1.什么是序列化&反序列化?
序列化:将字典、列表、类的实例对象等内容转换成一个字符串的过程。
反序列化:将一个字符串转换成字典、列表、类的实例对象等内容的过程

PS:Python中常见的数据结构可以统称为容器。序列(如列表和元组)、映射(如字典)以及集合(set)是三类主要的容器。
场景一:我们在python中将一个功能给另外一段程序使用,怎么给?
方法一:功能存到文件,然后另一个python程序再从文件里读出来。
场景二:现在反过来怎么把读出来的文件字符串转换成字典?
方法二:eval()函数:将字符串str当成有效的表达式求值并返回计算结果,但存在风险,将str转换成python中的数据结构,推荐使用反序列化。
序列化就是从dic变成str(dic)的过程,反序列化就是从str(dic)变成dic的过程。
2.为什们要使用序列化?
序列化的目的:
1.以某种存储形式使自定义对象持久化(比如从内存存到硬盘)
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
序列化的2个模块:
json:用于字符串(str)和python数据类型间(比如字典、列表)进行转换
pickle:用于python特有的类型和python的数据类型间转换
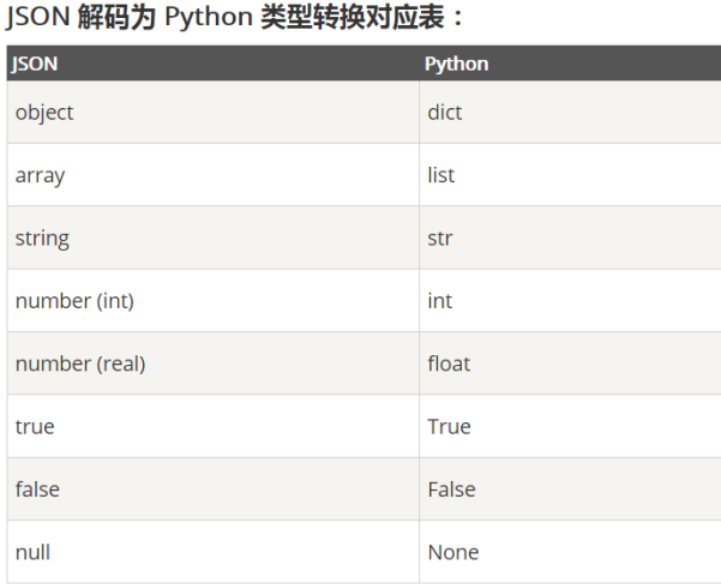
3.json
Json是一种轻量级的数据交换格式,基于ECMAScript的一个子集。Python3中可以使用json模块来对json数据进行编解码.
python本质:字符串,字符串中的值用双引号,包含了2个函数:
python对象->json:json.dumps(python对象)
json->python对象:json.loads(json字符串)
json.dumps():对数据进行编码,就是将mysql里的数据字符串或二进制的形式存储到硬盘。
dumps:输出到终端的操作方法,也就是把一个类型变量转换成str
dump:文件操作的方法,具体的操作json.dump(dict,open('test','w'))
json.loads():对数据进行解码,将抽象的数据内容(python对象)转换成字符串。
json.load和json.loads是反序列化输出的一个结果,dump和dumps是序列化输出终端或文件中去.
python对象(基本的数据类型):int、float、str、list、tuple、dict
需求:序列化,将字典info转换成字符串,存到test1.txt文件中。

ex1:用dumps()函数序列化,通过f.write()写入同级目录test1.txt文件。
import json
info={
'name':'wendy',
'age':22
}
f=open("test1.txt",'w')
#json.dumps(info)把一个字典info转换成字符串,从内存存到硬盘的过程叫序列化
#序列化dumps函数不可以序列化,只能处理简单的跨平台数据交互
f.write(json.dumps(info))
f.close()
ex2:用dump()函数序列化,直接json.dump()写入test1.txt文件。
import json
info={
'name':'wendy',
'age':22
}
f=open("test1.txt",'w')
#等于f.write(json.dumps(info))
json.dump(info,f)
f.close()
需求:用loads()函数反序列化,将字符串转换成python对象
#方式一:将字符串转换成python对象 import json json_str1="""{"name": "wendy", "age": 22}""" json_str3 = """12""" name1=json.loads(json_str1) #将字符串转换成字典 name2=json.loads(json_str3) #将数字转换成数字 print(type(name1),type(name2)) #打印类型 print(name1,name2) #显示结果如下: <class 'dict'> <class 'int'> {'name': 'wendy', 'age': 22} 12 #方式二:从同级目录test1.txt中取值,将字符串转换成python对象 #test1.txt中的值:{"name": "wendy", "age": 22} import json f=open("test1.txt",'r') data =json.loads(f.read())#等于json.load(f) print(data["name"]) #显示结果如下: wendy
4.pickle
pickle的load、loads和dump、dumps的使用操作,先来说下,pickle和json的差异:
4.1 pickle和json都可以实现序列化和反序列化的操作
4.2 在写入文件的时候,pickle是以加密的方式写入的,在打开文件的时候用'rb'模式,用‘wb’模式写入(二进制的形式)
4.3 pickle可以对类创建的对象进行反序列化输入到文件中
pickle模块的4个功能:dump(序列化,存)、dumps、loads(反序列化,读)、load
import pickle
class ABC:
a=10
def __init__(self,m,n):
self.m=m
self.n=n
abc=ABC(1,2)
res=pickle.dumps(abc) #pickle可序列化任意类型,比如:序列化类实例
back_res=pickle.loads(res)
print(res)
print(back_res)
print(back_res.a)
#结果显示
b'x80x03c__main__
ABC
qx00)x81qx01}qx02(Xx01x00x00x00mqx03Kx01Xx01x00x00x00nqx04Kx02ub.'
<__main__.ABC object at 0x000001D7A0B31048>
10