单标签 HTML模板的解析
因为 HTML 解析的过程相对麻烦和复杂,因此为了把这个过程讲清楚,我这里先从下面这段最简单的 HTML 标签开始入手。我们专注一个点,需要做的似乎就是封装一个解析函数来完成转换,把字符串模板(template)作为函数的输入,把Tree 结构对象作为函数的输出即可。
输入 字符串模板(template)
<!-- 举例: -->
<div id="app"></div>
输出 Tree 结构对象
{
tag: "div",
attrs:[{name:"id",value:"app"}],
}
观察上面的输入和输出,我们需要逐字的扫描HTML字符串模板,提取里面的标签名称作为最终对象的 Tag 属性值,提取里面的属性节点保存到 attrs 属性中,因为标签身上可能有多个属性节点,所以 attrs 使用对象数组结构。
在扫描<div id="app"></div>字符串的时候,我们需区分开始标签、属性节点、闭合标签等部分,又因为标签的类型可以有很多种(div、span等),而属性节点的 key 和 value我们也无法限定和预估,因此在具体操作的时候似乎还需要用到 正则表达式来进行匹配,下面给出需要用到的正则表达式,并试着给出解析上述 HTML 模板字符串的 JavaScript 实现代码。
/* 形如:abc-123 */
const nc_name = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`;
/* 形如:<aaa:bbb> */
const q_nameCapture = `((?:${nc_name}\\:)?${nc_name})`;
/* 形如:<div 匹配开始标签的左半部分 */
const startTagOpen = new RegExp(`^<${q_nameCapture}`);
/* 匹配开始标签的右半部分(>) 形如`>`或者` >`前面允许存在 N(N>=0)个空格 */
const startTagClose = /^\s*(\/?)>/;
/* 匹配属性节点:形如 id="app" 或者 id='app' 或者 id=app 等形式的字符串 */
const att =/^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<div>`]+)))?/
let template = `<div id="app"></div>`;
function parser_html(html) {
/* 在字符串中搜索<字符并获取索引 */
let textStart = html.indexOf('<');
/* 标签的开头 */
if (textStart == 0) {
/* 匹配标签的开头 */
let start = html.match(startTagOpen);
/* start的结果为:["<div","div",...] */
if (start) {
const tagInfo = {
tag: start[1],
attrs: []
}
/* 删除已经匹配过的这部分标签 html->' id="app"></div>'*/
html = html.slice(start[0].length)
/* 匹配属性节点部分 */
/* 考虑到标签可能存在多个属性节点,因此这里使用循环 */
let attr, end;
/* 换言之:(如果 end 有值那么循环结束),即当匹配到关闭标签的时候结束循环 */
while (!(end = html.match(startTagClose)) && (attr = html.match(att))) {
tagInfo.attrs.push({
name: attr[1],
value: attr[3] || attr[4] || attr[5]
})
html = html.slice(attr[0].length)
}
/* html-> ' ></div>' */
if (end) {
/* 此处可能是' >'因此第一个参数不能直接写0 */
html = html.slice(end[0].length);
/* html-> '</div>' */
/* 此处,关闭标签并不影响整体结果,因此暂不处理 */
return tagInfo;
}
}
}
}
let tree = parser_html(template);
console.log(tree);
/*
打印结果:
{ tag: 'div',
attrs: [ { name: 'id', value: 'app' } ] }
*/
console.log(parser_html(`<span id="app" title="标题"></span>`));
/*
打印结果:
{ tag: 'span',
attrs:
[ { name: 'id', value: 'app' }, { name: 'title', value: '标题' } ] }
*/
在上面的代码中,多个地方都用到了字符串的match方法,该方法接收一个正则表达式作为参数,用于进行正则匹配,并返回匹配的结果。
这里以属性匹配为例,当我们对字符串' id="app"></div>'应用正则匹配att后,得到的结果是一个数组,而如果匹配不成功,那么得到的结果为 null。

复杂标签 HTML模板的解析
上文中处理的HTML 字符串模板比较简单,是单标签的(只有一个标签),如果我们要处理的标签结构比较复杂,比如存在嵌套关系(既标签中又有一个或多个子标签,而子标签也有自己的属性节点、内容甚至是子节点)和文本内容等。
这里简单给出HTML 字符串模板编译的示例代码,基本上解决了标签嵌套的问题,能够最终得到一棵描述 标签结构的 "Tree"。
/* 形如:abc-123 */
const nc_name = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`;
/* 形如:<aaa:bbb> */
const q_nameCapture = `((?:${nc_name}\\:)?${nc_name})`;
/* 形如:<div 匹配开始标签的左半部分 */
const startTagOpen = new RegExp(`^<${q_nameCapture}`);
/* 匹配开始标签的右半部分(>) 形如`>`或者` >`前面允许存在 N(N>=0)个空格 */
const startTagClose = /^\s*(\/?)>/;
/* 匹配闭合标签:形如 </div> */
const endTag = new RegExp(`^<\\/${q_nameCapture}[^>]*>`);
/* 匹配属性节点:形如 id="app" 或者 id='app' 或者 id=app 等形式的字符串 */
const att = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<div>`]+)))?/
// const template = `<div><span class="span-class">Hi 夏!</span></div>`;
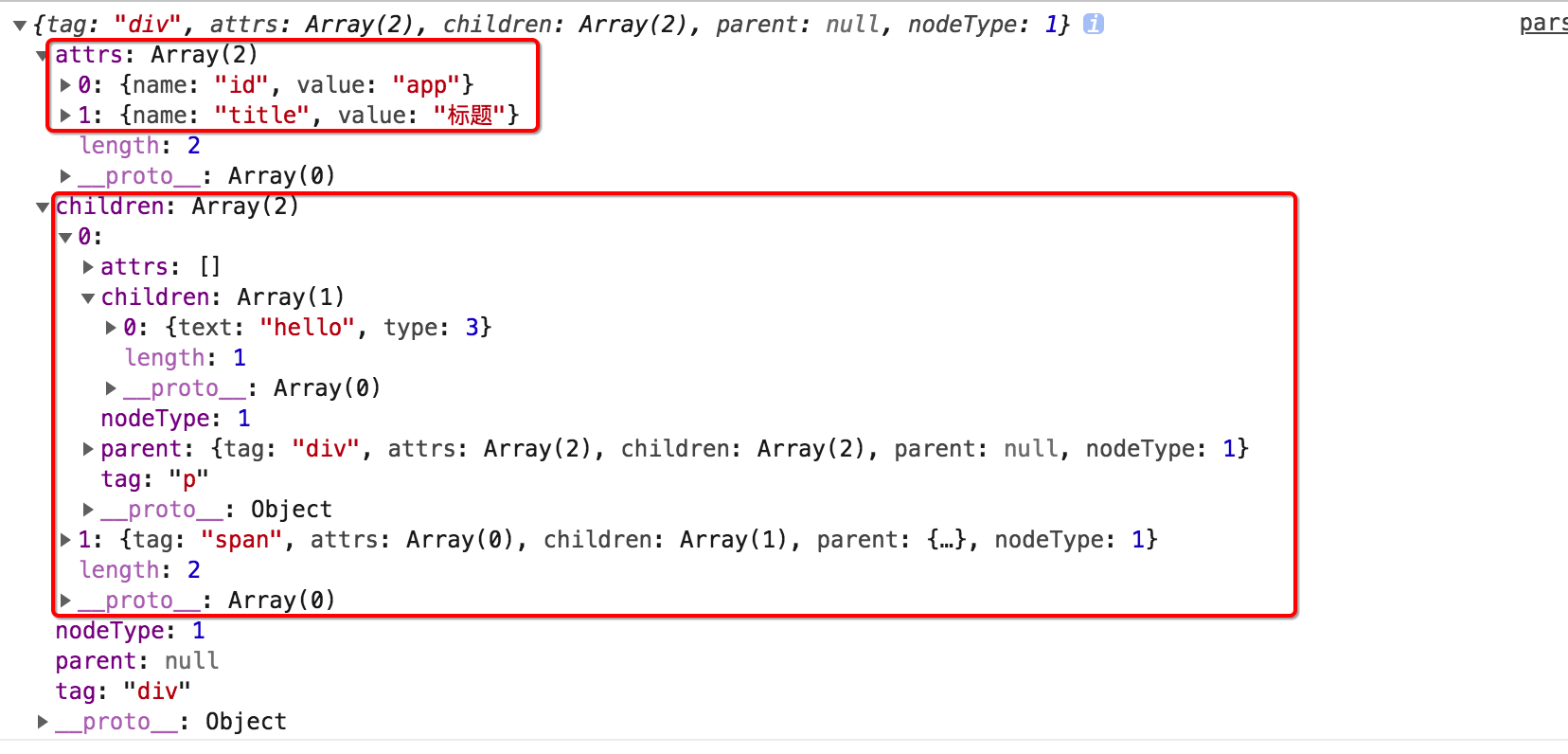
const template = `<div id="app" title="标题"><p>hello</p><span>vito</span></div>`
/* 标记节点类型(文本节点) */
let NODE_TYPE_TEXT = 3;
/* 标记节点类型(元素节点) */
let NODE_TYPE_ELEMENT = 1;
let stack = []; /* 数组模拟栈结构 */
let root = null;
let currentParent;
function compiler(html) {
/* 推进函数:每处理完一部分模板就向前推进删除一段 */
function advance(n) {
html = html.substring(n);
}
/* 解析开始标签部分:主要提取标签名和属性节点 */
function parser_start_html() {
/* 00-正则匹配 <div id="app" title="标题">模板结构*/
let start = html.match(startTagOpen);
if (start) {
/* 01-提取标签名称 形如 div */
const tagInfo = {
tag: start[1],
attrs: []
};
/* 删除<div部分 */
advance(start[0].length);
/* 02-提取属性节点部分 形如:id="app" title="标题"*/
let attr, end;
while (!(end = html.match(startTagClose)) && (attr = html.match(att))) {
tagInfo.attrs.push({
name: attr[1],
value: attr[3] || attr[4] || attr[5]
});
advance(attr[0].length);
}
/* 03-处理开始标签 形如 >*/
if (end) {
advance(end[0].length);
return tagInfo;
}
}
}
while (html) {
let textTag = html.indexOf('<');
/* 如果以<开头 */
if (textTag == 0) {
/* (1) 可能是开始标签 形如:<div id="app"> */
let startTagMatch = parser_start_html();
if (startTagMatch) {
start(startTagMatch.tag, startTagMatch.attrs);
continue;
}
/* (2) 可能是结束标签 形如:</div>*/
let endTagMatch = html.match(endTag);
if (endTagMatch) {
advance(endTagMatch[0].length);
end(endTagMatch[1]);
continue;
}
}
/* 文本内容的处理 */
let text;
if (textTag >= 0) {
text = html.substring(0, textTag);
}
if (text) {
advance(text.length);
chars(text);
}
}
return root;
}
/* 文本处理函数:<span> hello <span> => text的值为 " hello "*/
function chars(text) {
/* 1.先处理文本字符串中所有的空格,全部替换为空 */
text = text.replace(/\s/g, '');
/* 2.把数据组织成{text:"hello",type:3}的形式保存为当前父节点的子元素 */
if (text) {
currentParent.children.push({
text,
type: NODE_TYPE_TEXT
})
}
}
function start(tag, attrs) {
let element = createASTElement(tag, attrs);
if (!root) {
root = element;
}
currentParent = element;
stack.push(element);
}
function end(tagName) {
let element = stack.pop();
currentParent = stack[stack.length - 1];
if (currentParent) {
element.parent = currentParent;
currentParent.children.push(element);
}
}
function createASTElement(tag, attrs) {
return {
tag,
attrs,
children: [],
parent: null,
nodeType: NODE_TYPE_ELEMENT
}
}
console.log(compiler(template));
执行上述代码,我们可以得到下面的显示结果。