|
开始 |
筛选索引是SQL Server 2008中的一种新功能,它是对表中的部分行进行索引。
基本语法:
|
create nonclustered index index_name on <object> (columns) where <filter_predicate> |
在一些特定的应用环境下,筛选索引与传统的全表非聚集索引相比,具有以下优点。
-
提高了查询性能和计划质量
-
减少了索引存储开销
-
减少了索引维护开销
接下来,我以例子来说明这三方面的优点。
|
提高了查询性能和计划质量 |
在数据库TestDB上创建两个表(table_a & table_b),而且每一个表都有相同的记录行(各100W行记录)。可以参见下面的测试脚本SQL:
|
use TestDB go if object_id('table_a') is not null drop table table_a if object_id('table_b') is not null drop table table_b go create table table_a (id int identity,col1 int,col2 nvarchar(128),constraint pk_table_a primary key(id)) create table table_b (id int identity,col1 int,col2 nvarchar(128),constraint pk_table_b primary key(id)) go insert into table_a(col1,col2) select top(1000000) a.object_id as col1,b.name as col2 from sys.all_objects a, sys.all_columns b go insert into table_b(col1,col2) select col1,col2 from table_a go |
在Microsoft SQL Server Management Studio 新建一个查询,并执行上面的SQL语句。
-
没有索引情况:
假设我要查,条件等于"col1 between -200 and 10"的id & col1记录,那么对应SQL语句是:
|
select id,col1 from table_a a where a.col1 between -200 and 10 |
为了能够跟踪到执行计划情况和IO信息,我这里设置了"set statistics profile,io on":
|
use TestDB go set statistics profile,io on select id,col1 from table_a a where a.col1 between -200 and 10 set statistics profile,io off go |
执行结果返回17540行记录,在执行计划过程,采用聚集索引扫描(pk_table_a),IO逻辑读取4311次:


图1.
-
筛选索引 Vs. 全表非聚集索引:
为了提升查询性能,通常会在字段col1上创建一个非聚集索引,如(ix_table_a_col1):
|
create nonclustered index ix_table_a_col1 on dbo.table_a(col1) |
同时,为了让筛选索引和全表非聚集索引进行比较,我在表table_b上创建了一个筛选索引,如(ix_table_b_col1_Filtered):
|
create nonclustered index ix_table_b_col1_Filtered on dbo.table_b(col1) where col1>=-200 |
接下来,要查询两个表中"col1 between -200 and 10"的id & col1记录:
|
use TestDB go set statistics profile,io on select id,col1 from table_a a where a.col1 between -200 and 10 select id,col1 from table_b a where a.col1 between -200 and 10 set statistics profile,io off go |

图2.
图2. 从表table_a和表table_b的实际执行计划统计信息中,看TotalSubtreeCost(所有子操作的预计开销合计)数据,使用筛选索引的table_b(TotalSubtreeCost=0.05036455)明显低于于使用全表非聚集索引的table_a(TotalSubtreeCost=0.02331454)。也就是使用筛选索引的成本,是使用全表非聚集索引的成本的1/2。

图3.
图3.从IO信息收集结果看,针对表table_a进行了35次的逻辑读取,而表table_b 只进行了33次逻辑读取。也就说明使用筛选索引在IO逻辑读取次数少于全表非聚集索引在IO的逻辑读取次数。
下面我还从客户端统计信息来分析,使用筛选索引和全表非聚集索引的执行时间差别:

图4.
图4.可以看出,使用筛选索引,在客户端处理时间、总执行时间、服务器等待时间的平均值,都比全表非聚集索引的低。
|
减少了索引存储开销 |
可以使用下面的SQL语句来查看筛选索引(ix_table_b_col1_Filtered)和全表非聚集索引(ix_table_a_col1)的存储大小:
|
use TestDB go select object_name(b.object_id) as TableName, b.name as IndexName , sum(a.used_page_count) * 8 as IndexSizeKB from sys.dm_db_partition_stats as a join sys.indexes as b on a.object_id = b.object_id and a.index_id = b.index_id where b.object_id in ( object_id('table_a'), object_id('table_b') ) and b.name in('ix_table_a_col1','ix_table_b_col1_Filtered') group by b.object_id, b.name order by b.name |
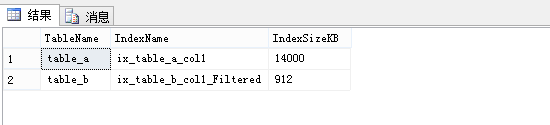
图5.
图5,可以看出筛选索引使用的存储空间明显小于全表非聚集索引。
|
减少了索引维护开销 |
仅在数据操作语言 (DML) 语句对索引中的数据产生影响时,才对索引进行维护。与全表非聚集索引相比,筛选索引减少了索引维护开销,因为它更小并且仅在对索引中的数据产生影响时才进行维护。
举个例子,先查表table_a和表table_b中,ID=10的数据:
|
use TestDB go select * from dbo.table_a where id=10 select * from dbo.table_b where id=10 |

图6.
现在要上面的col1= -1068265529 改成col1=-123456 ,看更新过程对两表索引(ix_table_a_col1 & ix_table_b_col1_Filtered)产生的影响情况 :
|
use TestDB go checkpoint go update table_a set col1=-123456 -- -1068265529 where id=10 update table_b set col1=-123456 -- -1068265529 where id=10 go select Operation , Context , AllocUnitName , [Transaction Name] , Description from fn_dblog(null, null) as a go |
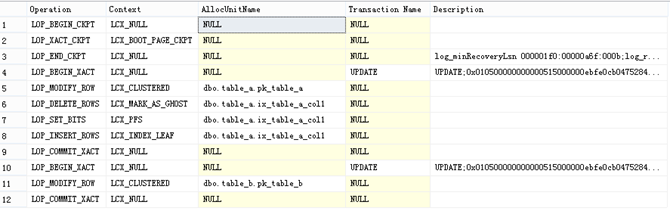
图7.
图7. 可以看到,前面的更新语句,针对于表table_a,有维护到索引ix_table_a_col1,而在表table_b,没找到维护ix_table_b_col1_Filtered的记录。
从这里可以判验证筛选索引减少了索引维护开销。
|
小结 |
上面的例子,说明了使用筛选索引的一些优点。在实际生产环境中,需要检查和分析经常用到的存储过程或程序代码中的SQL语句,是否有必要创建筛选索引来提升性能。虽然筛选索引,在某些情况下会提升查询性能,节省存储空间,但必须要小心使用,不能轻易删除现有的全表索引,使用筛选索引。
|
参考资料 |
SQL University: Advanced Indexing – Filtered Indexes:
http://sqlinthewild.co.za/index.php/2011/11/09/sql-university-advanced-indexing-filtered-indexes-2/
The Joys of Filtered Indexes:
http://blogs.msdn.com/b/timchapman/archive/2012/08/27/the-joys-of-filtered-indexes.aspx
Filtered Indexes: What You Need To Know :
http://sqlfool.com/2009/04/filtered-indexes-what-you-need-to-know/
创建筛选索引:
http://msdn.microsoft.com/zh-cn/library/cc280372(v=sql.100).aspx
CREATE INDEX:
http://msdn.microsoft.com/zh-cn/library/ms188783.aspx
非聚集索引设计指南:
http://msdn.microsoft.com/zh-cn/library/ms179325(v=sql.100).aspx