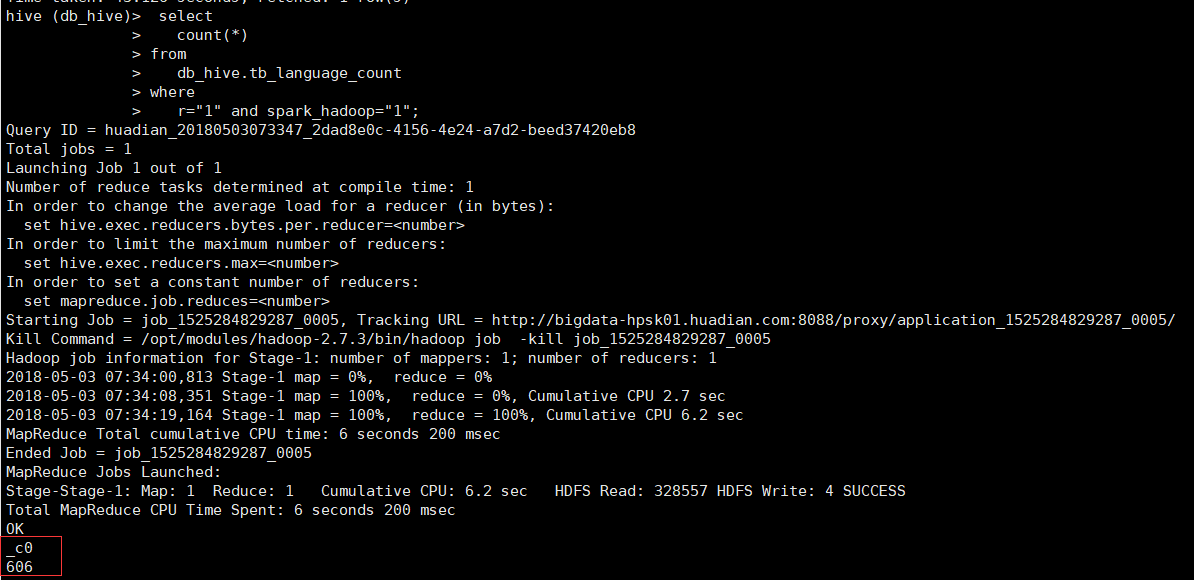
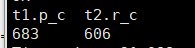
5.一并统计 通过id连接2个统计结果 会执行三次查询
select t1.p_c,t2.r_c from (select "1" as id ,count(*) as p_c from db_hive.tb_language_count where python="1" and spark_hadoop="1" ) t1 join (select "1" as id ,count(*) as r_c from db_hive.tb_language_count where r=1 and spark_hadoop="1" ) t2 on t1.id = t2.id
分析结果的保存,把运行结果保存到第二张表中
这里以统计使用python开发大数据的人数为例
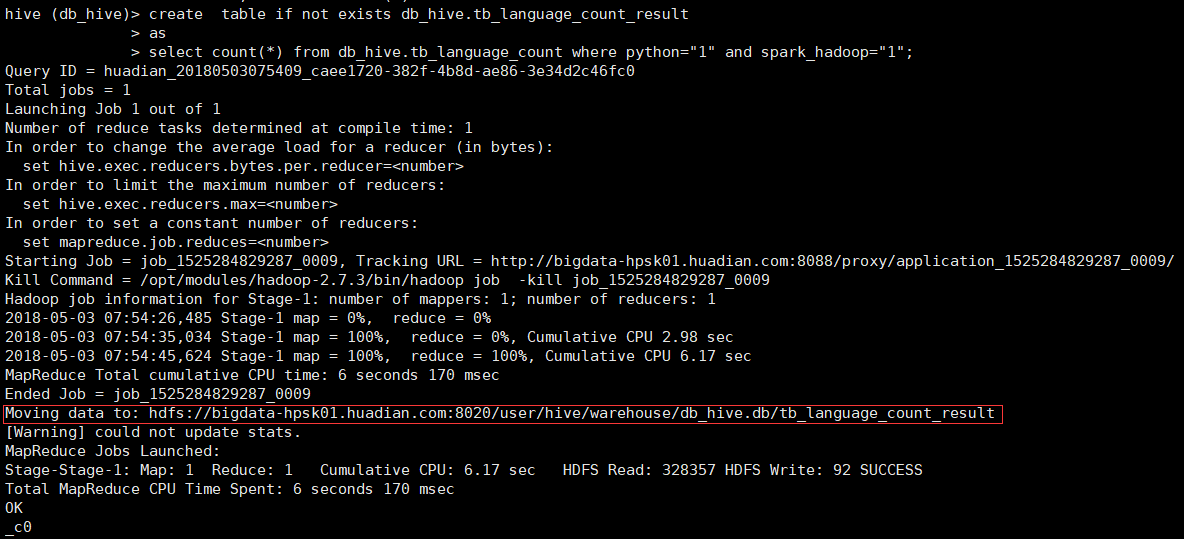
可以到hdfs页面上看到 我们刚创建的表以及运行结果
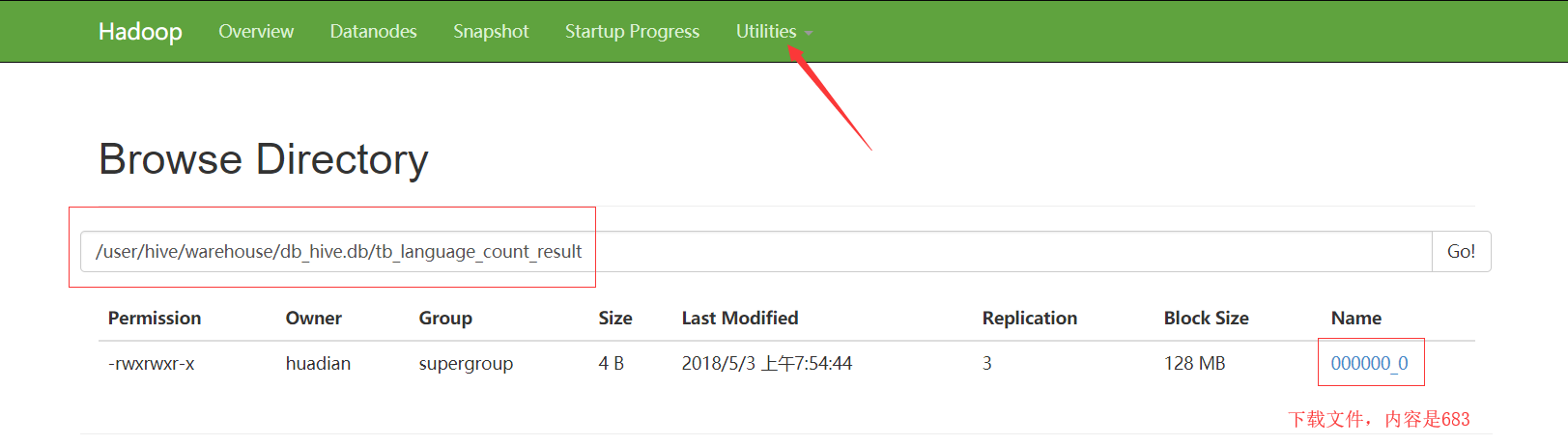
hive运行模式
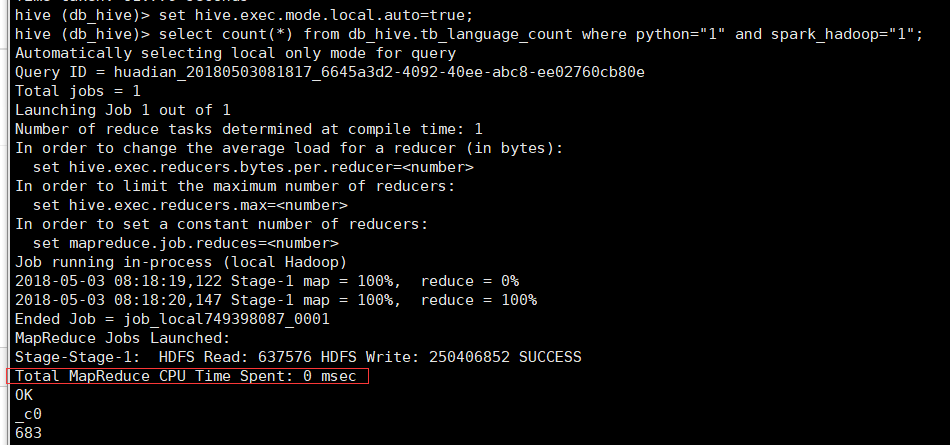
设置为本地模式,当MapReduce处理的数据大小小于128MB或者MapTask个数小于5个,自动运行在本地模式下,提高运行速度。设置方式有2种
1.hive客户端设置,但只是当前会话有效
进入hive数据库后设置
set hive.exec.mode.local.auto=true
可以看到几乎没花时间
2.在配置文件hive-site.xml添加如下内容,永久设置有效
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Let Hive determine whether to run in local mode automatically</description>
</property>
编写hive脚本
抵达hive安装目录,执行下面的命令
bin/hive -e "sql语句"
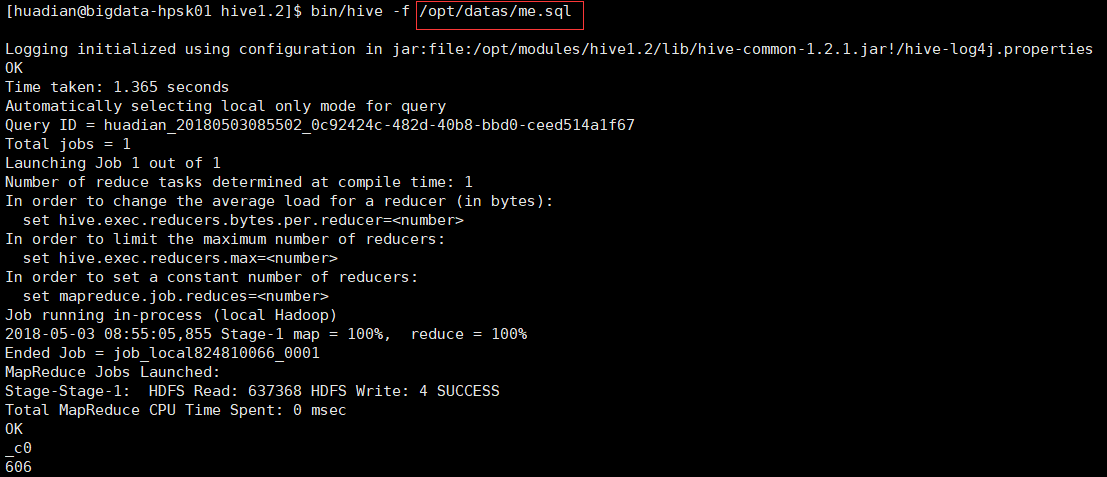
bin/hive -f xxx.sql xxx.sql里内容为自己编写的sql语句
编辑me.sql文件 并上传到/opt/datas/ 目录下

表的类型
管理表(内部):例如CREATE TABLE db_hive.tb_word
外部表:CREATE EXTERNAL TABLE db_hive.tb_word
区别:删除表的时候管理表元数据和数据文件都被删除,外部表只能删除元数据。