一、背景
容器是Java编程中使用频率很高的组件,但Java默认提供的基本容器(ArrayList,HashMap等)均不是线程安全的。当容器和多线程并发编程相遇时,程序员又该何去何从呢?
通常有两种选择:
1、使用synchronized关键字,将对容器的操作有序错开,确保同一时刻对同一个容器只存在一个操作。Vector,HashTable等封装后的容器本质也是这种解决思路,只不过synchronized关键字不需要我们来书写而已。
2、使用java.util.concurrent包下提供的并发容器。比如常见的ConcurrentHashMap、CopyOnWriteArrayList等。
第一种选择的优点是上手快,简单直接,易于调试,如果不考虑性能的话,几乎没有任何使用场景的限制,可以保证数据操作的强一致性;那么它的缺点也是很明显的,由于每次对容器的操作都锁住了整个容器,如果对容器进行高并发的操作,将导致操作性能急剧下降。
第二种选择的优点是concurrent包下的并发容器通常都做了性能上的高度优化,能保障高并发场景下的操作性能;但缺点是这些容器的背后实现原理相对复杂,而且对使用场景有一定限制,一般只能保证数据操作的弱一致性。
本文将重点介绍并发容器背后的典型设计思路与实现原理,读者了解了这些实现思路后,也可以更好的理解并发容器的使用场景的限制。
二、ConcurrentHashMap的设计理念
关于ConcurrentHashMap的实现原理,在JDK1.8与JDK1.8之前有不同的实现,关于它们具体的实现细节网上已经有很多优秀的文章进行介绍,比如:
1、《JDK1.7 ConcurrentHashMap原理分析》
2、《JDK1.8 ConcurrentHashMap原理分析》
3、 《ConcurrentHashMap在JDK1.7与JDK1.8中的对比》
此处便不在赘述了。
本文重点用简洁易懂的语言带领读者快速掌握ConcurrentHashMap在JDK1.8中高并发实现的原理。
2.1 普通HashMap实现原理回顾
首先我们简单回顾一下普通HashMap的实现原理。
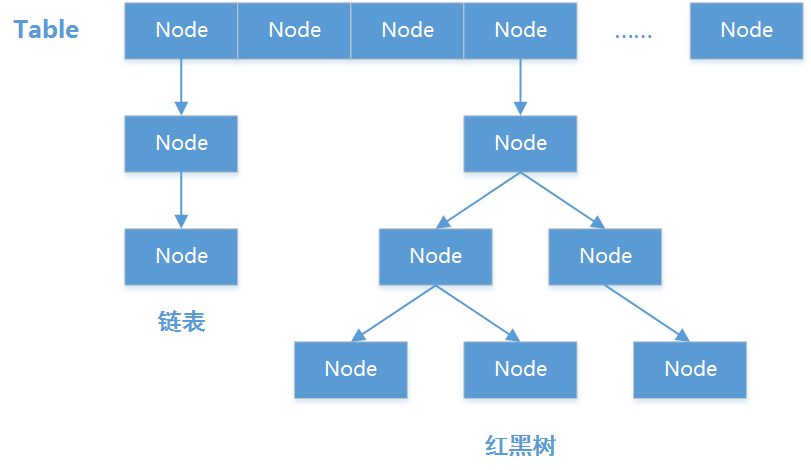
如上图所示,我们将Map中储存的每一个Entry抽象为一个Node。Node根据其Key值Hash取余后,映射到Table(一个Node数组)的某一个槽位上进行储存。如果出现Hash冲突(即两个Node的Key值Hash取余结果相同),则以链表的形式在出现冲突的Table槽位上继续追加Node。如果某一个槽位以链表的形式储存了过多的Node(8个以上),则将链表转换为红黑树储存,避免查询Node时对长链表的遍历,以降低查询Node的时间复杂度。当Map中容纳的Node总数大于Table长度乘以加载因子factor(默认0.75)时,Map会将Table成倍扩容,以减少Hash冲突的概率。
2.2 ConcurrentHashMap并发优化思路一:尽量减少锁的范围(锁分段)
传统的HashTable之所以并发性能很差,原因在于锁的范围过大,更新任何一个数据,都要将全Map锁住。
其实中HashMap的实现原理不难看出,HashMap本身天然就呈现出边界清晰的分段储存特性,即每一个Table中的一个槽位,即可认为是一个储存段。那么,如果我们将锁的精度精确到每一个储存段,就可以实现更新每一个数据,只会对与该数据相关的局部数据段加锁。而每个储存段的头结点,即可作为加锁对象。
JDK1.8中的核心源码如下:
Node<K,V> f;
f = tabAt(tab, i = (n - 1) & hash); //取出Tab指定槽中的头结点
synchronized (f) { //对这个头结点加锁
//... ...
}
如果某个槽位中尚不存在任何头结点(即头结点为null),此时我们不能对null进行加锁,又如何规避该槽位首次插入Node时可能遭遇的并发冲突呢?
可以使用CAS(Compare And Swap(Set))进行Node的首次插入。CAS的核心原理是更新某个数据前,检查该数据的值是否还是之前获取得到的旧值,如果是则说明该值还没有被其他线程修改,可以直接修改为新值,否则则说明该值已经被其他线程修改了,则设置失败。检查旧值是否被修改与设置新值这两步操作由CPU提供的单指令直接完成,保证原子性。
使用CAS技术加上CAS失败后的不断重试,即可实现无锁化更新数据。毕竟CAS失败的概率很低,不断重试也不会占用过多CPU。(乐观锁与自旋锁的理念)
JDK1.8中的核心源码如下:

for (Node<K, V>[] tab = table; ; ) {
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null)))
break; //CAS失败则跳出循环,开始下一次循环,重新读取头结点
}
}
2.3 ConcurrentHaspMap并发优化思路二:只对更新加锁,读不加锁 (弱一致性)
ConcurrentHashMap的读操作都是不加锁的。可以保证的是,读取某一个指定key的值时可以读取到最近一次更新完成的结果。更标准的说法是,上一次对keyA的更新结果happens-before后续对keyA的读取操作。
注:happens-before是jvm用来定义两个action之间(acitonA和actionB)的偏序关系,从而明确在CPU允许重排序的情况下,actionA发生的结果是一定要对后续发生的actionB可见的。
由于读操作不加锁,读操作可能会与其他线程的写操作重叠,ConcurrentHashMap可能会读取到其他线程写操作的中间状态。比如putAll在执行过程中有并发的get操作,那么get操作可能只会读取到插入的部分数据,同时并发的size操作的返回结果也是不准确的,只可用于估算类业务,不可用于精准的控制流程判断。再比如使用迭代器遍历Map时,另外一个线程正在删除Map,那么在读取过程中碰巧还没有被删除的数据会被读取到,而已经被删除的数据不会被读取到(不会抛出ConcurrentModificationException)。
三、CopyOnWriteArrayList的设计理念
3.1 CopyOnWriteArrayList并发优化思路:写时复制与弱一致性
所谓写时复制,即任何要改变CopyOnWriteArrayList的操作(add、set等),其内部实现都是深拷贝一份CopyOnWriteArrayList的底层数组,然后在深拷贝的副本上进行数据的修改。修改完成后,再用新的副本与替换原来的CopyOnWriteArrayList底层数组。
JDK1.8中的核心代码如下:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //深拷贝底层数组
newElements[len] = e; //在副本上进行修改
setArray(newElements); //修改完成后用副本替换底层数组
return true;
} finally {
lock.unlock();
}
}
写时复制的好处是,任何的读操作都不用加锁,而且保证读取到的是读那一刻List完整的快照数据。比如当CopyOnWriteArrayList的迭代器创建后,无论List本身如何变化,迭代器能感知到的都是它在被创建那一刻时List的状态,任何其他线程对List的改变,对本迭代器都不可见。不会出现ConcurrentHashMap的迭代器可能读取到其他线程修改过程中容器的中间状态的情况。由于CopyOnWriteArrayList读操作无法感知最新正在变化的数据,所以CopyOnWriteArrayList也是弱一致性的。
CopyOnWriteArrayList可以保证的是,读操作可以读取到最近一次更新完成的结果。
写时复制技术因为每次修改都需要完整拷贝一次底层数组,所以有额外的性能开销,但是特别适用于读多写少的数据访问场景。
四、总结
1、ConcurrentHashMap和CopyOnWriteArrayList都是无锁化的读取,所以读操作发生时无法确保目前所有其他线程的写操作已经完成,不可用于要求数据强一致性的场景。
2、ConcurrentHashMap和CopyOnWriteArrayList都可以保证读取时可以感知到已经完成的写操作。
3、ConcurrentHashMap读操作可能会感知到同一时刻其他线程对容器写操作的中间状态。CopyOnWriteArrayList永远只会读取到容器在读取时刻的快照状态。
4、ConcurrentHashMap使用锁分段技术,缩小锁的范围,提高写的并发量。CopyOnWriteArrayList使用写时复制技术,保证并发写入数据时,不会对已经开启的读操作造成干扰。
5、ConcurrentHashMap适用于高并发下对数据访问没有强一致性需求的场景。CopyOnWriteArrayList适用于高并发下能够容忍只读取到历史快照数据,且读多写少的场景。