1.数据库相关概念
数据库 :保存有组织的数据的容器(一个文件或一组文件),即一个以某种有组织的方式存储的数据集合.
数据库管理系统:数据库软件(DBMS).
表:结构化文件,可以用来存储某种特定类型的数据.
列:表是由列组成,列是表中的一个字段,所有表都是由一个或多个列组成的.列中存储着表中某部分的信息.
数据类型:所容许的数据的类型.
行:表中的一个记录.水平行,垂直列.
模式:可以用来描述数据库中特定的表以及整个数据库,关于数据库和表的布局及特性的信息.
SQL:结构化查询语言,一种专门用来与数据库通信的语言.
MYSQL:一种DBMS,是一种数据库软件.
2. 排序检索数据
排序检索数据:select语句的order by子句
//order by 位置,位于from、where之后,limit之前 select * from proucts order by prod_price DESC limit 1
3. 过滤数据
过滤数据:使用where子句-操作符:检查单个值、不匹配检查、范围值检查、空值检查
条件操作符:
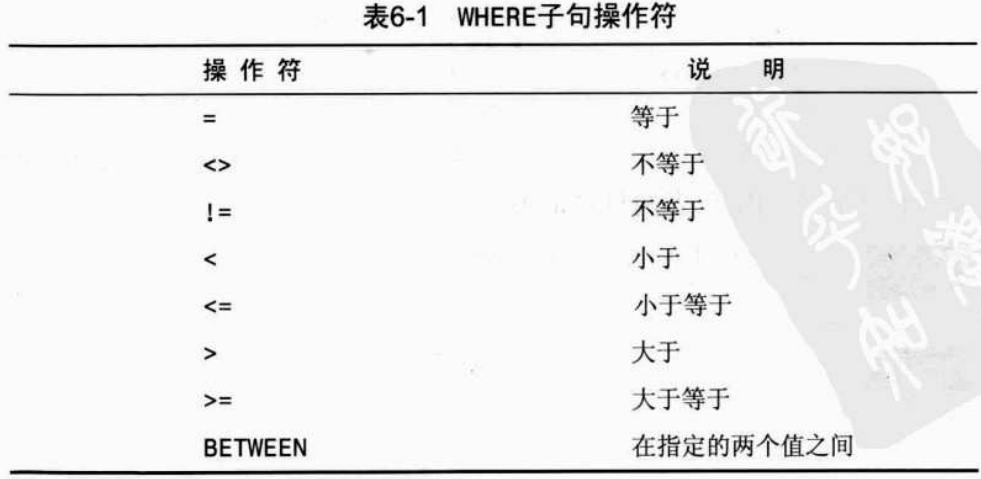
#检查单个值、不匹配检查、范围值检查、空值检查 select * from proucts where pro_name='fuses'; select * from proucts where pro_price < 10; select * from proucts where vend_id <> 1003; select * from proucts where pro_price between 5 and 10; #范围值检查 select * from proucts where pro_price is null; #空值检查,返回没有价格的所有产品
4. 数据过滤
数据过滤:组合where子句(and、or、in、not)、计算次数
#数据过滤:组合where子句(and、or、in、not)、计算次序 select * from proucts where vend_id =1002 and pro_price =10; select * from proucts where vend_id =1002 or vend_id =1003; select * from proucts where (vend_id =1002 or vend_id =1003) and pro_price >= 10;#计算次序,and优先级高,需要用分组(括号)进行计算次序 select * from proucts where pro_price in (5,10); select * from proucts where pro_price not in (5,10);
5. 用通配符进行过滤
通配符:用来匹配值的一部分的特殊字符。比如百分号(%)、下划线(_)
搜索模式:由字面量、通配符或两者组合构成的搜索条件。
#%表示任何字符出现任意次数[0、1、无数],区分大小写 select * from proucts where pro_price like 'jet%'; #_表示匹配一个字符 select * from proucts where pro_price like '_ ton anvil';
6. 用正则表达式进行搜索




正则表达式作用:将一个模式(正则表达式)与一个文本串进行比较。
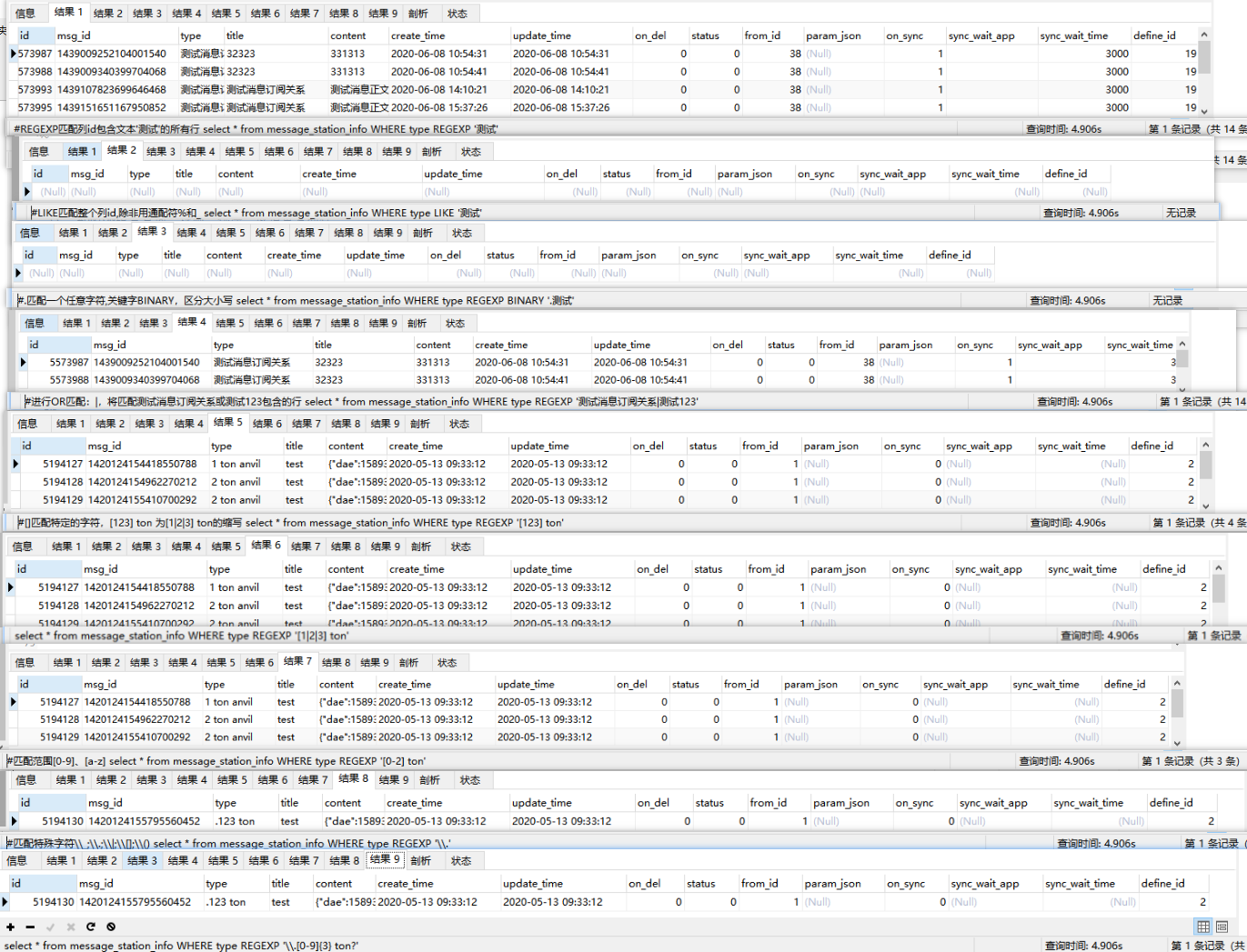
#REGEXP匹配列id包含文本'测试'的所有行 select * from message_station_info WHERE type REGEXP '测试' ; #LIKE匹配整个列id,除非用通配符%和_ select * from message_station_info WHERE type LIKE '测试' ; #.匹配一个任意字符,关键字BINARY,区分大小写 select * from message_station_info WHERE type REGEXP BINARY '.测试' ; #进行OR匹配:|,将匹配测试消息订阅关系或测试123包含的行 select * from message_station_info WHERE type REGEXP '测试消息订阅关系|测试123' ; #[]匹配特定的字符,[123] ton 为[1|2|3] ton的缩写 select * from message_station_info WHERE type REGEXP '[123] ton' ; select * from message_station_info WHERE type REGEXP '[1|2|3] ton' ; #匹配范围[0-9]、[a-z] select * from message_station_info WHERE type REGEXP '[0-2] ton' ; #匹配特殊字符\_;\.;\|;\[];\() select * from message_station_info WHERE type REGEXP '\.' ; select * from message_station_info WHERE type REGEXP '\.[0-9]{3} ton?' ;
执行结果如下:
7. 创建计算字段
从数据库中检索出转换、计算或格式化过的数据。
#将字段type、title拼接成一个字段进行显示,去掉字段两边的空格 select CONCAT(TRIM(type),' (',TRIM(title),')') AS type_title from message_station_info WHERE title='test'; #+、-、*、/ 等MYSQL算术操作符 select on_del*status as del_status from message_station_info WHERE title='test';
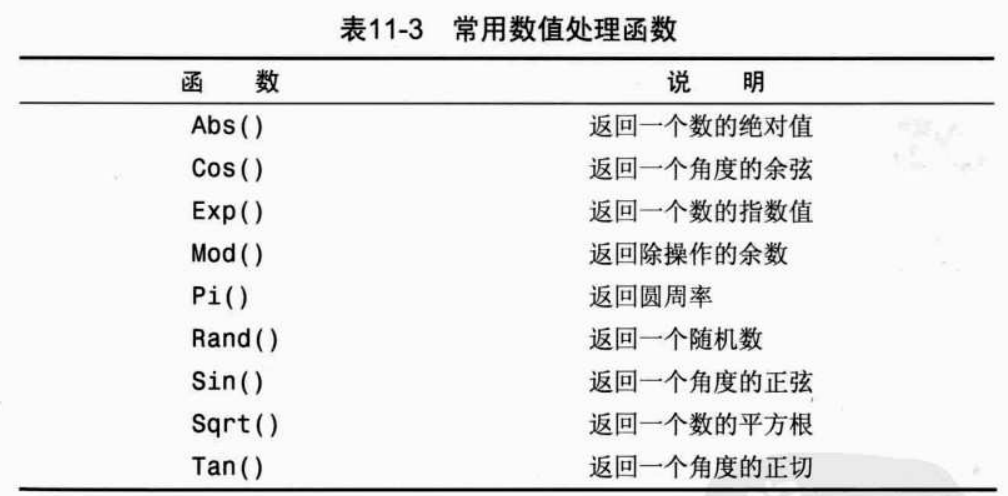
8. 数据处理函数
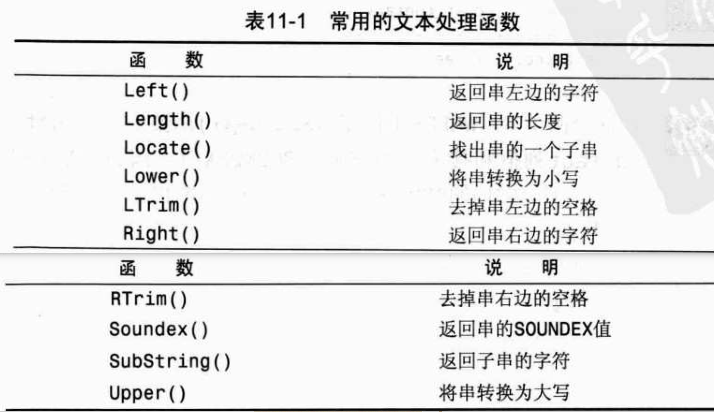

文本处理函数:用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数。
日期和时间处理函数:用于处理日期和时间值并从这些值中提取特定成本(例如,返回两个日期之差,检查日期有效性等)的日期和时间函数。
数值处理函数:用于在数值数据上进行算术操作的数值函数。
#文本处理函数,upper()函数,列type字段全部转换为大写 select UPPER(type) from message_station_info; #文本处理函数,left()函数,列type长度左边开始3个字符 select LEFT(type,3) from message_station_info; #日期和时间处理函数,检索创建时间为2020-5-13到2020-5-14的数据 select * from message_station_info where DATE(create_time)='2020-5-14'; select * from message_station_info where DATE(create_time) BETWEEN '2020-5-13' and '2020-5-14'; select * from message_station_info where Year(create_time)='2020' AND MONTH(create_time)='6';
9.汇总数据[聚集函数]
聚集函数:运行在行组上,计算和返回单个值的函数。
#AVG()函数,求平均值,用来返回所有列的平均值,也可以用来返回特定列或行的平均值.AVG()函数忽略列值为NULL的行。 select AVG(define_id) as avg_id from message_station_info; #COUNT()函数,计数,可利用COUNT()确定表中行的数目或符合特定条件的行的数目。 #COUNT(*)不管是空值(NULL)还是非空值;COUNT(id)对特定列中具有值的行进行计数,忽略NULL值。 select COUNT(*) as num_id from message_station_info; select COUNT(id) as num_id from message_station_info; #MAX()函数,返回指定列中的最大值。忽略列值为NULL的行。 select MAX(id) as max_id from message_station_info; #MIN()函数,返回指定列中的最小值。忽略列值为NULL的行。 select MIN(id) as min_id from message_station_info; #SUM()函数,用来返回指定列值的和(总计)。 select SUM(id*num) as sum_id from message_station_info; #DISTINCT()函数,用来返回指定列值的和(总计)。 select AVG(DISTINCT prod_price) as avg_price from products where id=1003;
10. 分组数据

#GROUP BY子句和HAVING 子句,WITH ROLLUP可以得到每个分组以及每个分组汇总级别的值 #WHERE过滤指定的是行;HAVING过滤指定的是分组 select type,id,title,COUNT(*) as num from message_station_info group by type HAVING COUNT(*) >='11';
11 使用子查询、组合查询、全文本搜索
查询任何SQL语句都是查询,SQL还允许创建子查询(subquery),即嵌套在其他查询中的查询,子查询总是从内向外处理。
列必须匹配,在where子句中使用子查询,应该保证select语句具有where子句中相同数目的列。
#MYSQL执行3条select语句,从最里边的子查询返回订单号列表,用于其外面的子查询的where子句,外面的子查询返回客户ID列表,用于最外层查询的where子句,最外层查询确实返回所需的数据 #利用子查询进行过滤 SELECT cust_name,cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders where order_num in (SELECT order_num FROM orderitems where prod_id='TNT2')); #作为计算字段使用子查询 SELECT cust_name,cust_state, (SELECT COUNT(*) FROM orders where orders.cust_id = customers.cust_id) AS orders FROM customers ORDER BY cust_name;
组合查询:Mysql也允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回,这些组合查询通过称为并(union)或复合查询(compound query)。使用组合查询的情况:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据;
#UNION组合查询[UNION默认取消重复的行,全匹配需要UNION ALL] select id,type,on_del from app_info WHERE on_del='1'; UNION select id,type,on_del from app_info WHERE id < '20'; #UNION全匹配需要加个UNION ALL select id,type,on_del from app_info WHERE on_del='1'; UNION ALL select id,type,on_del from app_info WHERE id < '20'; #UNION与where可以互相调换 select id,type,on_del from app_info WHERE on_del='1' or id < '20'; #UNION排序 select id,type,on_del from app_info WHERE on_del='1'; UNION select id,type,on_del from app_info WHERE id < '20'; ORDER BY id;
UNION规则:
- 必须由两条及两条以上的SELECT语句组成,语句之间用关键字UNION分隔。
- UNION中每个查询必须包含相同的列、表达式、聚集函数
- 列数据类型必须兼容:类型不必完全相同,但是DBMS可以隐含地转换的类型。
全文本搜索:并非所有的引擎都支持全文本搜索,MyISAM支持,InnoDB不支持,我们平时主要是用的InnoDB.
全文本搜索前提条件:必须索引(FULLTEXT)被搜索的列,索引后可与Match()和Against()一起使用。
12 联结表[join]、创建高级联结
联结:数据检索查询的执行中联结(join)表。联结是一种机制,用来在一条SELECT语句中关联表。
外键:为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。
可伸缩性:能够适应不断增加的工作量而不失败。
内部联结[等值联结]:基于两个表之间的相等测试。
#内部联结[等值联结]:基于两个表之间的相等测试。 select * from app_station_cls INNER JOIN app_info on app_station_cls.from_id = app_info.id; #联结多个表: select b.* from sys_user as a,app_info as b,sys_user_app_relation as c where c.app_id = b.id and c.user_id = a.id and a.account='upm_test';
表别名好处:缩短SQL语句;允许在单条select语句中多次使用相同的表。表别名的用处:可用与where子句、select列表、order by子句、语句的其他部分。
#自联结 select A1.id,A1.type from app_info as A1,app_info as A2 WHERE A1.id=A2.id and A2.type='1' #自然联结:排除多次出现,使每个列只返回一次。内部联结:返回所有数据。 select A.*,B.id from app_station_cls AS A,app_info AS B WHERE A.from_id = B.id; #联结包含了那些在相关表中没有关联行的行。这种类型的联结称为外部联结:左联结、右联结。[LEFT|RIGHT OUTER JOIN]