系统启动一个新线程的成本是比较高的,因为它涉及到与操作系统交互。在这种情形下,使用线程池可以很好地提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
与数据库连接池类似的是,线程池在系统启动时即创建大量空闲的线程,程序将一个Runnable对象传给线程池,线程池就会启动一条线程来执行该对象的run方法,当run方法执行结束后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个Runnable对象的run方法。
使用线程池可以有效地控制系统中并发线程的数量,当系统中包含大量并发线程时,会导致系统的性能下降,甚至导致JVM崩溃,而线程池的最大线程参数可以控制系统中并发线程数不能超过此数。
一、使用线程池管理线程
1.1 Executor工厂类的方法——创建线程池
JDK1.5提供了一个Executors工厂类来产生线程池,该工厂类里包含如下几个静态工厂方法来创建连接池:
(1)newCachedThreadPool():创建一个具有缓存功能的线程池,系统根据需要创建线程,这些线程将会被缓存在线程池中。
(2)newFixedThreadPool(int nThreads):创建一个可重用的、具有固定线程数的线程池。
(3)newSingleThreadExecutor():创建一个只有单线程的线程池,它相当于newFixedThreadPool方法时传入参数为1。
(4)newScheduledThreadPool(int corePoolSize):创建具有指定线程数的线程池,它可以在指定延迟后执行线程任务。corePoolSize指池中所保存的线程数,即使线程是空闲的也被保存在线程池内。
(5)newSingleThreadScheduledExecutor():创建只有一条线程的线程池,它可以在指定延迟后执行线程任务。
(6)ExecutorService newWorkStealingPool(int parallelism):创建持有足够线程的线程池来支持给定的并行级别,该方法会使用多个队列来减少竞争。
(7)ExecutorService newWorkStealingPool():该方法是上一个方法的简化版本。如果当前机器有4个CPU,则目标并行级别被设置为4,也就是相当于为前一个方法传入4作为参数。
上面7个方法中的前3个方法返回一个ExecutorService对象,该对象代表一个线程池,它可以执行Runnable对象或Callable对象所代表的线程;
(4)(5)两个方法返回一个ScheduledExecutorService线程池,它是ExecutorService的子类,它可以在指定延迟后执行线程任务;
(6)(7)两个方法是Java 8新增的,可以充分利用多CPU并行能力。这两个方法生成work stealing池,都相当于后台线程池,如果所有的前台线程都死亡了,work stealing池中的线程会自动死亡。
1.2 ExecutorService对象——执行Runnable或Callable对象
ExecutorService代表尽快执行线程的线程池(只要线程池中有空闲线程立即执行线程任务),程序只要将一个Runnable对象或Callable对象(代表线程任务)提交给该线程池即可,该线程池就会尽快执行该任务。ExecutorService里提供了如下三个方法:
(1)Future<?> submit(Runnable task):将一个Runnable对象提交给指定的线程池。线程池将在有空闲线程时执行Runnable对象代表的任务。其中Future对象代表Runnable任务的返回值——但run方法没有返回值,所以Future对象将在run方法执行结束后返回null。但可以调用Future的isDone()、isCancelled()方法来获得Runnable对象的执行状态。
(2)
(3)
1.3 ScheduledExecutorService对象——在指定延迟,或周期性执行线程任务的线程池
ScheduledExecutorService代表可在指定延迟,或周期性执行线程任务的线程池,它提供了如下四个方法:
(1)ScheduledFuture
(2)ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit):指定command任务将在delay延迟后执行。
(3)ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit):指定command任务将在delay延迟后执行,而且以设定频率重复执行。也就是说,在initialDelay后开始执行,依次在 initialDelay+period 、initialDelay + 2 * period...处重复执行,依此类推。
(4)ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit):创建并执行一个在给定初始延迟后首次启用的定期操作,随后,在每一次执行终止和下一次执行开始之间都存在给定的延迟。如果任务的任一次执行时遇到异常,就会取消后续执行。否则,只能通过程序来显式取消或终止来终止该任务。
1.4 线程池的shutdown()和shutdownNow()
用完一个线程池后,应该调用该线程池的shutdown()方法,该方法将启动线程池的关闭序列,调用shutdown()方法后的线程池不再接受新任务,但会将以前所有已提交的任务执行完成。当线程池中的所有任务都执行完成后,池中的所有线程都会死亡;
另外也可以调用线程池的shutdownNow()方法来关闭线程池,该方法试图停止所有正在执行的活动任务,暂停处理正在等待的任务,并返回等待执行的任务列表。
1.5 使用线程池的步骤
(1)调用Executors类的静态工厂方法创建一个ExecutorService对象或ScheduledExecutorService对象,其中前者代表简单的线程池,后者代表能以任务调度方式执行线程的线程池。
(2)创建Runnable实现类或Callable实现类的实例,作为线程执行任务。
(3)调用ExecutorService对象的submit方法来提交Runnable实例或Callable实例;或调用ScheduledExecutorService的schedule来执行线程。
(4)当不想提交任何任务时调用ExecutorService对象的shutdown方法来关闭线程池。
下面程序使用线程池来执行Runnable对象所代表任务:
package section8;
import java.util.concurrent.*;
public class ThreadPoolTest
{
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建一个具有固定线程数(6)的线程池
ExecutorService pool= Executors.newFixedThreadPool(6);
//使用Lambda表达式创建Runnable对象
Runnable target=()->{
for(var i=0;i<10;i++)
{
System.out.println(Thread.currentThread().getName()+" 当前变量i的值为:"+i);
}
};
//创建Callable对象
Callable<Integer> a=()->{
int count=0;
for(var i=0;i<10;i++)
{
System.out.println(Thread.currentThread().getName()+" 当前变量i的值为"+i);
count=count+1;
}
return count;
};
//使用FutureTask对象封装该Callable对象的call()方法的返回值
FutureTask<Integer> task=new FutureTask<>(a);
//向线程池提交两个线程
pool.submit(target);
pool.submit(task);
System.out.println("Callable对象的call()方法的返回值:"+task.get());
//关闭线程池
pool.shutdown();
}
}
pool-1-thread-2 当前变量i的值为0
pool-1-thread-1 当前变量i的值为:0
pool-1-thread-2 当前变量i的值为1
pool-1-thread-1 当前变量i的值为:1
pool-1-thread-2 当前变量i的值为2
pool-1-thread-1 当前变量i的值为:2
pool-1-thread-2 当前变量i的值为3
pool-1-thread-1 当前变量i的值为:3
pool-1-thread-2 当前变量i的值为4
pool-1-thread-1 当前变量i的值为:4
pool-1-thread-2 当前变量i的值为5
pool-1-thread-1 当前变量i的值为:5
pool-1-thread-2 当前变量i的值为6
pool-1-thread-1 当前变量i的值为:6
pool-1-thread-2 当前变量i的值为7
pool-1-thread-1 当前变量i的值为:7
pool-1-thread-2 当前变量i的值为8
pool-1-thread-1 当前变量i的值为:8
pool-1-thread-2 当前变量i的值为9
pool-1-thread-1 当前变量i的值为:9
Callable对象的call()方法的返回值:10
上面程序创建了Runnable实现类、Callable实现类和Future实现类,这里并没有之间创建线程、启动线程来运行,而是通过线程池来执行该任务。可以看到两个任务交替执行的效果。
二、使用ForkJoinPool利用多CPU
为了充分利用多CPU、多核CPU的性能优势,计算机系统应该可以充分“挖掘”每个CPU的计算能力,绝不能让每个CPU处于空闲状态。为了充分利用多CPU、多核CPU的优势,可以考虑把一个任务拆分成多个“小任务”,把多个小任务放到多个处理器核心并行执行;当多个“小任务”执行完成后,再将这些执行结果合并起来即可。
Java 7提供了ForkJoinPool来支持将一个任务拆分为多个“小任务”并行计算能力,再把多个结果合成总的计算结果。ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池。
ForkJoinPool提供如下两个构造器:
(1)ForkJoinPool(int parallelism):创建一个包含parallelism个并行线程的parallelism。
(2)parallelism:以Runtime.Processors()方法的返回值作为parallelism参数来创建ForkLoinPool.
java 8进一步扩展了ForkJoinPool的功能,Java 8为ForkJoinPool增加了通用池的功能。ForkJoinPool类通过如下两个静态方法提供通用池功能:
(1)ForkJoinPool commonPool():该方法返回一个通用池,通用池的运行状态不会受shutdown()或shutdownNow()方法的影响。当然程序可以直接执行System.exit(0);来终止虚拟机,通用池中正在执行的任务都会被自动终止。
(2)int getCommonPoolParallelism():该方法返回通用池的并行级别。
创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinPool task)或invoke(ForkJoinPool task)方法来执行任务。其中ForkJoinTask代表一个可以并行、合并的任务。ForkJoinTask是一个抽象类,它还有两个抽象子类:RecursiveAction和RecursiveTask。其中RecursiveTask代表有返回值的任务,而RecursiveAction代表没有返回值的任务。
下图显式了ForkJoinPool、ForkJoinTask等类的类图。
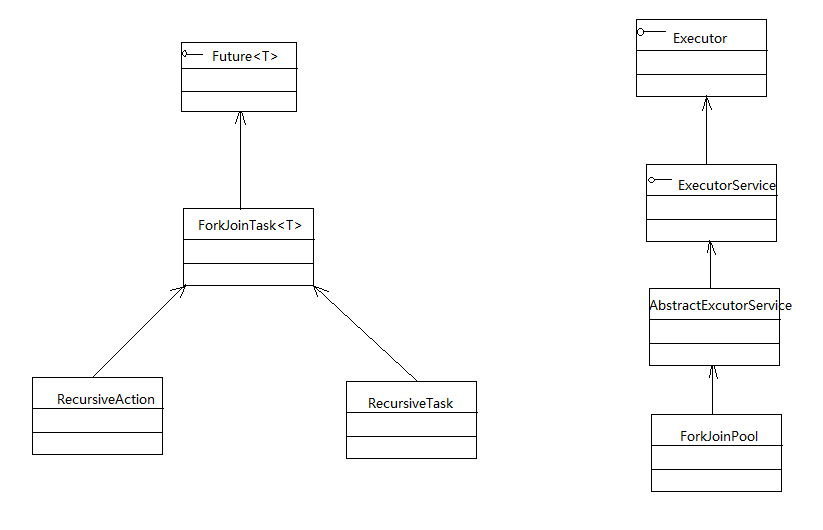
下面以执行返回值的“大任务”(简单地打印0-300的数值)为例,程序将一个"大任务"拆分成多个小任务,并将任务交给ForkJoinPool来执行。
package section8;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.TimeUnit;
//继承RecursiveAction来实现“可分解”的任务
class PrintTask extends RecursiveAction
{
//每个小任务最多打印50个数
private static final int THRESHOLD=50;
private int start;
private int end;
//打印从start到end之间的数
public PrintTask(int start,int end)
{
this.start=start;
this.end=end;
}
@Override
protected void compute() {
//当end和start之间的差小于THRESHOLD时,开始打印
if(end-start<THRESHOLD)
{
for(var i=start;i<end;i++)
{
System.out.println(Thread.currentThread().getName()+"的i的值:"+i);
}
}
else
{
//当end与start之间的差大于THRESHOLD,即打印的数超过50个
//将大任务分解成两个小任务
int middle=(start+end)/2;
var left=new PrintTask(start,middle);
var right=new PrintTask(middle,end);
//并行执行两个“小任务”
left.fork();
right.fork();
}
}
}
public class ForkJoinPoolTest
{
public static void main(String[] args) throws InterruptedException {
var pool=new ForkJoinPool();
//提交可分解的PrintTask任务
pool.submit(new PrintTask(0,300));
pool.awaitTermination(2, TimeUnit.SECONDS);
//关闭线程
pool.shutdown();
}
}
上面程序中PrintTask类实现了对执行打印任务的分解,分别后的任务调用fork()方法开始并行运行。运行上面的程序将看到如图所示的结果:
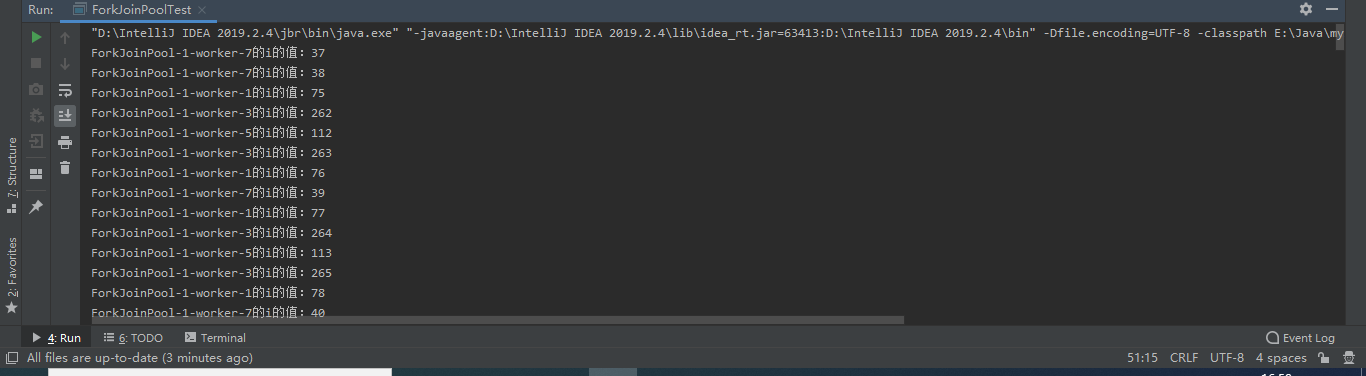
从上图执行结果来看,ForkJoinPool启动了4个线程(1,3,5,7)来执行这个打印任务——这是因为测试计算机的CPU是4核的。不仅如此,程序打印0-300之间的数不是连续的。这是因为程序将任务进行分解,分解后的任务并行运行,所以不会按顺序打印0-299。
上面定义的任务是一个没有返回值的打印任务,如果大任务是有返回值的任务,则可以让任务继承RecursiveTask
package section8;
import java.util.Random;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
//继承RecursiveTask来实现“可分解”的任务
class CalTask extends RecursiveTask<Integer>
{
//每个任务最多累加20个数
private static final int THRESHOLD=20;
private int arr[];
private int start;
private int end;
//累加从start到end的数组元素
public CalTask(int[] arr,int start,int end)
{
this.arr=arr;
this.start=start;
this.end=end;
}
@Override
protected Integer compute() {
int sum=0;
//当end与start之间的差小于THRESHOLD时,开始进行累加
if(end-start<THRESHOLD)
{
for(var i=start;i<end;i++)
{
sum+=arr[i];
}
return sum;
}
else
{
//当end与start之间的差大于THRESHOLD,即需要累加的数超过20
//将大任务分解成小任务
int middle=(start+end)/2;
var left=new CalTask(arr,start,middle);
var right=new CalTask(arr,middle,end);
//并行执行两个程序
left.fork();
right.fork();
//把小任务累加的结果合并起来
return left.join()+right.join();//①
}
}
}
public class Sum
{
public static void main(String[] args)
throws Exception
{
var arr=new int[100];
var rand=new Random();
var total=0;
//初始化100个数字元素
for(int i=0;i<100;i++)
{
int temp=rand.nextInt(20);
//对数组元素赋值,并将元素的值添加到sum总和中
arr[i]=temp;
total+=temp;
}
System.out.println("直接累加计算得到的结果:"+total);
//创建一个通用池
ForkJoinPool pool=ForkJoinPool.commonPool();
//提交可分解的CalTask任务
Future<Integer> future=pool.submit(new CalTask(arr,0,arr.length));
System.out.println("线程池运行结果:"+future.get());
//关闭线程池
pool.shutdown();
}
}
直接累加计算得到的结果:1011
线程池运行结果:1011
与前一个程序基本类似,同样是将任务进行了分解,并调用分解后的任务的fork()方法是它们并行执行。与前一个程序不相同的是,现在的任务是带返回值的,因此程序还在①号代码出将两个任务的返回值进行了合并。