开发背景
在使用销帮帮的时候错误的将签订时间和开始时间弄错了,造成开始时间是正确的签订时间,签订时间是正确的开始时间。在2020年前需要把错误数据处理掉。
解决方案
方案一:可以通过导入导出功能,把数据导出来,然后更新字段后重新导入进去。
缺点:由于有同名的人员,销帮帮的导入不能正确处理同名的人员信息,所以该方案否决。
方案二:通过销帮帮API更新数据,通过咨询销帮帮的相关技术负责人,确定更新时,不需要拿到所有的数据,更新那个字段就修改那个字段即可,类似于SQL:
Update Table Set Field1=Value1 where ID=1 的格式。感觉可行
中间遇到的问题:通过接口API测试时,发现如果修改了字段后,会重新走审批流程。确定这是API的错误,销帮帮会修改该问题。
由于时间紧张,而销帮帮的问题修复需要时间,所以暂时把签订、开始时间从审批中去掉解决该问题。 确定方案可行
方案三:通过模拟修改数据,可以通过抓包模拟正常操作进行数据修改
缺点:1、需要知道所有的字段,然后更新的时候也要更新所有的字段。不能实现类似Update Table Set Field=Value Where ID=1 格式的修改
2、 需要实现查询、数据分析、然后更新 抓包比APi复杂。不采用该方法。
开发逻辑
通过【合同订单列表接口】抓取合同的列表信息
在抓取合同列表信息时发现的问题
1、 隐藏的字段是不显示的,虽然这些字段在审批时会用到,但是依然不显示。
2、 技术问题:由于数据是Json格式的,不想写个固定的类,然后NewtonSoft去转换,采用了dynamic 类型,只要找到自己要的几个字段即可。
3、 为了试试技术能力,还特意想吧Json的所有的字段都采集下来,然后整理成一张SQL表,方便查询所有的数据。Json的dynamic后只有JArray/JObject/JValue/JProperty 4中类型,根据4种类型遍历 然后整理成 Key=Value类型的数据存储到一张表里即可。根据需要列转行即可。
4、 为了确定数据处理过,准备一张表保存已经处理过的数据,保证不重复处理。
5、 为了省事,还专门准备了Dapper进行数据库处理,在处理过程中发现Dapper对数据库的批量入库并不友好。自己又写了个SQLBulkCopy 来进行批量入库,开始的时候10条/秒的速度入库,后来读完即可完成入库。总共468083条数据,好庆幸写了SQLBulkCopy 否则不知道采集一次到什么时候了。
软件使用教程
习惯了VS开发各种工具,所以还是使用C#+SQLServer开发
以前作爬虫留下的习惯,所有的方法只完成一个功能,数据通过队列进行中转,比如采集只需要把数据采集下来,然后分析的另起线程进行分析,数据分析完后,有专门的线程进行保存入库,有专门的队列保存执行日志,专门的线程显示日志。
1、 采集合同列表信息
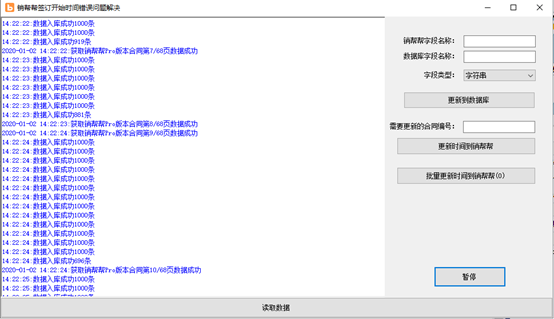
首先点击按钮开始,按照分页采集合同列表信息,如下图。等待提示全部采集完成后,开始分析数据
2、 数据分析
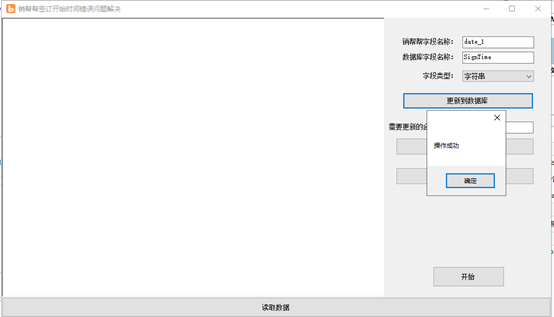
通过SQL初始化合同信息基本信息,ID,编号,通过【更新到数据库】按钮整理需要的字段到合同表中。
在销帮帮字段名称、数据库字段名称中输入需要转换的字段名称,选择字段类型,如果是字符串,直接复制;如果是时间类型,则转换为标准的年-月-日 时:分:秒格式的数据;如果是枚举类型,则根据枚举值获取枚举描述信息。
3、 数据分析后,会把需要把数据都整理到合同表中
4、 数据处理更新到销帮帮
数据处理可以分为批量数据处理、单条数据处理。根据已经采集到数据库的信息进行批量的销帮帮数据更新,更新后在对应的表中保存已修改状态,防止重复修改。并在销帮帮新增系统备注字段标识:已经处理 2步验证 防止重复修改。
为了快熟处理特定条目的数据,可以通过【更新时间到销帮帮】按钮单条修改合同信息,在上面的文本框输入合同编号,然后点击下方的【更新时间到销帮帮】按钮更新单条合同信息。

总结
通过这次小工具的开发,感觉还是没有准备好各种基础工具类,包括ORM标准类,日志处理标准类、Http采集标准类等。
唯一有点挑战的也就是系统标准化、枚举匹配、递归函数处理。
这次的Json处理,感觉NOSQL越来越近了,很多东西都不能通过关系型数据库关联起来了。如果非要关联起来会非常的麻烦,比如这次的合同表就有合同基本信息、模版信息、负责人、协同人、附件等信息整个而成。如果整理成关系型数据库最少得4张表。
各有优劣吧

