文件的操作;
python中操作文件,需要先使用pen()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写
file object =open("filename.txt",mode="r", encoding="utf-8")
filename,可以用绝对路径和相对路径表示
encoding="utf-8",encoding表示编码集. 根据文件的实际保存编码进行获取数据
mode决定了打开文件的模式:只读,写入,追加等,参考如下数据:
t 文本模式 (默认)。
x 写模式,新建一个文件,如果该文件已存在则会报错。
b 二进制模式。
+ 打开一个文件进行更新(可读可写)。
U 通用换行模式(不推荐)。
r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。
r+ 打开一个文件用于读写。文件指针将会放在文件的开头。
rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。
w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。

所有从文件里读出来的内容都是字符串;
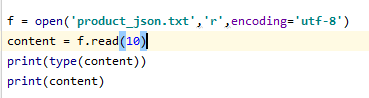
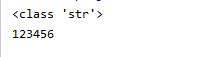
1、read(),每次读取整个文件,返回为一个字符串,可以read(size),size是字节
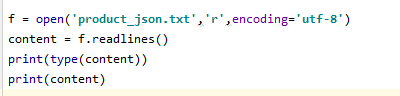
2、readlines()也是读取整个文件,返回一个列表,每行为列表的一个元素, 每行的换行符也读出来‘ ’

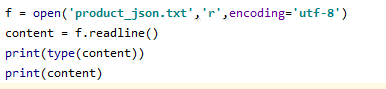
3、readline(),每次读取一行,返回的也是一个字符串,
4、write(),和read(),readline()对应,是将字符串写入到文件中
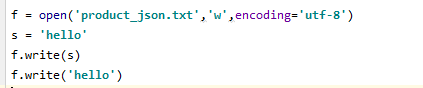
5、writelines(),和readlines(),方法对应,接收一个字符串列表作为参数,写入到文件中,换行符不会自动加入,需要显式的加入换行符

with open() as f , 写法,不用关闭文件;
列表生成式;
l1 = [ i for i in range(10)]
l2 = [str(i) for i in range(65,91)]
l3 = [i*i for i in range(97,123)]
l = [(1, 20), (3, 0), (9, 10), (2, -1)]
l.sort(key=lambda x: x[1]) # 按列表中元组的第二个元素排序
def square(x): return x**2 s = map(square,[1,2,3,4,5]) print(s) #[1, 4, 9, 16, 25]
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。 python3返回的是迭代器
def is_odd(n): return n %2 == 1 n = filter(is_odd,[1,2,3,4,5,6]) #[1, 3, 5]
__init__.py中变量:__all__关联了一个模块列表,当执行from xx import *时,就会导入列表中的模块,__all__ = ['t1', 't2']
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
import json
data1 = [ { 'key1' : '球鞋', 'key2' : 'vanss', 'key3' : 665 } ]
data2 = { 'key1' : '球鞋', 'key2' : 'vanss', 'key3' : 665 }
data3 = 'abcdef'
data4 = False
data5 = 123456.3333
json1 = json.dumps(data1,indent=2,ensure_ascii=False)
json2 = json.dumps(data2,indent=2,ensure_ascii=False)
json3 = json.dumps(data3)
json4 = json.dumps(data4)
json5 = json.dumps(data5)


json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型; json对象格式需要转化为str
import json
json1 = '{"key1": "球鞋", "key2": "vanss", "key3": 665}'
data = json.loads(json1)
print(data)
{'key1': '球鞋', 'key2': 'vanss', 'key3': 665}
json.dump()
将一个python值转换成json格式并存入指定文件,用法如下:
import json
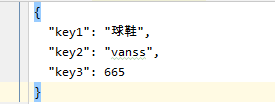
json1 = {"key1": "球鞋", "key2": "vanss", "key3": 665}
with open('tjs.txt','w') as f:
json.dump(json1,f,ensure_ascii=False,indent=2)
json.load()
将一个指定json格式文件转换成python值。比如把前一个例子中data.json文件数据还原成dict格式数据:
import json
with open('tjs.txt','r') as f:
data = json.load(f)
print(type(data))
print(data)

Python进制转换;
#十进制转化为二进制、八进制、十六进制
a = 10
ato2 = bin(a)
ato8 = oct(a)
ato16 = hex(a)
print(ato2) // print(ato8) //print(ato16)

#二进制、八进制、十六进制 转化为十进制
a2 = '101010'
a8 = '0o12'
a16 = '0x5'
a2to10 = int(a2,2)
a8to10 = int(a8,8)
a16to10 = int(a16,16)
print(a2to10)
print(a8to10)
print(a16to10)