1、python中bytes和str
Python3 最重要的新特性大概要算是对文本(text)和二进制数据(binary data)作了更为清晰的区分
(1)Python 3.0使用文本和(二进制)数据的概念而不是Unicode字符串和8位字符串。所有文本都是Unicode; 但编码的 Unicode表示为二进制数据。用于保存文本str的类型是用于保存数据的类型 bytes。与2.x情况的最大区别在于,任何在Python 3.0中混合文本和数据的尝试都会提高 TypeError,而如果你要在Python 2.x中混合使用Unicode和8位字符串,那么如果8位字符串可以使用它碰巧只包含7位(ASCII)字节,但UnicodeDecodeError如果它包含非ASCII值,则会得到 。多年来,这种特定价值的行为造成了许多悲伤的面孔。、
(2)您不能再将u"..."文字用于Unicode文本。但是,您必须将b"..."文字用于二进制数据。
(3)由于str和bytes类型不能混合,因此必须始终在它们之间进行显式转换。使用str.encode() 从去str到bytes,并bytes.decode() 从去bytes到str。你也可以分别使用bytes(s, encoding=...) 和str(b,encoding=...).
>>> b=b'good'
>>> print(type(b))
<class 'bytes'>
>>> str(b3,encoding='utf-8')
'example'
>>> print(type(str(b3,encoding='utf-8')))
<class 'str'>
>>>
4)原始字符串文字中的所有反斜杠都按字面解释。这意味着原始字符串中的转义'U'和'u'转义不会被特别处理。例如,r'u20ac'Python 3.0中是一个包含6个字符的字符串,而在2.6中,ur'u20ac'则是单个“euro”字符。(当然,此更改仅影响原始字符串文字;欧元字符'u20ac'在Python 3.0中。
总结bytes和str的区别:
1、bytes(一堆二进制的数字,如:b'11001010')主要是给在计算机看的,string主要是给人看的
首先计算机能存储的唯一东西就是 bytes。所以为了在计算机中存储东西,我们首先得将其编码(encode),例如将其转化为 bytes。比如:
要想保存音乐,我们首先得用 MP3, WAV 等将其编码
要想保存图片,我们首先得用 PNG, JPEG 等将其编码
要想保存文本,我们首先得用 ASCII, UTF-8 等将其编码
Unicode 是字符集,不是字符编码。Unicode 把全世界的字符都搜集并且编号了,但是没有规定具体的编码规则。编码规则有 UTF-8、GBK 之类的。
Python3 不会以任意隐式的方式混用 str 和 bytes。正是这使得两者的区分特别清晰,你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
2、中间有个桥梁就是编码规则,现在大趋势是utf8
例如:在编辑和保存文件时,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

3、bytes对象是二进制,很容易转换成16进制,例如x64
4、string就是我们看到的内容,例如'abc'
5、string经过编码encode,转化成二进制对象,给计算机识别
6、bytes经过反编码decode,转化成string,让我们看,但是注意反编码的编码规则是有范围,xc8就不是utf8识别的范围
2、bytes和str的相互转换
(1)string to bytes
按 utf-8 的方式编码,转成 bytes
1 >>> string='good job' #str类型 2 >>> str_to_byte=string.encode('utf-8') #转换为bytes类型 3 >>> type(string) 4 <class 'str'> 5 >>> type(str_to_byte) 6 <class 'bytes'> 7 >>> print(str_to_byte) 8 b'good job' 9 >>>
按 gb2312 的方式编码,转成 bytes
>>> str_t_bytes=string.encode('gb2312')
>>> type(str_t_bytes)
<class 'bytes'>
>>> print(str_t_bytes)
b'good job'
>>>
(2)bytes 转换为s't'r
解码成 string,默认不填
>>> website_string = website_bytes_utf8.decode() >>> type(website_string) <class 'str'> >>> website_string
>>>'http://www.jb51.net/'
解码成 string,使用 gb2312 的方式
>>> str='good job' >>> website_bytes_gb2312=str.encode('gb2312') >>> type(website_bytes_gb2312) <class 'bytes'> >>> website_string_gb2312=website_bytes_gb2312.decode('gb2312') <class 'str'> >>> website_string_gb2312 'good job' >>>
补充:字符编码
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字(二进制)才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
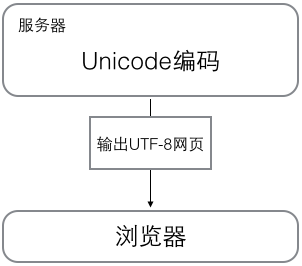
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。