一直很讨厌存储过程,没想到今天帮了我大忙啊,或许会因为今天让我慢慢喜欢上存储过程吧,不多说了,切入正题
在使用数据库的时候,难免要在使用过程中进行删除的操作,如果是使用int类型的字段,令其自增长,这是个最简单的办法,但是后果会有些不是你想要的!看下这个Demo:


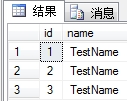
1.建立这样的简单的表Test.
2.设置字段id的自增.
3.表添加数据
insert into Test(name) values('TestName')
insert into Test(name) values('TestName')
insert into Test(name) values('TestName')
4.你会看到
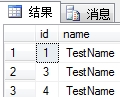
5.在这里我们删除id为2的行.就只剩下了id为1和id为3的两行数据了.(不上图了)
6.再添加一条数据.
insert into Test(name) values('TestName')
我们会发现这或许不是我们想要的结果了
为什么没有id为2的呢? 之后任你死命的加,也不会有id为2的数据行了!
这样的设计固然方便,但是魔鬼在于细节,这篇博客就是为了解决这个问题让我们重新见到id为2的数据行(这里顺便改进一下,让结果不只是显示id为2这样的int,假如有一天我们的各户要求我们他们要一个5位数的id号吗,从00000开始,OK,这没问题)
1.主角登场,存储过程终于派上了用场了
Create procedure [dbo].[insertName]
(@name nvarchar(50))
as
begin
declare @i int
set @i=1
while(@i<10000)
begin
if exists(select convert(int,id) from numbertest where convert(int,id)=@i)
begin
set @i=@i+1
continue
end
else
begin
insert numbertest values(right('0000'+convert(varchar(5),@i),5),@name)--这里的两个数字'5' 就是我们要设置的id长度
break
end
end
end
2.用SQL 语句调用这个存储过程 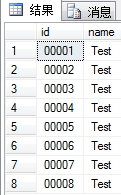
这样的设计固然方便,但是魔鬼在于细节,这篇博客就是为了解决这个问题让我们重新见到id为2的数据行(这里顺便改进一下,让结果不只是显示id为2这样的int,假如有一天我们的各户要求我们他们要一个5位数的id号吗,从00000开始,OK,这没问题)
1.主角登场,存储过程终于派上了用场了
Create procedure [dbo].[insertName]
(@name nvarchar(50))
as
begin
declare @i int
set @i=1
while(@i<10000)
begin
if exists(select convert(int,id) from numbertest where convert(int,id)=@i)
begin
set @i=@i+1
continue
end
else
begin
insert numbertest values(right('0000'+convert(varchar(5),@i),5),@name)--这里的两个数字'5' 就是我们要设置的id长度
break
end
end
end
2.用SQL 语句调用这个存储过程
execute insertName Test
你可以狂按几次,几十次,几百次,我们要的数据加进去了,
我们可以删除指定的id数据行,当我们再次进行添加的时候,之前被删掉的id行,将会被我们新添加的数据所覆盖,这样id就都可以连接起来了.
哦,对了,还没有说如何显示的是 '0' 开头的呢?这个简单,将id的数据类型设置为nvarchar(5),就是这么简单!呵呵!
总结:
这里我们调用了存储过程,存储过程不宜多用,但是有的时候还真是用起来很方便,本文章对于刚刚工作的童鞋们应该还是有点帮助的吧,好好学习吧,生活很美好!
如释重负的感觉啊,终于搞定一个问题,在这里感谢帮助我的童鞋们! 下次再会!
总结:
这里我们调用了存储过程,存储过程不宜多用,但是有的时候还真是用起来很方便,本文章对于刚刚工作的童鞋们应该还是有点帮助的吧,好好学习吧,生活很美好!
如释重负的感觉啊,终于搞定一个问题,在这里感谢帮助我的童鞋们! 下次再会!