information_schema 是MySql 信息数据库。
其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。在INFORMATION_SCHEMA中,有数个只读表。它们实际上是视图,而不是基本表,因此,你将无法看到与之相关的任何文件。
有些时候用于表述该信息的其他术语包括“数据词典”和“系统目录”。
关于information_schema 的讲解网上很多资料 也很全面 这里我们介绍下最常用的相关信息查询:
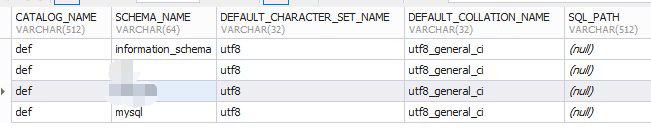
1.SCHEMATA
SELECT *FROM information_schema.SCHEMATA s; -- 数据库信息,主要了解mysql中有哪些数据库。
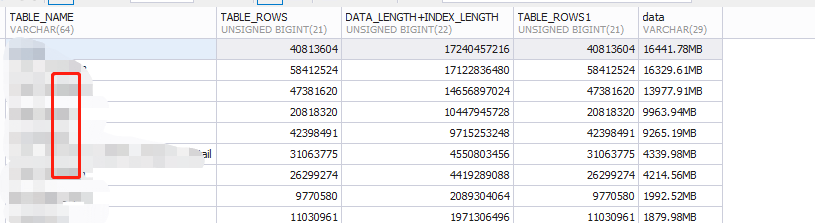
2.TABLES
SELECT *FROM information_schema.TABLES t WHERE t.TABLE_SCHEMA = '数据库名'; --数据库中表信息

这个表能干嘛呢?简洁:表明,表中行数,表存数据大小。
SELECT TABLE_NAME ,TABLE_ROWS ,DATA_LENGTH+INDEX_LENGTH ,concat(round((DATA_LENGTH+INDEX_LENGTH)/1024/1024,2), 'MB') as data FROM information_schema.tables WHERE TABLE_SCHEMA='库名' ORDER BY DATA_LENGTH+INDEX_LENGTH desc;
3.STATISTICS 提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表
SELECT s.INDEX_NAME,s.COLUMN_NAME,s.INDEX_TYPE,s.CARDINALITY FROM information_schema.STATISTICS s WHERE s.TABLE_NAME = '表名' AND s.TABLE_SCHEMA = '库名';
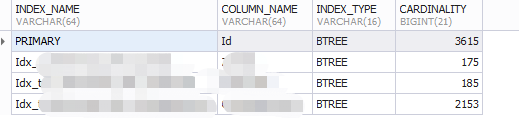
关键在于这列:CARDINALITY 这个干嘛用的呢?
表示所以中不重复记录的预估值,需要注意的是Cardinality是一个预估值,而不是一个准确值基本上用户也不可能得到一个准确的值,在实际应用中,Cardinality/n_row_in_table应尽可能的接近1,如果非常小,那用户需要考虑是否还有必要创建这个索引。故在访问高选择性属性的字段并从表中取出很少一部分数据时,对于字段添加B+树索引是非常有必要的。
建立索引的前提是高选择性。这对数据库来说才具有实际意义,那么数据库是怎样统计Cardinality的信息呢?因为MySQL数据库中有各种不同的存储引擎,而每种存储引擎对于B+树索引的实现又各不相同。所以对Cardinality统计时放在存储引擎层进行的
在生成环境中,索引的更新操作可能非常频繁。如果每次索引在发生操作时就对其进行Cardinality统计,那么将会对数据库带来很大的负担。另外需要考虑的是,如果一张表的数据非常大,如一张表有50G的数据,那么统计一次Cardinality信息所需要的时间可能非常长。这样的环境下,是不能接受的。因此,数据库对于Cardinality信息的统计都是通过采样的方法完成
索引的建立对数据库的影响非常之大,不信你可以跑个千万级的数据表试试,一个索引,2,3,4 相差的不是一点点 简直是指数倍的增长,合理的使用索引可以提高性能,滥用就是降低性能的表现。