替换操作 replace
- 替换操作可以同步作用于Series和DataFrame中
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
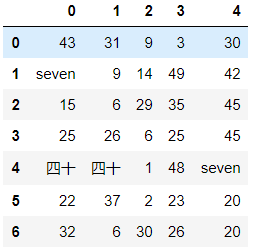
单值替换
df = DataFrame(data=np.random.randint(0,50,size=(7,5)))
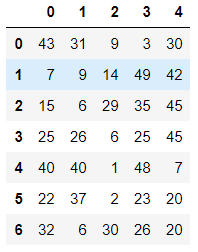
# 普通替换 df.replace(to_replace=7, value='seven')
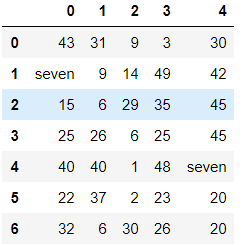
# 按列指定单值替换 df.replace(to_replace={0:7}, value='seven')
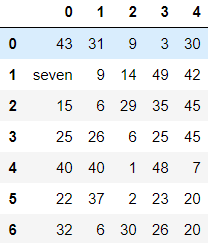
多值替换
# 字典替换(推荐使用) df.replace(to_replace={7:"seven",40:"四十"}) # 列表替换 df.replace(to_replace=[7,40],value=['seven','四十'])
映射操作 map
map是Series的方法,只能被Series调用
- 概念:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定(给一个元素值提供不同的表现形式)
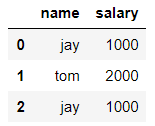
- 创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名
dic = { 'name':['jay','tom','jay'], 'salary':[1000,2000,1000] } df = DataFrame(data=dic)
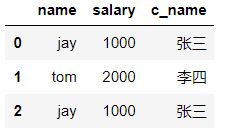
#给jay和tom起两个中文名字 #映射关系表:表明了映射关系 dic = { 'jay':'张三', 'tom':'李四' } df['c_name'] = df['name'].map(dic)
运算工具
Series的方法apply也可以像map一样充当运算工具
- 定义一个方法将它放到map或apply方法中,会将Series中每个元素传到函数中
- apply充当运算工具效率要远远高于map,并且apply既可以用在Series也可以用在DataFrame
超过300部分的钱缴纳50%的税,计算每个人的税后薪资
def after_salary(s): if s > 300: return s - (s-300) * 0.5 return s df['after_salary'] = df['salary'].map(after_salary)
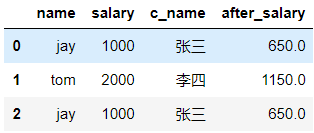
df['salary'].apply(after_salary) 0 650.0 1 1150.0 2 650.0 Name: salary, dtype: float64
随机抽样 take
- take() task中的axis参数含义和drop系列的函数一致
- np.random.permutation( n) 返回0到n-1之间的乱序序列
df = DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C']) np.random.permutation(3) #返回0-2之间的乱序序列 array([2, 0, 1]) # 对原始数据进行打乱,打乱:是对索引打乱 #对行列索引进行打乱并进行随机抽样抽取前10个 df.take(indices=np.random.permutation(3),axis=1).take(indices=np.random.permutation(100),axis=0)[0:10]
数据的分类处理 分组groupby
数据分类处理的核心:
- groupby()函数可以进行分组
- groups属性可以查看分组情况
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
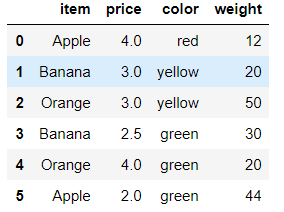
# by 提供了分组条件,通过水果的种类进行分组 df.groupby(by='item') <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x00000271D9577390> #查看分组结果 df.groupby(by='item').groups {'Apple': Int64Index([0, 5], dtype='int64'), 'Banana': Int64Index([1, 3], dtype='int64'), 'Orange': Int64Index([2, 4], dtype='int64')}
分组聚合
分组的目的就是为了后续对各个小组的聚合计算
计算每一种水果的平均价格
# 计算每一种水果的平均价格 df.groupby('item').mean()['price'] # 不推荐使用上面这种,进行了多余计算,浪费运算成本,# 推荐使用下边这种 df.groupby(by='item')['price'].mean() item Apple 3.00 Banana 2.75 Orange 3.50 Name: price, dtype: float64
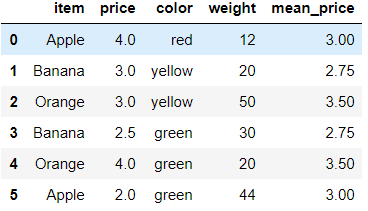
将每一种水果的平均价格计算出来然后汇总到源数据中
mean_price = df.groupby('item').mean()['price'] # 直接将其转成字典 mean_price_dic = mean_price.to_dict() {'Apple': 3.0, 'Banana': 2.75, 'Orange': 3.5} # 通过映射,映射到原数据 df['mean_price'] = df['item'].map(mean_price_dic)
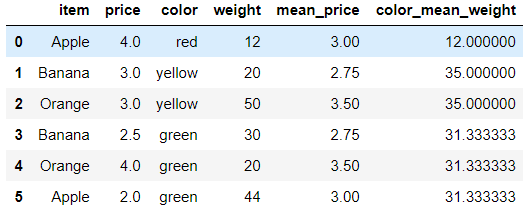
求出每一种颜色水果的平均重量,将其汇总到源数据中
# 通过color分组计算平均重量并转成字典,通过color映射汇总到原数据 df['color_mean_weight'] = df['color'].map(df.groupby(by='color')['weight'].mean().to_dict())
高级数据聚合
- 使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
apply和transform的区别:
- transform返回的结果是经过映射后的结果
- apply返回的是没有经过映射的结果
# 定义的方法需要作用到运算工具中 def my_mean(s): # s是一组数据 sum = 0 for i in s: sum += i return sum / len(s) # transform和apply就是运算工具 # transform返回的是映射后的结果,直接可以汇总到原数据 df.groupby(by='item')['price'].transform(my_mean) 0 3.00 1 2.75 2 3.50 3 2.75 4 3.50 5 3.00 Name: price, dtype: float64 # apply返回的是没有映射的结果,需要通过map映射才能汇总到原数据 df.groupby('item')['price'].apply(my_mean) item Apple 3.00 Banana 2.75 Orange 3.50 Name: price, dtype: float64
数据加载
读取type-.txt文件数据
- header 参数header默认是将数据第一行作为列索引,指定None后使用隐式索引
- sep 参数sep指定数据通过什么分割
pd.read_csv('./data/type-.txt')

# 指定header等于None不使用第一行作列索引,使用隐式索引 pd.read_csv('./data/type-.txt', header=None)

# 指定sep通过"-"分割数据 pd.read_csv('./data/type-.txt', header=None, sep='-')
读取数据库中的数据
# 连接数据库,获取连接对象 import sqlite3 conn = sqlite3.connect('./data/weather_2012.sqlite') # 读取库表中的数据值, 参数(sql语句,连接对象) pd.read_sql('select * from weather_2012', conn) # 将数据写入数据库,参数(表名,连接对象) text_df.to_sql('text_df', conn) pd.read_sql('select * from text_df', conn)
透视表 pivot_table
- 透视表是一种可以对数据动态排布并且分类汇总的表格格式。在pandas中数据透视表被称作pivot_table。
- 透视表的优点:
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
- pivot_table有四个最重要的参数index、values、columns、aggfunc
数据读取
# 需要指定引擎和编码,否则会报错乱码 df = pd.read_csv('./data/透视表-篮球赛.csv', engine='python', encoding='utf-8')
index参数
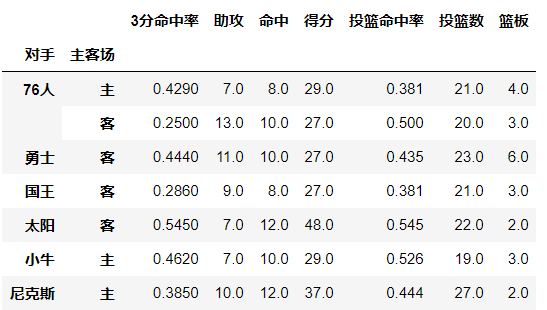
分类汇总的分类条件,每个pivot_table必须拥有一个index
# 想看看哈登对阵同一对手在不同主客场下的数据,分类条件为对手和主客场 df.pivot_table(index=['对手','主客场'])
values参数
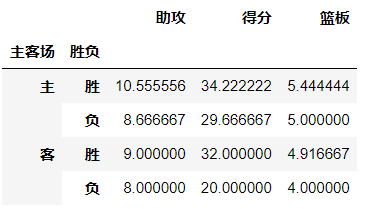
对计算的数据进行筛选
# 如果我们只需要哈登在主客场和不同胜负情况下的得分、篮板与助攻三项数据 df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'])
aggfunc参数
设置对数据聚合时使用的函数
- 当我们未设置aggfunc时,它默认aggfunc='mean'计算均值
# 想获得哈登在主客场和不同胜负情况下的总得分、总篮板、总助攻时: # 将aggfunc参数设为sum,就是对数据求和 df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'], aggfunc='sum')
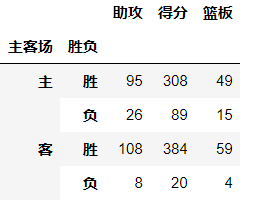
columns参数
设置列层次字段, 对values字段进行分类
# 获取所有队主客场的总得分 df.pivot_table(index='主客场',values='得分', aggfunc='sum')

# 查看主客场下的总得分的组成元素是谁 df.pivot_table(index='主客场', values='得分', aggfunc='sum', columns='对手')

# fill_value 将空值填充 df.pivot_table(index='主客场', values='得分', aggfunc='sum', columns='对手',fill_value=0)

交叉表 crosstab
- 是一种用于计算分组的特殊透视图,对数据进行汇总
- pd.crosstab(index,colums)
- index:分组数据,交叉表的行索引
- columns:交叉表的列索引
df = DataFrame({'sex':['man','man','women','women','man','women','man','women','women'],
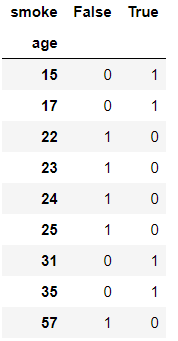
'age':[15,23,25,17,35,57,24,31,22],
'smoke':[True,False,False,True,True,False,False,True,False],
'height':[168,179,181,166,173,178,188,190,160]})
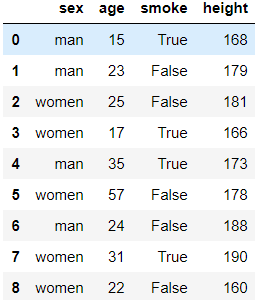
# 求出各个性别抽烟的人数 pd.crosstab(index=df.smoke,columns=df.sex)

# 求出各个年龄段抽烟人情况 pd.crosstab(index=df.age, columns=df.smoke)