带上R语言,学习支持向量机
1 R语言
长话短说,R语言是一款集统计分析和作图于一体的自由、免费、可编程软件(R3.6.1下载地址:https://mirrors.tuna.tsinghua.edu.cn/CRAN/ )。Rstudio是R语言的IDE,在编程过程中有自动扩写、使用界面help、创建R-markdown、project、以及各种快捷方式的使用,所以大多都会用Rstudio进行工作。【tip:Rstuidio需要在安装R语言后才能正常工作,下载地址:https://rstudio.com/products/rstudio/download/#download 】
在R语言里,你想要实现t检验,方差分析,模型建立等,都要使用相应函数。那么,函数在哪里?在各个不同的安装包里:你需要使用的函数在哪个包,你就下载使用哪个包。在根据函数里的参数,设置相应条件即可。
那么,怎么知道需要使用安装包:
1)R语言是有base包的,这个包你不需要下载,里面就有很多基础函数供你选择。当你需要实现某个功能时,百度一下,你就知道需要应该使用哪个函数;
2)如果你输入的相应函数,R语言提示错误,那就说明,你需要安装相应的包。
R语言需要知道的安装包基础:
1)安装包:install.packages(“PackageName”)【有引号】
2)应用包:library(PackageName)【没有引号】
3)可以使用包里的自带函数了。
2 支持向量机
2.1 简要说明
l SVM是一种有监督二分类机器学习模型,包括线性可分SVM和非线性可分SVM;
l 线性可分时,可用硬间隔和软间隔最大化学习SVM。线性不可分时,通过核技巧和软间隔最大化学习SVM;
l 当SVM训练完成后,大部分样本都不需要保留,最终模型只与支持向量有关;
https://zhuanlan.zhihu.com/p/77750026
2.2 解释:什么是支持向量
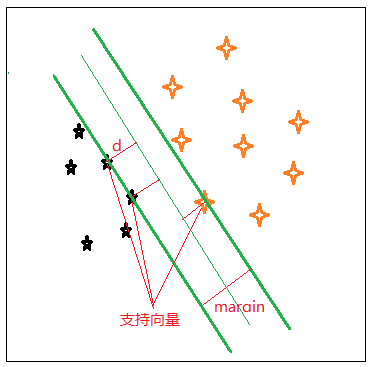
支持向量机的原理,是想要在分类数据中,找到一个平面,把两类数据分开。这样的平面可能有很多,但要找到一面最优的:两类数据中,距离分离平面最近的样本点的距离最大,就是最优的分离超平面(使margin最大),样本中距离超平面最近的一些点,就叫支持向量,如图:
带上R语言,学习支持向量机
1 R语言
长话短说,R语言是一款集统计分析和作图于一体的自由、免费、可编程软件(R3.6.1下载地址:https://mirrors.tuna.tsinghua.edu.cn/CRAN/ )。Rstudio是R语言的IDE,在编程过程中有自动扩写、使用界面help、创建R-markdown、project、以及各种快捷方式的使用,所以大多都会用Rstudio进行工作。【tip:Rstuidio需要在安装R语言后才能正常工作,下载地址:https://rstudio.com/products/rstudio/download/#download 】
在R语言里,你想要实现t检验,方差分析,模型建立等,都要使用相应函数。那么,函数在哪里?在各个不同的安装包里:你需要使用的函数在哪个包,你就下载使用哪个包。在根据函数里的参数,设置相应条件即可。
那么,怎么知道需要使用安装包:
1)R语言是有base包的,这个包你不需要下载,里面就有很多基础函数供你选择。当你需要实现某个功能时,百度一下,你就知道需要应该使用哪个函数;
2)如果你输入的相应函数,R语言提示错误,那就说明,你需要安装相应的包。
R语言需要知道的安装包基础:
1)安装包:install.packages(“PackageName”)【有引号】
2)应用包:library(PackageName)【没有引号】
3)可以使用包里的自带函数了。
2 支持向量机
2.1 简要说明
l SVM是一种有监督二分类机器学习模型,包括线性可分SVM和非线性可分SVM;
l 线性可分时,可用硬间隔和软间隔最大化学习SVM。线性不可分时,通过核技巧和软间隔最大化学习SVM;
l 当SVM训练完成后,大部分样本都不需要保留,最终模型只与支持向量有关;
2.2 解释:什么是支持向量
支持向量机的原理,是想要在分类数据中,找到一个平面,把两类数据分开。这样的平面可能有很多,但要找到一面最优的:两类数据中,距离分离平面最近的样本点的距离最大,就是最优的分离超平面(使margin最大),样本中距离超平面最近的一些点,就叫支持向量,如图:
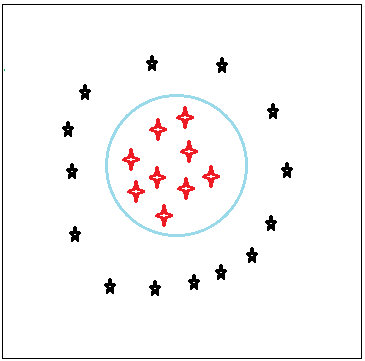
如果二维平面无法线性可分,则选用核函数将数据映射至三维层面,此时,也会找到一面最优的分离超平面,如图:
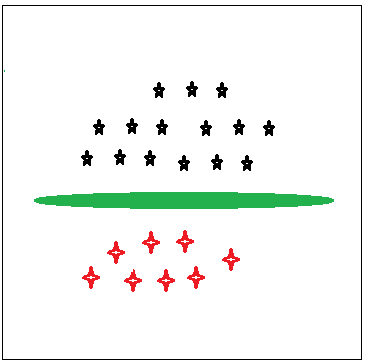
距离超平面最近的样本点,即为支持向量。
2.3 解释:最大间隔-硬间隔-软间隔
线性可分支持向量机对应着能将数据正确划分并且间隔最大的直线,间隔最大是为了让离超平面较近的异类点之间能有更大的间隔,即不必考虑所有样本点。以最小的成本保证最大的正确划分概率。那么,这个最大距离怎么算?
超平面划分可通过如下公式表示:
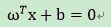
其中,为法向量,决定了超平面的方向,为位移量,决定了超平面与原点的距离。如果超平面能够将训练集数据()正确划分,应满足以下公式:

上面左边公式被称为最大间隔假设, 表示样本为正样本, 表示样本为负样本。满足以上右式的样本,即为支持向量。而不同类支持向量之间的间隔,等于两个异类支持向量的差在方向上的投影。所以,要想间隔最大化,就有了以下约束条件:
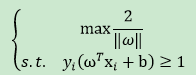
采用拉格朗日乘子法对其对偶问题求解(引入变量),对和进行偏导带入拉格朗日函数,就可以将原问题转为关于的问题。最终返回函数,即可得到进而求得。即得到最大间隔超平面。
硬间隔指:完全分类准确,其损失函数不存在;对数据质量和SVM要求很高;
软间隔:允许一定量的样本分类错误。在线性不可分的数据下,均使用软间隔最大化学习支持向量机模型。
2.4 核函数
核函数是应对数据线性不可分情形产生的,如果原始空间维数是有限的,即属性有限,那么一定存在一个高维特征空间使样本可分。支持向量机包括5种核函数:线性核、多项式核、高斯核、拉普拉斯核及sigmoid核。其函数表达如下表所示:

令表示将映射后的特征向量,于是在特征空间中,划分超平面所对应的的模型可表示为:
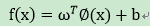
与最大间隔算法步骤相同,得到约束函数:
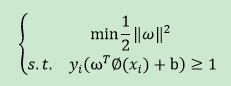
其对偶问题运算涉及到特征空间之后的内积,而特征空间的维数可能很高,甚至是无穷维,所以此路不是一条好路,有可能会撞墙。因此,核函数就登场了。特征空间之后的内积此时可转化为在原始样本空间中通过函数 κ()计算的函数值。有了核函数,最终对超平面求解为:
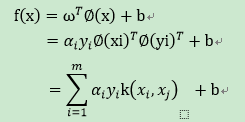
实际操作中,样本量不同,参数设置不同,所以大家的核函数也不同。
3 R语言实现支持向量机(以影像组数数据为例)
数据:使用工作中的影像数据为例,样本量85,特征数28(T2序列的影像特征经数据预处理及Lasso回归得到),预测变量五年生存率。
方法:支持向量机建立模型(svm)、Roc曲线表征模型(需要包:pRoc),采用70%样本进行训练,剩余30%样本进行预测。
结果:模型AUC值为0.88。
具体代码及结果如下:
3.1 需要包加载
library(e1071) # 支持向量机建模
library(pROC) # 用于计算ROC,前者用于plot画法,后者用于ggplot画法
library(magrittr) # 我主要使用它的管道函数,使代码看起来更优雅,思路更清晰
3.2 数据读入
setwd("I:\9-SWH论文合作") # 设置工作路径
files
<- list.files() #
列出工作路径所有文件
RadiomicsData
<- read.csv(files[8]) # 读取需要数据集
#
str(RadiomicsData) # 查看数据集结构、指标类别
RadiomicsData
<- RadiomicsData[,-1] # 我的第一列是行数,我不需要,因此删掉它
3.3 建模,作图
Rows
<- nrow(RadiomicsData) # 样本数【多少行即多少人】
TrainRows
<- sample(1:Rows,0.7*Rows
%>% round(0),replace
= F) # 选定训练集样本
Trainsvm
<- RadiomicsData[TrainRows,] #
训练集确定
Testsvm
<- RadiomicsData[-TrainRows,] #
测试集确定
Modelsvm1 <-
svm(as.factor(Variable)~.,data
= Trainsvm,scale
= T,kernel="sigmoid") # 模型建立
Presvm2 <-
predict(Modelsvm,Testsvm[,-ncol(Testsvm)])
# 以上训练的模型对测试集进行验证
解释:1:e1071包的函数svm用于支持向量机模型构建,可使用模型参数如下表所示:
|
参数 |
解释 |
|
formula |
你要做的模型表示【as.factor(Variable)~. 意思是Variable是相应变量,其余都是因变量】 |
|
data |
模型使用的数据框,这个数据框中包含了fomula里所有的变量 |
|
x |
可以是数据框类型,也可以是矩阵类型,也可以是向量类型(as.factor将数值型变量转换成因子型变量了) |
|
y |
响应变量,如果是因子型就会做分类模型,如果是数值型就会做回归模型 |
|
scale |
将使用的数据归一化,默认情况下,函数会将使用数据转变为均值为0,方差为1的标准数据集 |
|
type |
支持向量机可以用作分类机、回归机或新颖性检测。根据y是否是一个因子,type的默认设置分别是C-classification或epd -regression,但是可以根据需要设置成如下几种:C-classification,nu-classification,one-classification (for novelty detection),eps-regression;nu-regression |
|
kernel |
用于训练和预测的核函数。根据响应变量类型,可以选用的核函数为:linner,polynomial,radial basis,sigmoid |
|
degree |
如果kenel选择了polynomial,则需要设置此参数,默认值为3 |
|
gamma |
除了kernel为linear外的核函数,都需要设置此参数,默认为: 1/(data dimension) |
|
coef0 |
核函数为polynomial何sigmoid,需要设置此参数,默认为0 |
|
cost |
惩罚系数,默认值为1-它是拉格朗日公式中正则化项的“C”常数 |
|
nu |
type为nu-classification, nu-regression, 和 one-classification时,需设置此函数 |
|
class.weights |
不同类别的权重向量,当数据类别分布不平衡时使用,默认为1 |
|
cachesize |
缓存内存(默认为40 MB) |
|
tolerance |
模型容忍度,默认是0.001 |
|
epsilon |
灵敏度损失函数中的epsilon,默认值:0.1 |
|
shrinking |
默认为T,通常不管这个参数 |
|
cross |
交叉验证设置,数据量不大时忽略 |
|
fitted |
默认为T,通常不管这个参数 |
|
probability |
是否允许概率预测 |
|
... |
additional parameters for the low level fitting functionsvm.default |
|
subset |
指定在训练样本中使用的案例的索引向量。(注意:如果给定索引向量,这个参数必须准确命名。) |
|
na.action |
遇到数据集中有NA值的操作,默认是na.omit操作,即将有na的所有行直接删掉 |
2:predict函数是base包函数,第一个参数是建立的模型,第二个参数是输入的待预测数据集。因为模型是用全部因变量建立的,所以输入的数据集要将测试集的响应变量删去。Predict后的结果就是预测的响应变量值,将其与真实值作比较,就知道模型如何。
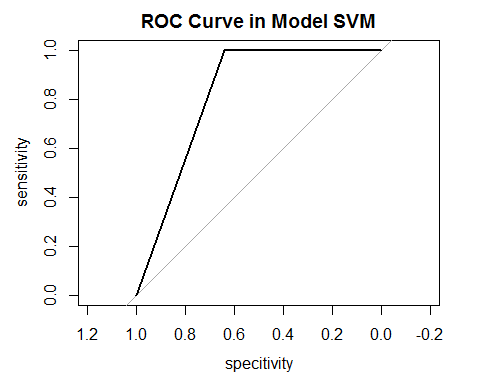
3.4 pRoc作图
PicPRoc
<- roc(Presvm,Testsvm[,ncol(Testsvm)])
#运用pRoc包的roc函数计算roc
PicPRoc
## Call:
## roc.default(response = Presvm, predictor =
Testsvm[, ncol(Testsvm)])
##
## Data: Testsvm[, ncol(Testsvm)] in 25 controls
(Presvm 0) < 1 cases (Presvm 1).
## Area under the curve: 0.82
plot(PicPRoc,xlim=c(1,0),ylim=c(0,1),main = "ROC Curve in Model SVM",xlab = "specitivity",ylab = "sensitivity") %>% print()