开发环境
C#+SQLite
软件使用教程:
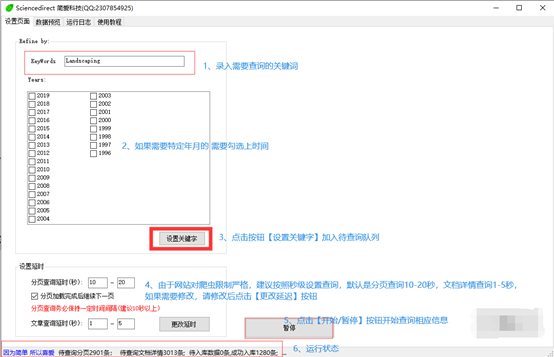
设置页面
1、 首先录入需要查询的关键词,如果需要根据年去查询,可以勾选对应的年,支持多个年份查询。点击【设置关键字】按钮,把待查询关键字加入查询队列。
2、 根据需要修改分页延时和文章查询延时信息,修改后点击【更改延时】按钮生效。
3、 点击【开始/暂停】按钮控制查询操作。
4、 最下方显示待查询的分页数、待查询文章数量、待入库数据数量和已入库数据数量。

运行日志
执行的每一步操作都会有相应的文件描述显示在日志中,包括查询分页、查询文档、运行出错、数据入库、数据校验等所有的日志信息。
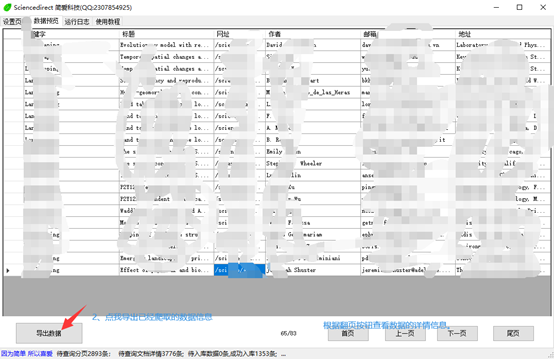
数据预览
所有的数据都会实时存储到SQLite数据库中,数据会永久保存。数据预览主要功能就是分页查询、数据导出功能。
如果不需要该数据后可以删除软件目录下的data.db文件。
开发过程中的问题汇总
数据抓取
所有爬虫的难点从来不是技术,而是网站的数据分析,表面看到的数据可能与想象中的显示有区别。比如文章详情的作者信息等就是通过js处理Json格式数据展示的。为了找到具体的数据需要解析整个Json数据。
Json数据也不是最难得,分析Json数据才是最难得。
KeyValue格式的数据Key=“$”/”$$”/”_”/”Get-Text”等等,总之C#怎么不兼容怎么来。
针对上述数据我能想到的有2中解决方案:
1、 对所有的数据遍历 key/value,然后根据key对应的name或者value的值进行匹配然后获取数据信息。
2、 由于dynamic支持动态类型,所以只要key可以作为变量就能根据名字写死处理。为了能拿到符合规则的名字,只好Replace。
我是不是很聪明,哈哈。
关于IP限制
限制IP无疑是一个很好的手段,针对IP限制,只能放缓查询速度。
再次我通过简单的随机时间访问和访问完一个网页后在访问下一个网页的办法来防止IP被封。
关于网站未来
为了更好的适应网站的查询条件,比如年,会显示从1996年到当前时间的年份。
运行日志
为了更明显的显示日志信息,把执行成功的标记为蓝色,失败的标记为红色。
关于Dapper
刚刚接触Dapper的时候,把他当作一个完美的DbHelper使用的。后来发现无论是事务、确认数据是否存在、先查后插入都需要自己去完整,我心目中的完美Dapper啊

不过SQLite还是比SQLServer有好的地方的,
比如Create Table If Not Exists TableName
比如 Replace Into 减少了很多代码量
数据导出
导出数据到Excel,NPOI永远是利器。
待处理问题
数据中如果存在上下标,还不知道怎么处理和保存。万能的百度没有帮到我,Unicode中不知道a的上标是什么,下标也没有成功显示。求大神们指点…
