WeTest 导读
UPA作为腾讯WeTest与Unity官方联合打造的客户端性能分析工具,为开发者提供了极大的便利和效能提升。产出的分析报告内容详尽,但您是否真的读懂了报告?是否了解每项数据的含义?此次就让我们的大咖来为您详细解读UPA的性能报告,让您瞬间秒懂。
测试概况
一般做完数据收集后,查看upa深度性能报告,最先看到的就是测试概况页面。

上面的数据大致可以分成这几个方面来看:
1)平均帧率既和CPU耗时有关(点击下方的通过/未通过按钮可跳转到CPU模块),也和GPU耗时有关。
2)ReservedMono内存可以理解为游戏中脚本分配的内存,进一步定位可以借助upa的mono内存测试(详见附录)。
3)纹理、网格、动画、音频等可以理解为资源内存,进一步定位可以借助upa的资源内存测试(详见附录)。
4)drawcall和Tris和GPU耗时有关,进一步定位可以借助针对GPU分析的工具(详见附录)。
5)pss内存一般用于定位多局战斗、场景跳转、打开关闭UI中是否有内存泄漏,可以借助wetest助手中的通用性能测试获取。
通过概况页面可以大致看出游戏存在的性能问题,upa也给出了问题和优化建议:

CPU
cpu模块提供了CPU耗时相关的详细数据。
cpu性能占用这一页签的概述给出了各模块的整体耗时:

frameTime:当前帧总耗时;
RenderingTime:当前帧渲染耗时;drawcall越高,这部分开销越大。可以通过减少所渲染物体的材质种类(内存页签下的材质资源),降低drawcall。
ScriptTime:当前帧函数耗时。
PhysicsTime:当前帧物理耗时。
从上图中可以看出函数和渲染耗时比较多,可以看下概况页面下的耗时排名top10的模块:
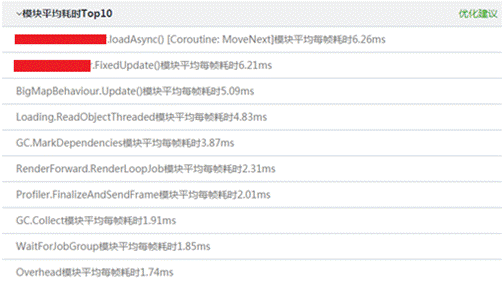
针对耗时较高的帧,可以查看详细的模块耗时情况:
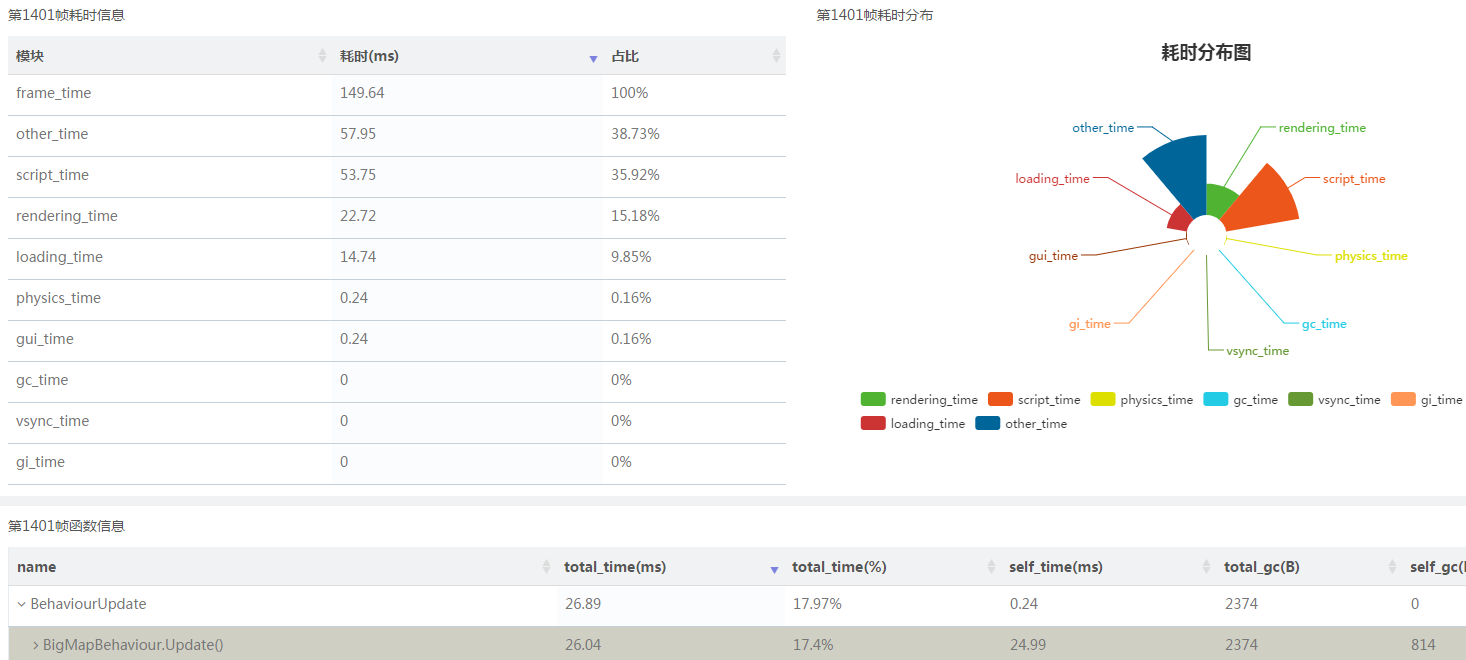
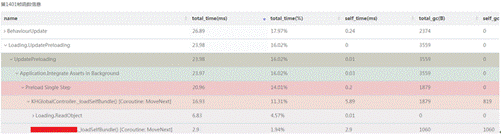
比如上图选取的第1401帧耗时较大(场景加载),可以展开模块耗时,查看具体模块具体函数的耗时、时间占比以及每一帧的GC Alloc。
Loading.UpdatePreloading,主要负责卸载当前场景的资源,并且加载下一场景中的相关资源等。下一场景中,自身所拥有的GameObject和资源越多,其加载开销越大。
内存
内存模块反映了游戏各方面的内存占用情况。

上图中的total_reserved是unity引擎在内存方面的总体分配量,total_used是unity引擎在内存方面的总体使用量,unused_total是空闲的内存。这里的引擎分配内存和空闲内存都比较多。
total_reserved内存=unity_reserved内存+GFX内存+FMOD内存+Mono内存+Profiler内存
下面分别展开说明:
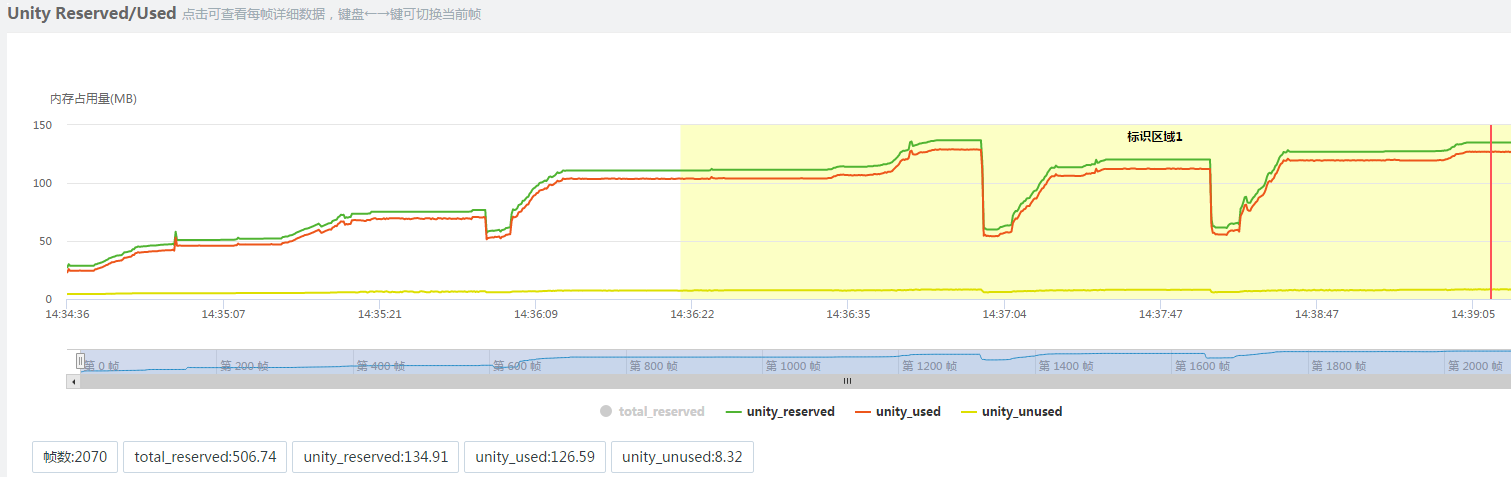
unity reserved:这部分主要包括资源内存。可以针对纹理、网格、动画、材质、音频资源优化。比如FBX模型导入时,"Read/Write Enable"是默认开启的,mesh数据会保留一份在unity reserved中,关闭可以减少该模型在unity reserved中占用内存一半的大小。

mono reserved:分配的mono内存(绿线部分),只升不降,需要严格控制。mono内存表示游戏中脚本分配的内存,虽然mono本身提供了垃圾回收机制,但还是可能出现内存泄漏。如果需要进一步定位,需要借助upa的mono内存测试(详见附录)。
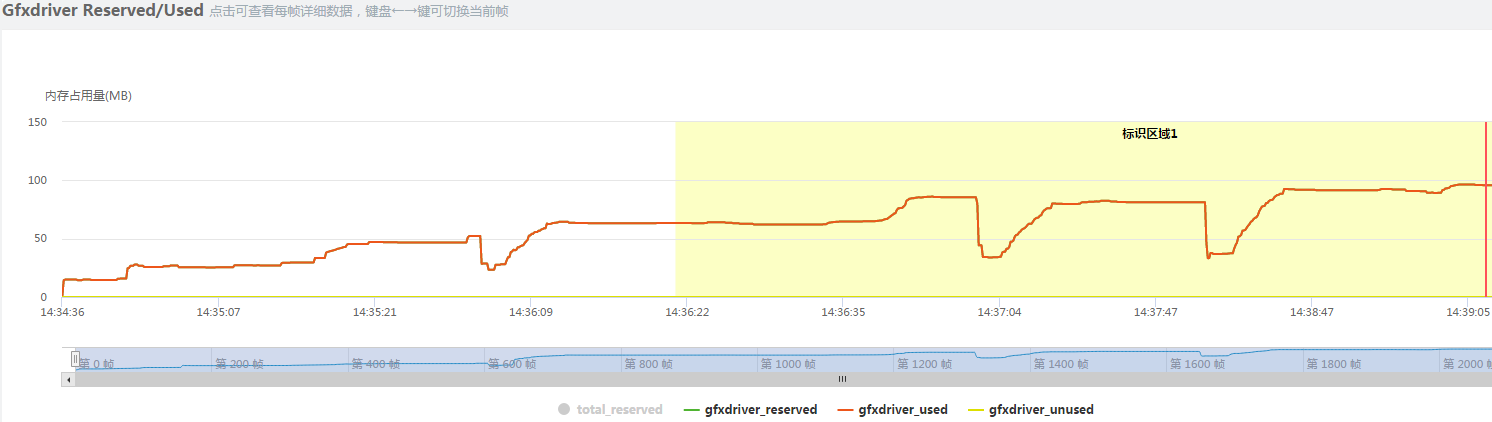
gfxdriver_reserved表示渲染模块的内存,如果比较高需要对纹理资源和Shader进行优化。
fmod_reserved表示音频模块的内存,如果比较高需要对音频资源进行优化。
profiler_reserved表示unity profiler分配的内存,无需关注。
图形
图形模块和GPU耗时相关。
图像概况页签的几个指标:

1)SetPassCalls:
渲染Pass的数目,每个Pass都会消耗对应的一个drawcall,在满足渲染效果的情况下尽可能的减少Pass的数量。
Shader “ShaderLab Tutorials/TestShader"{
SubShader{
Pass
{
//...
}
}}
2)drawcalls:
cpu发送给gpu的渲染请求数,请求中包括渲染对象所有的顶点、三角面、索引值、图元个数等。

3)verts:
摄像机视野内渲染的顶点总数。
4)tris:
摄像机视野内渲染的三角面总数。

5)VRAM usage:
显存的使用情况,它的总大小取决于显卡的显存。

6)VBO Total:
渲染过程中上传到图形卡的网格的数量。

这是合批页签中的概述,表示在标识区域中开启动态合批后平均节省下3.24个drawcall。

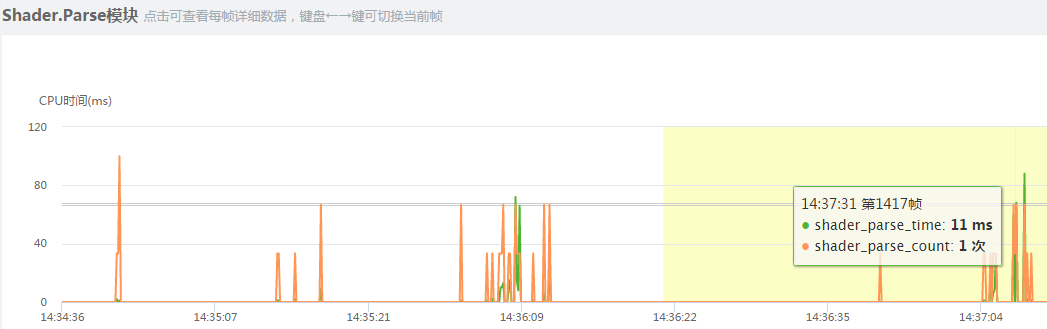
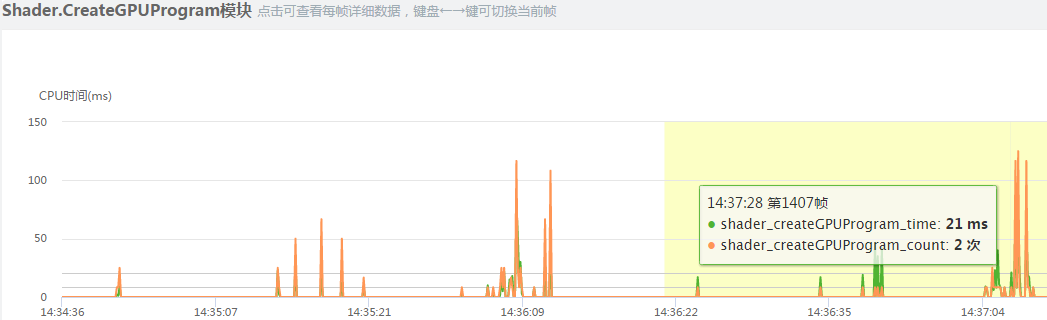
这是模块耗时页签中的概述,Camera.Render表示相机渲染准备工作的cpu耗时;Shader.Parse表示资源加入后untiy引擎对shader的解析耗时。Shader.CreateGPUProgram表示GPU对加载进来的新shader针对目标平台编译的耗时。



附录
1、mono内存测试
条件:手机已root,且系统非android 7.0及以上。
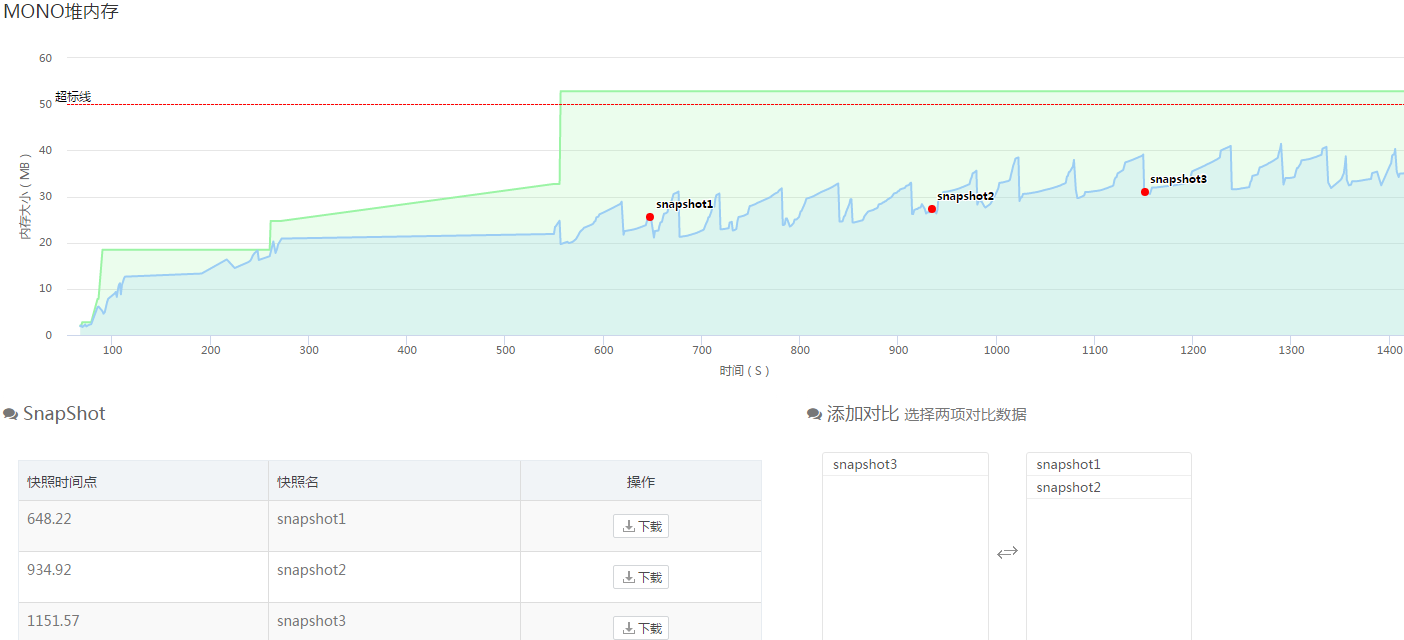
测试方式:在合适的时间点打2次以上的内存快照,进行对比(获取保留和新增的资源类型、对象堆栈、引用次数)。比如主城反复跳转的场景发现mono内存一直在增长,就可以在场景跳转前打一个snapshot1,在场景跳转后打一个snapshot2,最后在场景跳转回原主城再打一个snapshot3。
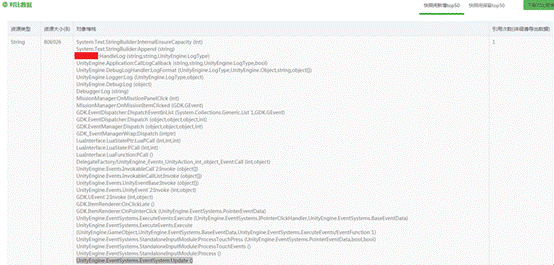
2、资源内存测试
条件:手机已root,且系统非android 7.0以机上。
资源结论:
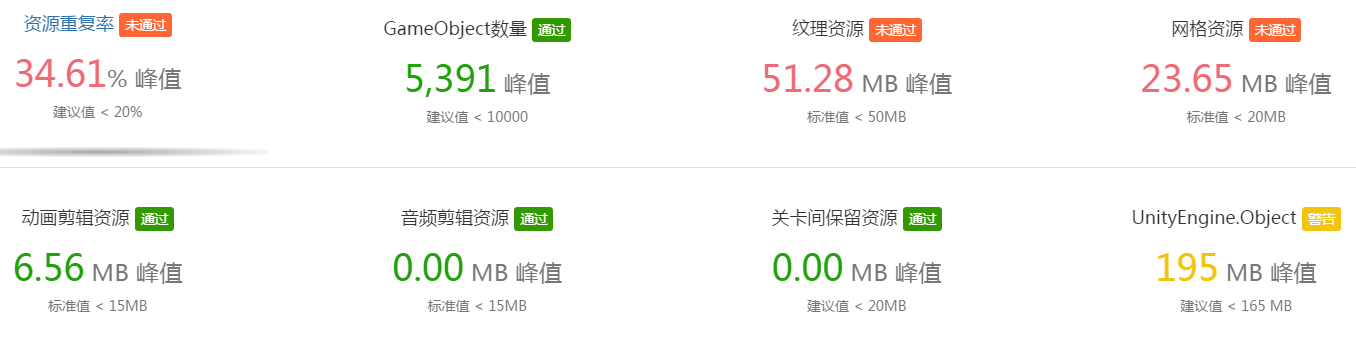
资源重复是指内存中同一时刻,存在两份或以上相同的纹理、网格、动画、音频等资源。一般是相同的一份资源被打包到多个AB包中,如果这些AB都被加载进内存,内存中就会存在多份相同的资源。这个比率是按重复资源的大小除以总资源的大小来算的。
如果资源重复率超标,一般是优先处理资源较大、重复数量较多的纹理或网格。

纹理资源超标,一般优化的方向:
1)纹理用于UI,禁用mipmaps;
2)尽可能降低纹理分辨率,不要超过2048*2048;
3)android尽量使用ETC格式,ios使用PVRTC格式;
4)低配机目前一般不支持openGL3.0,故使用ETC2时会自动转换成RGBA32,纹理占用大概是中高配机的4倍。解决方法是统一改成所有机型都支持的ETC1,一张RGB,一张alpha,渲染时再合并。
网格资源超标,一般优化的方向:
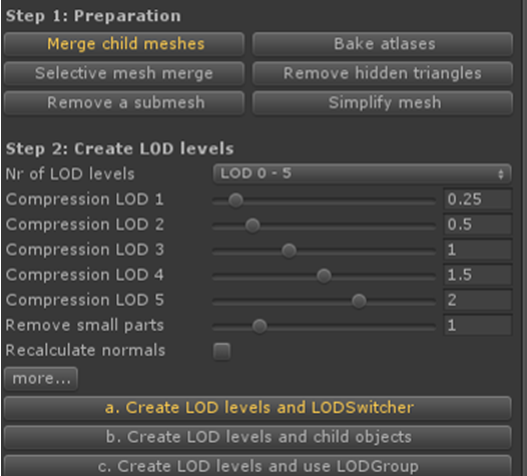
1)减少顶点和三角面数。Simple LOD插件可以用来简化网格资源;
2)如果网格资源数据不进行读写操作,需要将Read/Write Enable关闭。
动画资源超标,一般优化的方向:
1)在不影响表现的前提下,减少Animation的帧数;
2)开启"Optimize GameObject";
3)按需加载,比如在战斗中会有角色站立、死亡、攻击等动画剪辑,这些不用在战斗的每一帧全部加载。

音频资源一般很少超标。
3、Adreno Profiler
比较常用的针对GPU分析的工具有Mali、PowerVR、Adreno Profiler等,比较方便使用的还是高通的显卡分析工具Adreno Profiler。(P.S. 目前adreno profiler不更新了,如果抓取不了游戏单帧,推荐使用intel GPA+模拟器的组合)
使用条件:查看手机是否高通芯片,PC上装有adb环境。
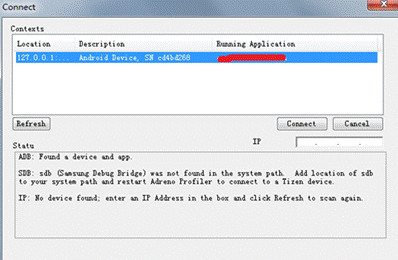
首先手机上打开游戏,运行到需要抓取的界面,然后在PC端打开Adreno Profiler,点左上角的Connect。
双击连接之后,点击Scrubber GL弹出抓取界面,然后点击Caputure Frame等待即可。
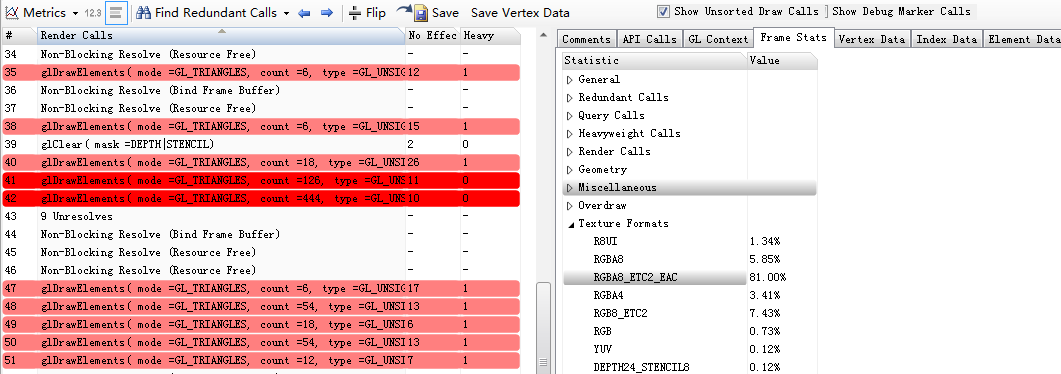
Frame states下查看渲染相关参数:
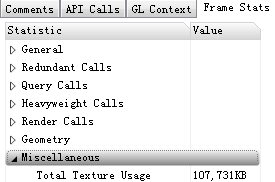
比如Miscellaneous选项下Total Texture Usages为纹理显存使用总量:
比如Texture Formats选项下为纹理格式分布:
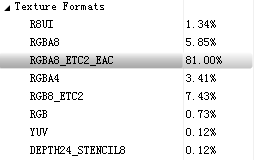

比如Render Calls可视为draw call统计:

左边是抓取到的当前帧的所有绘制指令,鼠标在listview中从上到下点击,可以还原当前帧的绘制过程。
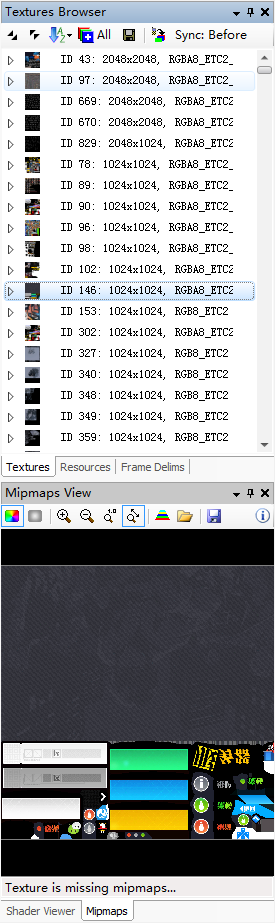
这个是纹理浏览器,是捕获帧加载进来的纹理资源。从上面的截图可以看出来这个图集(将许多单个的纹理合并到一个较大的纹理上)填充的不饱和,可以拆分成1024*512的图集。
也可以发现有一模一样的纹理且重复多个:
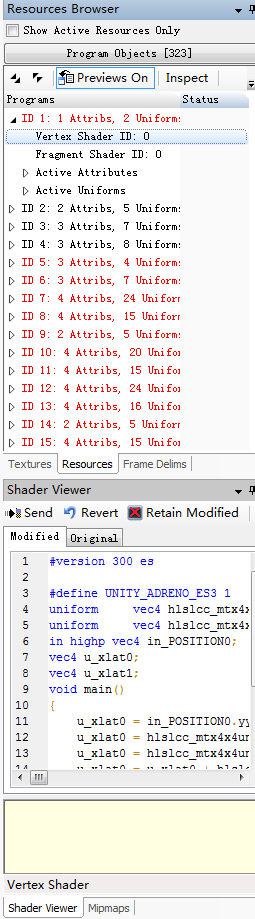
这个是shader浏览器,可以针对一些消耗性能比较大的shader做优化。
vertex shader:顶点着色器,逐顶点计算,计算次数等于顶点数。
fragment shader:像素着色器,逐像素计算,计算次数等于像素数。
一般对于shader优化的建议:
1)在不影响效果输出的情况下减少变量的精度;避免数据类型的转换。
2)减少或避免使用幂函数、指数函数、三角函数等复杂的函数运算,使用近似方程替代。
怎样查看shader优化后,性能是否提升了呢?
这里要使用Grapher->App Metris Graph里的一些监测指标进行优化前后的对比:
EGL(FPS)
GPU General(%Busy)
GPU Shader Processing(%Shaders Busy,%Time Shading Fragment/Vertices)
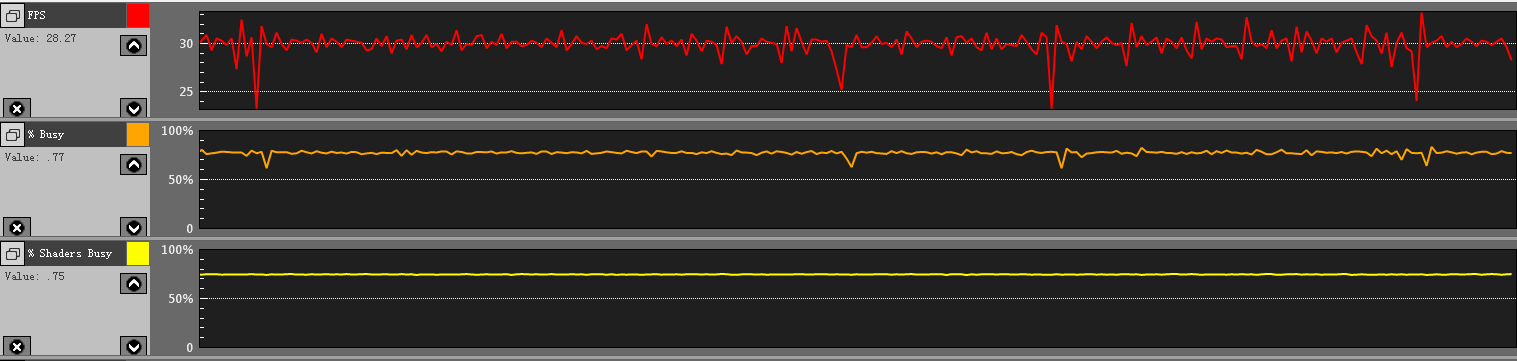
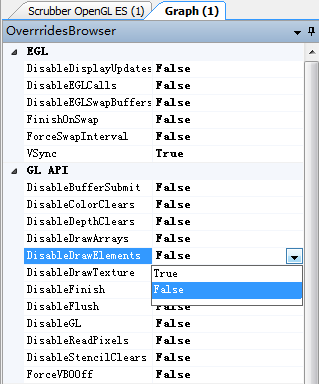
另外还有一些可以进行覆盖测试,比如fps均值比较低,那到底是CPU还是GPU造成的瓶颈呢?将DisableDrawElements替换为false,看FPS和GPU General(%Busy),如果有较大变化则是GPU造成的瓶颈。
最后对GPU瓶颈识别做个总结:

欢迎使用WeTest UPA,无需ROOT或接入SDK,认证用户即享60分钟使用时长,点击:http://wetest.qq.com/product/cube 即可下载。
如果使用当中有任何疑问,欢迎联系腾讯WeTest企业QQ:2852350015