在网络环境方面,作为分布式系统,Hadoop基于TCP/IP进行节点间的通信和传输。
在数据传输方面,广泛应用HTTP实现。
在监控、通知方面,Hadoop等分布式大数据软件则广泛使用异步消息队列等机制。
1. hadoop的概念及其发展历程
Hadoop是Apache开源组织的一个分布式计算开源框架,用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。
Hadoop框架中最核心设计:HDFS和MapReduce,HDFS实现存储,MapReduce实现原理分析处理。数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Hadoop的集群处理后得到结果,它是一个高性能处理海量数据集的工具。
Hadoop干什么:最初的应用场景是搜索引擎的底层支撑技术,适合大数据的分布式存储与计算平台。
Hadoop核心组件:分布式文件系统HDFS、分布式处理框架MapReduce、分布式资源管理框架Yarn。
Hadoop的架构:从图中可看出,HBase、Spark、MapReduce、Yarn等组件是并行关系。

- HDFS文件系统:存储基础,负责对大数据文件和存储集群进行管理。HDFS不能实现对数据的表格化管理和快速检索(随机读取)。
- HBase:在HDFS基础上,将数据组织为面向列的数据表,并支持按照行键进行快速检索等功能,本身不对数据进行分布式处理。
- Yarn:负责对集群中的内存、CPU等资源进行管理,同时负责对分布式任务进行资源分配和管理。
- MapReduce:通过YARN在分布式集群中申请资源、提交任务,并按照自定义方式对数据进行处理。
- Spark和Tez:MapReduce的升级和替代产品,支持HDFS和HBase作为数据源和输出,并通过Yarn向分布式集群提交分布式处理任务。
- Hive:实现对分布式处理架构的简化应用。Hive映射HDFS形成二维数据表,并且将SQL语句转化为MapReduce过程。
- sqoop和flume:数据交互工具,前者基于MapReduce构建,实现关系型数据库和HDFS、HBase之间的分布式数据互转;后者可以实现将日志数据采集到大数据平台。
- Oozie和hue:实现数据处理过程的工作流构建和可视化操作。
- Zookeeper:实现各个服务集群点的节点监控、高可用性管理和配置同步等功能。
2. HDFS和MapReduce的体系结构
HDFS:hadoop distributed file system,hadooop分布式文件系统,它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集的应用程序。

HDFS体系结构:
主从结构:主节点只有一个:namenode;从节点,有多个,datanodes。
Namenode负责:接收用户操作请求;维护文件系统的目录机构;管理文件与block之间的关系,block与datanode之间关系。
Datanode负责:存储文件;文件被分成block存储在磁盘上;为保证数据安全,文件会有多个副本。
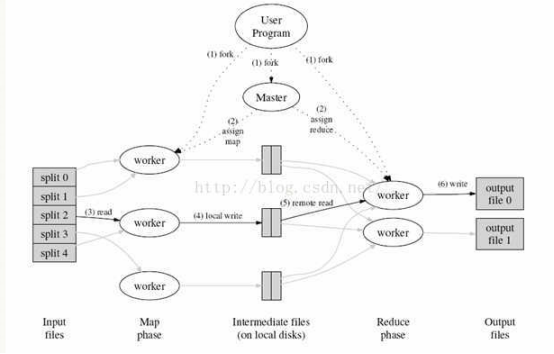
MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce将分为两个部分:Map(映射)和Reduce(归约)。
当你向mapreduce框架提交一个计算作业,它会首先把计算作业分成若干个map任务,然后分配到不同的节点上去执行,每一个map任务处理输入数据中的一部分,当map任务完成后,它会生成一些中间文件,这些中间文件将会作为reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个map的数据汇总到一起并输出。
MapReduce的体系结构:
主从结构:主节点,只有一个:JobTracker;从节点,有很多个:Task Trackers
JobTracker负责:接收客户提交的计算任务;把计算任务分给Task Trackers执行;监控Task Tracker的执行情况;
Task Trackers负责:执行JobTracker分配的计算任务。
3.Hadoop的特点和集群特点
Hadoop集群的物理分布:

单节点物理结构:

Hadoop的特点:
1、扩容能力:能可靠地存储和处理千兆字节数据
2、成本低:可以通过普通机器组成的服务器群来分发以及处理数据。
3、高效率:通过分发数据,hadoop可以在数据所在的节点上并行地处理它们,这使得处理非常的快速。
4、可靠性:hadoop能自动维护数据的多份副本,并且在任务失败后能自动地重新部署计算任务。