Introduction
In part A we should add multiprocessor support to JOS, implement round-robin scheduling, and add basic environment management system calls (calls that create and destroy environments, and allocate/map memory).
In the first part of this lab, we will first extend JOS to run on a multiprocessor system, and then implement some new JOS kernel system calls to allow user-level environments to create additional new environments. we will also implement cooperative round-robin scheduling, allowing the kernel to switch from one environment to another when the current environment voluntarily relinquishes the CPU (or exits). Later in part C we will implement preemptive scheduling, which allows the kernel to re-take control of the CPU from an environment after a certain time has passed even if the environment does not cooperate.
Multiprocessor Support
We are going to make JOS support "symmetric multiprocessing" (SMP), all CPUs are functionally identical in SMP, during the boot process they can be classified into two types:
- the bootstrap processor (BSP) is responsible for initializing the system and for booting the operating system;
- application processors (APs) are activated by the BSP only after the operating system is up and running
Which processor is the BSP is determined by the hardware and the BIOS. Up to this point, all existing JOS code that we write and implement has been running on the BSP
APIC (LAPIC) unit and CPU startup
In an SMP system, each CPU has an accompanying local APIC (LAPIC) unit.
function: The LAPIC units are responsible for delivering interrupts throughout the system. The LAPIC also provides its connected CPU with a unique identifier.
-
Reading the LAPIC identifier (APIC ID) to tell which CPU our code is currently running on (see cpunum()).
int cpunum(void) { if (lapic) return lapic[ID] >> 24; return 0; } -
Sending the STARTUP interprocessor interrupt (IPI) from the BSP to the APs to bring up other CPUs (see lapic_startap()).
// Start additional processor running entry code at addr. // See Appendix B of MultiProcessor Specification. void lapic_startap(uint8_t apicid, uint32_t addr) { int i; uint16_t *wrv; // "The BSP must initialize CMOS shutdown code to 0AH // and the warm reset vector (DWORD based at 40:67) to point at // the AP startup code prior to the [universal startup algorithm]." outb(IO_RTC, 0xF); // offset 0xF is shutdown code outb(IO_RTC+1, 0x0A); wrv = (uint16_t *)KADDR((0x40 << 4 | 0x67)); // Warm reset vector wrv[0] = 0; wrv[1] = addr >> 4; // "Universal startup algorithm." // Send INIT (level-triggered) interrupt to reset other CPU. lapicw(ICRHI, apicid << 24); lapicw(ICRLO, INIT | LEVEL | ASSERT); microdelay(200); lapicw(ICRLO, INIT | LEVEL); microdelay(100); // should be 10ms, but too slow in Bochs! // Send startup IPI (twice!) to enter code. // Regular hardware is supposed to only accept a STARTUP // when it is in the halted state due to an INIT. So the second // should be ignored, but it is part of the official Intel algorithm. // Bochs complains about the second one. Too bad for Bochs. for (i = 0; i < 2; i++) { lapicw(ICRHI, apicid << 24); lapicw(ICRLO, STARTUP | (addr >> 12)); microdelay(200); } } -
In part C, we program LAPIC's built-in timer to trigger clock interrupts to support preemptive multitasking (see apic_init())
void lapic_init(void) { if (!lapicaddr) return; // lapicaddr is the physical address of the LAPIC's 4KB MMIO // region. we get it by kern/pmap.c Map it in to virtual memory so we can access it. lapic = mmio_map_region(lapicaddr, 4096); // Enable local APIC; set spurious interrupt vector. lapicw(SVR, ENABLE | (IRQ_OFFSET + IRQ_SPURIOUS)); // The timer repeatedly counts down at bus frequency // from lapic[TICR] and then issues an interrupt. // If we cared more about precise timekeeping, // TICR would be calibrated using an external time source. lapicw(TDCR, X1); lapicw(TIMER, PERIODIC | (IRQ_OFFSET + IRQ_TIMER)); lapicw(TICR, 10000000); // Leave LINT0 of the BSP enabled so that it can get // interrupts from the 8259A chip. // // According to Intel MP Specification, the BIOS should initialize // BSP's local APIC in Virtual Wire Mode, in which 8259A's // INTR is virtually connected to BSP's LINTIN0. In this mode, // we do not need to program the IOAPIC. if (thiscpu != bootcpu) lapicw(LINT0, MASKED); // Disable NMI (LINT1) on all CPUs lapicw(LINT1, MASKED); // Disable performance counter overflow interrupts // on machines that provide that interrupt entry. if (((lapic[VER]>>16) & 0xFF) >= 4) lapicw(PCINT, MASKED); // Map error interrupt to IRQ_ERROR. lapicw(ERROR, IRQ_OFFSET + IRQ_ERROR); // Clear error status register (requires back-to-back writes). lapicw(ESR, 0); lapicw(ESR, 0); // Ack any outstanding interrupts. lapicw(EOI, 0); // Send an Init Level De-Assert to synchronize arbitration ID's. lapicw(ICRHI, 0); lapicw(ICRLO, BCAST | INIT | LEVEL); while(lapic[ICRLO] & DELIVS) ; // Enable interrupts on the APIC (but not on the processor). lapicw(TPR, 0); }
these three functions are important functions of LAPIC(APIC), but we don't use all now, we
A processor accesses its LAPIC using memory-mapped I/O (MMIO). In MMIO, a portion of physical memory is hardwired to the registers of some I/O devices, so the same load/store instructions typically used to access memory can be used to access device registers. You've already seen one IO hole at physical address 0xA0000 (we use this to write to the VGA display buffer). The LAPIC lives in a hole starting at physical address 0xFE000000 (32MB short of 4GB), so it's too high for us to access using our usual direct map at
KERNBASE. The JOS virtual memory map leaves a 4MB gap at MMIOBASE so we have a place to map devices like this. Since later labs introduce more MMIO regions, you'll write a simple function to allocate space from this region and map device memory to it.
we could use below picture to illustrate the process of weak up all APs, and use cpus.
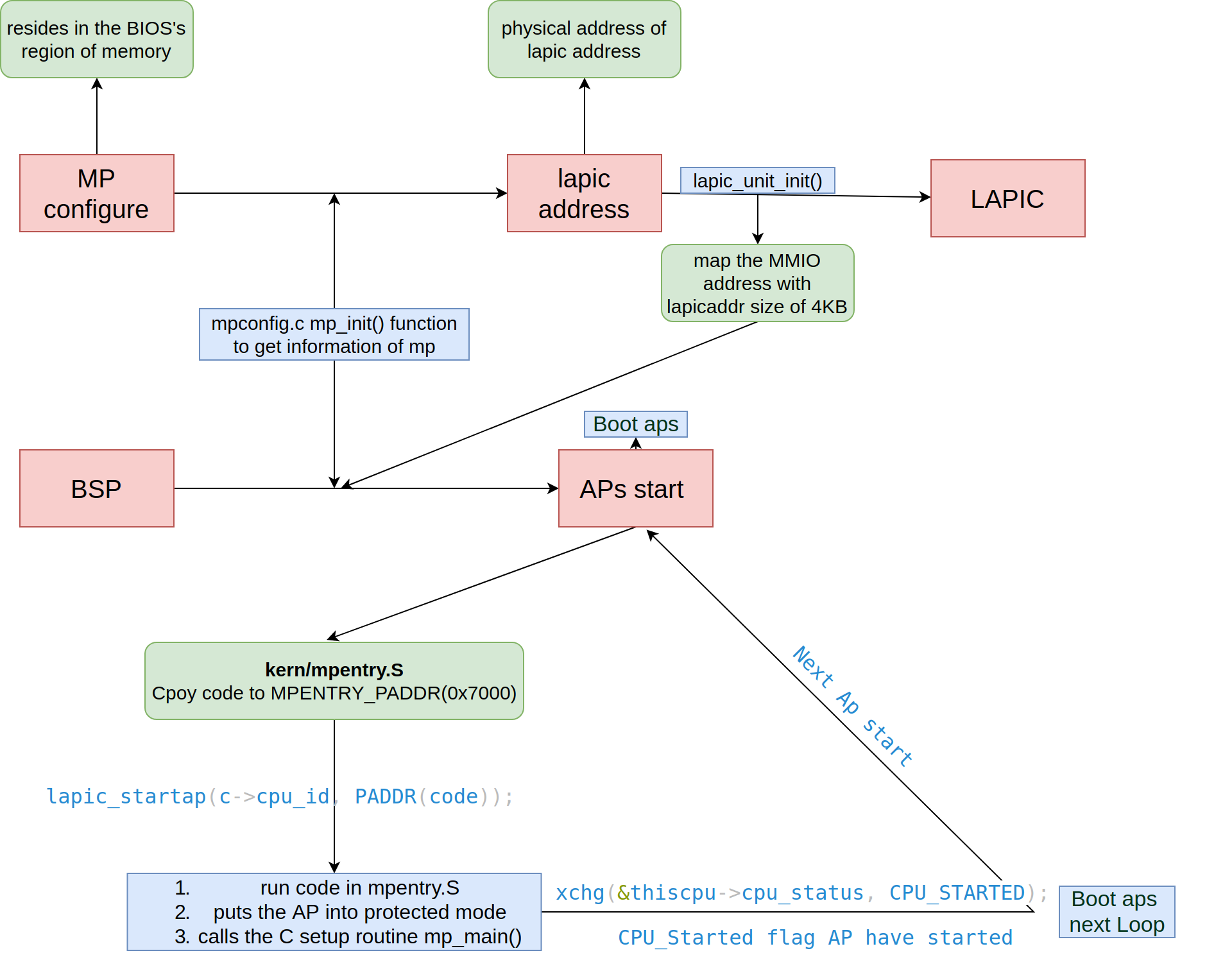
Question 1
Compare kern/mpentry.S side by side with boot/boot.S. Bearing in mind that kern/mpentry.S is compiled and linked to run above KERNBASE just like everything else in the kernel, what is the purpose of macro MPBOOTPHYS? Why is it necessary in kern/mpentry.S but not in boot/boot.S? In other words, what could go wrong if it were omitted in kern/mpentry.S? Hint: recall the differences between the link address and the load address that we have discussed in Lab 1.
we should know the difference of the virtual address between boot/boot.S and kern/mpentry.S, boot.S is Bootloader, and we have determined the location where the kernel code is loaded to the physical address, this location is 0x00100000, and the file is entry.S, but for mpentry.S load file to the determined physical address that we mapped by MPBOOTPHYS and the physical address is MPENTRY_PADDR, in JOS, MPENTRY_PADDR is 0x7000 (MPENTRY_PADDR), but any unused, page-aligned physical address below 640KB would work.
Per-CPU State and Initialization
Every CPU have information that descript its information and Passing information with the system. some important information that illustrate the status of CPU,
| Information and State | Related variables | Function |
|---|---|---|
| Per-CPU kernel stack | array percpu_kstacks[NCPU][KSTKSIZE] | reserves space for NCPU's worth of kernel stacks. |
| Per-CPU TSS and TSS descriptor | GDT entry gdt[(GD_TSS0 >> 3) + i] | specify where each CPU's kernel stack lives |
| Per-CPU current environment pointer | cpus[cpunum()].cpu_env (or thiscpu->cpu_env) | points to the environment currently executing on the current CPU |
| Per-CPU system registers | such as lcr3(), ltr(), lgdt(), lidt() | every cpu must be executed once on each CPU. Functions env_init_percpu() and trap_init_percpu() are defined for this purpose |
Exercise 3
we map the kernel stack from KSTACKTOP to below , and the size of each stack is KSTKSIZE bytes plus KSTKGAP bytes of unmapped guard pages, so , we map KSTKSIZE for every cpu, but the stack decrease KSTKSIZE + KSTKGAP bytes.
static void mem_init_mp(void)
{
// Map per-CPU stacks starting at KSTACKTOP, for up to 'NCPU' CPUs.
//
// For CPU i, use the physical memory that 'percpu_kstacks[i]' refers
// to as its kernel stack. CPU i's kernel stack grows down from virtual
// address kstacktop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP), and is
// divided into two pieces, just like the single stack you set up in
// mem_init:
// * [kstacktop_i - KSTKSIZE, kstacktop_i)
// -- backed by physical memory
// * [kstacktop_i - (KSTKSIZE + KSTKGAP), kstacktop_i - KSTKSIZE)
// -- not backed; so if the kernel overflows its stack,
// it will fault rather than overwrite another CPU's stack.
// Known as a "guard page".
// Permissions: kernel RW, user NONE
//
// LAB 4: Your code here:
int i;
for (i = 0; i < NCPU; i++) {
uint32_t kstacktop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP);
boot_map_region(kern_pgdir, kstacktop_i - KSTKSIZE, KSTKSIZE, PADDR(percpu_kstacks[i]), PTE_W);
}
}
Exercise 4
In this step,We should know that when the currently running CPU trap into the kernel, where should we start execute the code. that actually is descripted in TSS segment. and the TSS's address is saved in gdt.
// Initialize and load the per-CPU TSS and IDT,
void trap_init_percpu(void)
{
// LAB 4: Your code here:
// get the id of current running cpu
int id = thiscpu->cpu_id;
// Setup a TSS so that we get the right stack
// when we trap to the kernel. the stack is decreased to below
// struct Taskstate cpu_ts in thiscpu is Used by x86 to find stack for interrupt
thiscpu->cpu_ts.ts_esp0 = (uint32_t)percpu_kstacks[id] + KSTKSIZE;
thiscpu->cpu_ts.ts_ss0 = GD_KD;
thiscpu->cpu_ts.ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt.
gdt[(GD_TSS0 >> 3) + id] = SEG16(STS_T32A, (uint32_t) (&thiscpu->cpu_ts), sizeof(struct Taskstate) - 1, 0);
gdt[(GD_TSS0 >> 3) + id].sd_s = 0;
// GD_TSS0 is cpu0, and we find its bottom three bits are 0, maybe we would use for
// other information
ltr(GD_TSS0 + (id<<3));
// Load the IDT, 导入中断描述表
lidt(&idt_pd);
}
Locking
Because the kernel has the highest priority for accessing resources, such as IO ports, only one CPU can enter the kernel state at a time to prevent processes from mutating. The simplest way to achieve this is to use a big kernel lock. The big kernel lock is a single global lock that is held whenever an environment enters kernel mode, and is released when the environment returns to user mode. we could regard kernel as a kind of resource, we cloud access this resource without conflict. In the code, we give a example of get the lock,:
// kernel is a global variable
extern struct spinlock kernel_lock;
// get the lock is similiar to the Authority to be in kernel,
static inline void lock_kernel(void)
{
spin_lock(&kernel_lock);
}
// Acquire the lock. Loops (spins) until the lock is acquired.
// Holding a lock for a long time may cause, other CPUs to waste time spinning to acquire it.
void spin_lock(struct spinlock *lk)
{
#ifdef DEBUG_SPINLOCK
if (holding(lk))
panic("CPU %d cannot acquire %s: already holding", cpunum(), lk->name);
#endif
// The xchg is atomic.
// It also serializes, so that reads after acquire are not
// reordered before it.
while (xchg(&lk->locked, 1) != 0)
asm volatile ("pause");
// Record info about lock acquisition for debugging.
#ifdef DEBUG_SPINLOCK
lk->cpu = thiscpu;
// Record the current call stack in pcs[] by following the %ebp chain.
// because only a CPU get in kernel
get_caller_pcs(lk->pcs);
#endif
}
Exercise 5
it's not very hard to know where we should lock the kernel resource before current CPU get in kernel state.
- i386_init()
- mp_main()
- trap()
- env_run(), this time, we transform kernel to user environment,
Question 2
It seems that using the big kernel lock guarantees that only one CPU can run the kernel code at a time. Why do we still need separate kernel stacks for each CPU? Describe a scenario in which using a shared kernel stack will go wrong, even with the protection of the big kernel lock
we give a example when an exception or interrupt is triggered, In Lab3, we know that, we save the arguments to kernel stack when we in trapentry.S before we get into trap, so, If we only have one big kernel lock, maybe, when CPU0 deal with a trap, CPU1 have a trap and save the argument in kernel stack.
Round-Robin Scheduling
Since we have multiple CPUs, we can run multiple processes at the same time, When the CPU enters the running state from the idle state, it needs to wake up a environment to run, So, when the CPU start work?
Obviously, when the Operating System started, the BSP starts to work first, and then wakes up the APS. Each awakened CPU enters the kernel state, calls the function sched_yield(), and assigns an runnable environment to the CPU for execution. This step happen in function mp_main(),
Exercise 6
we must know, the first sched_yield() called by BSP, and the others called by mp_main().
// Choose a user environment to run and run it.
void sched_yield(void)
{
struct Env *idle;
// Implement simple round-robin scheduling.
//
// Search through 'envs' for an ENV_RUNNABLE environment in
// circular fashion starting just after the env this CPU was
// last running. Switch to the first such environment found.
//
// If no envs are runnable, but the environment previously
// running on this CPU is still ENV_RUNNING, it's okay to
// choose that environment.
//
// Never choose an environment that's currently running on
// another CPU (env_status == ENV_RUNNING). If there are
// no runnable environments, simply drop through to the code
// below to halt the cpu.
// LAB 4: Your code here.
idle = curenv;
// get the running env's ID
int idle_envid = (idle == NULL) ? -1 : ENVX(idle->env_id);
int i = idle_envid + 1;
// search envs after idle
while(i < NENV) {
if (envs[i].env_status == ENV_RUNNABLE) {
env_run(&envs[i]);
}
i++;
}
// find from 1st env if not found
for (i = 0; i < idle_envid; i++) {;
if (envs[i].env_status == ENV_RUNNABLE) {
env_run(&envs[i]);
}
}
// if still not found, try idle
if(idle != NULL && idle->env_status == ENV_RUNNING) {
env_run(idle);
}
// sched_halt never returns,
// Halt this CPU when there is nothing to do. Wait until the
// timer interrupt wakes it up. This function never returns.
sched_halt();
}
Question 3
lcr3(PADDR(e->env_pgdir));
before and after this line code, the pgdir is different with different env, but, for all env, the map above UTOP is the same, so, The virtual address of e is always the same whatever the address space it is.
Question 4
Every process switching requires a system call, that is sys_yield() syscall, the syscall will go into kernel, and sys_yield() will save registers in the env_tf, and they are restored by env_pop_tf() when env_run() is executed.
System Calls for Environment Creation
In the kernel we implemented before, the use of multiple envs is implemented by the kernel , only we in the kernel, we can set up a new environment, we will now implement the necessary JOS system calls to allow user environments to create and start other new user environments, for example, When we click on the web page link(URL) in the word document, the browser process will open a new env.
In computing, particularly in the context of the Unix operating system and its workalikes, fork is an operation whereby a process creates a copy of itself. For a environment, it copy main content is env configure, which include: env_tf(save the registers information), page_directory, and page_table. So, The fork system call is divided into several steps to complete.
Exercise 7
-
sys_exofork:
// Allocate a new environment. // Returns envid of new environment, or < 0 on error. Errors are: // -E_NO_FREE_ENV if no free environment is available. // -E_NO_MEM on memory exhaustion. static envid_t sys_exofork(void) { // Create the new environment with env_alloc(), from kern/env.c. // It should be left as env_alloc created it, except that // status is set to ENV_NOT_RUNNABLE, and the register set is copied // from the current environment -- but tweaked so sys_exofork // will appear to return 0. // LAB 4: Your code here. struct Env *e; int r; // Create the new environment with env_alloc(), from kern/env.c. if ((r = env_alloc(&e, curenv->env_id)) != 0) { return r; } e->env_status = ENV_NOT_RUNNABLE; e->env_tf = curenv->env_tf; e->env_tf.tf_regs.reg_eax = 0; // return 0 to child return e->env_id; // panic("sys_exofork not implemented"); } -
sys_env_set_status:
// Set envid's env_status to status, which must be ENV_RUNNABLE // or ENV_NOT_RUNNABLE. // // Returns 0 on success, < 0 on error. Errors are: // -E_BAD_ENV if environment envid doesn't currently exist, // or the caller doesn't have permission to change envid. // -E_INVAL if status is not a valid status for an environment. static int sys_env_set_status(envid_t envid, int status) { // You should set envid2env's third argument to 1, which will // check whether the current environment has permission to set // envid's status. struct Env *e; int r; if (status != ENV_RUNNABLE && status != ENV_NOT_RUNNABLE) { return -E_INVAL; } // Use the 'envid2env' function from kern/env.c to translate an envid to a struct Env. // this mean envid change e to the right position in envs[] if ((r = envid2env(envid, &e, 1)) != 0) { return r; } e->env_status = status; return 0; // LAB 4: Your code here. // panic("sys_env_set_status not implemented"); } -
sys_page_alloc:
static int sys_page_alloc(envid_t envid, void *va, int perm) { // Hint: This function is a wrapper around page_alloc() and // page_insert() from kern/pmap.c. // Most of the new code you write should be to check the // parameters for correctness. // If page_insert() fails, remember to free the page you // allocated! struct Env *e; struct PageInfo *pp; int r; // if va in kernel area or va is not PAGSIZE align if ((uint32_t)va >= UTOP || PGOFF(va) != 0) { return -E_INVAL; } // perm -- PTE_U | PTE_P must be set, PTE_AVAIL | PTE_W may or may not be set, if ((perm & (PTE_U | PTE_P)) != (PTE_U | PTE_P)) { return -E_INVAL; } // but no other bits may be set. if ((perm & ~(PTE_SYSCALL)) != 0) { return -E_INVAL; } // we get the env_configure with the envid, in the envs array if ((r = envid2env(envid, &e, 1)) != 0) { return r; } if((pp = page_alloc(perm)) == NULL) { return -E_NO_MEM; } if((r = page_insert(e->env_pgdir, pp, va, perm)) != 0) { page_free(pp); return -E_NO_MEM; } return 0; // LAB 4: Your code here. // panic("sys_page_alloc not implemented"); }
4. sys_page_map:
> Copy a page mapping (not the contents of a page!) from one environment's address space to another, leaving a memory sharing arrangement in place so that the new and the old mappings both refer to the same page of physical memory.
```C
static int sys_page_map(envid_t srcenvid, void *srcva, envid_t dstenvid, void *dstva, int perm)
{
// Hint: This function is a wrapper around page_lookup() and
// page_insert() from kern/pmap.c.
// Again, most of the new code you write should be to check the
// parameters for correctness.
// Use the third argument to page_lookup() to
// check the current permissions on the page.
// LAB 4: Your code here.
struct Env *srcenv, *dstenv;
struct PageInfo *pp;
pte_t *pte;
int r;
// these error conditions is similliar with above
if ((uint32_t)srcva >= UTOP || PGOFF(srcva) != 0) {
return -E_INVAL;
}
if ((uint32_t)dstva >= UTOP || PGOFF(dstva) != 0) {
return -E_INVAL;
}
if ((perm & (PTE_U | PTE_P)) != (PTE_U | PTE_P)) {
return -E_INVAL;
}
if ((perm & ~(PTE_SYSCALL)) != 0) {
return -E_INVAL;
}
if ((r = envid2env(srcenvid, &srcenv, 1)) != 0) {
return r;
}
if ((r = envid2env(dstenvid, &dstenv, 1)) != 0) {
return r;
}
// look up the physical page that srcenv's srcva point, if this Page is NULL, return error
if ((pp = page_lookup(srcenv->env_pgdir, srcva, &pte)) == NULL) {
return -E_INVAL;
}
// pte is the pagetable entry of virtual address of srcva in srcenv->env_pgdir
if ((*pte & PTE_W) == 0 && (perm & PTE_W) == PTE_W) {
return -E_INVAL;
}
if ((r = page_insert(dstenv->env_pgdir, pp, dstva, perm)) != 0) {
return r;
}
return 0;
// panic("sys_page_map not implemented");
}
-
sys_page_unmap:
static int sys_page_unmap(envid_t envid, void *va) { // Hint: This function is a wrapper around page_remove(). // LAB 4: Your code here. struct Env *e; int r; if ((uint32_t)va >= UTOP || PGOFF(va) != 0) { return -E_INVAL; } if ((r = envid2env(envid, &e, 1)) != 0) { return r; } page_remove(e->env_pgdir, va); return 0; // panic("sys_page_unmap not implemented"); }
for the steps of fork in the user program, we can get the example in ./user/dumbfork.c: but this is not really fork that we should implement,
envid_t dumbfork(void)
{
envid_t envid;
uint8_t *addr;
int r;
// Initialize end[] in this way, then end is at the end of the kernel data segment,
// which is the free segment after the bss segment
extern unsigned char end[];
// Allocate a new child environment.
// The kernel will initialize it with a copy of our register state,
// so that the child will appear to have called sys_exofork() too -
// except that in the child, this "fake" call to sys_exofork()
// will return 0 instead of the envid of the child.
envid = sys_exofork();
if (envid < 0)
panic("sys_exofork: %e", envid);
if (envid == 0) {
// We're the child.
// The copied value of the global variable 'thisenv'
// is no longer valid (it refers to the parent!).
// Fix it and return 0.
thisenv = &envs[ENVX(sys_getenvid())];
return 0;
}
// We're the parent.
// Eagerly copy our entire address space into the child.
// This is NOT what you should do in your fork implementation.
// UTEXT is Where user programs generally begin, end is the end address
for (addr = (uint8_t*) UTEXT; addr < end; addr += PGSIZE)
duppage(envid, addr);
// Also copy the stack we are currently running on.
duppage(envid, ROUNDDOWN(&addr, PGSIZE));
// Start the child environment running
if ((r = sys_env_set_status(envid, ENV_RUNNABLE)) < 0)
panic("sys_env_set_status: %e", r);
return envid;
}