背景
在 SQL Server 2012 和 2014 中,初始化 SQL Server Always On 可用性组中的次要副本的唯一方法是使用备份、复制和还原。
在一个高可用组里面添加一个数据库需要很多手动任务和一些必要条件。需要完成的这些工作中,有一些是有些困难的,比如:
- 我们需要从主副本中备份数据库,并将这个备份分发到可用组的其他副本中。这是基于手动操作的,因为这需要你从主数据库备份还原数据库到次要副本。
- 有时候,我们不能通过网络防火墙在副本之间传送数据库备份文件。这种情况下,需要开放SMB协议端口,以便能在节点间传输备份文件。
- 通常,复制一个备份文件会占用更多空间,这是额外的需求,更多的磁盘空间。
- 特别是针对第三方备份的方案,会导致备份/还原链的中断。但是这又取决于数据库的备份策略。
- 分发和还原数据库是耗时并且不透明的过程。
作为一个兼职DBA,我不喜欢处理这些问题。当我创建数据库在主节点上时,我想要数据库被自动创建在所有副本上,幸运的是SQLServer 2016以后这样的工作就容易多了。为了更好的帮助DBA们处理这些问题,微软引入了可用组的自动增长数据库。即SQL Server 2016 引入了用于初始化次要副本的新功能 - 我一般称之为数据库自增长(自动种子设定)
那么这个自动化如何实现的?
当你打算创建一个数据库在主副本上,并且加入数据库到AG里面时,自动填充就会在数据库镜像端间进行通信,并且复制数据库到次要副本中。假设有一个可用组,由N个副本组成,replicas - Replica1, Replica2, ... ReplicaN。当前你的主副本是Replica2 ,然后你创建一个新的数据库在主副本上。下一步就是要尽快把数据库加入到可用组的其他副本上。这个解决方案就如下图的流程所示:
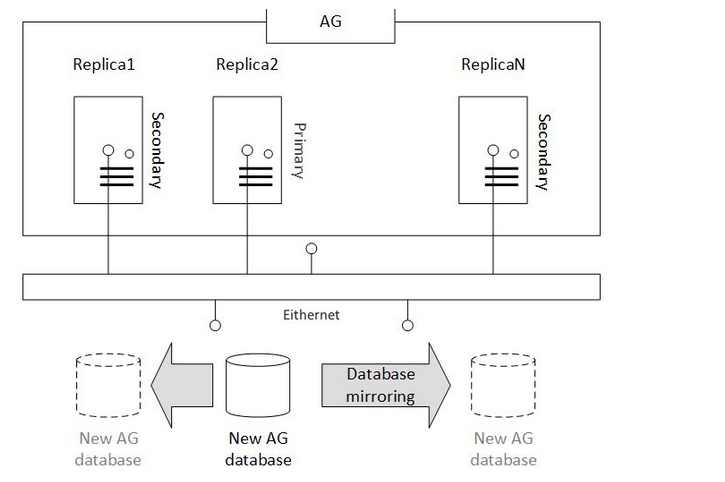
数据库自动种子设定(自增长),没有特殊的必要条件和限制,只是需要数据和日志文件路径在可用组中是完全一致的。这个可用组配置自增长,数据库在可用组中一定是完整还原模式,需要有一个完成备份以及事务日志备份。如果在可用组中用手动同步加入的数据库也需要上述一样的条件。
启动自动种子设定功能
在每一个需要自增长数据库的副本上,需要允许可用组创建数据库。下面的脚本用来允许AG创建数据库,但是确保你可以连接到master数据库并且能够对所有可用组中的副本执行这个脚本:
ALTER AVAILABILITY GROUP [{your_AG_name}]
GRANT CREATE ANY DATABASE;
GO
可用组必须被切换为自动增长模式。该模式可以通过在每个副本中执行下面额T-SQL代码来实现(或者每个副本中启动自增模式):
ALTER AVAILABILITY GROUP [{your_AG_name}]
MODIFY REPLICA ON '{your_replica_name}'
WITH (SEEDING_MODE = AUTOMATIC);
GO
另外,对于Always On 的可用组来说,自增期间能够使用跟踪标记trace flag 9567压缩数据流,从而大大减少传输时间。相关内容可以再找个连接看到: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql
添加一个带有自增长属性的数据库
打开SSMS并且连接可用组主节点。导航到AlwaysOn 高可用(AlwaysOn High Availability)文件,打开“Availability Groups”,然后找到打算添加数据库的可用组。在打开"Availability Databases" 文件夹。右击"Availability Databases",右键菜单"Add databases..", 这个菜单选项将会激活配置向导如下:
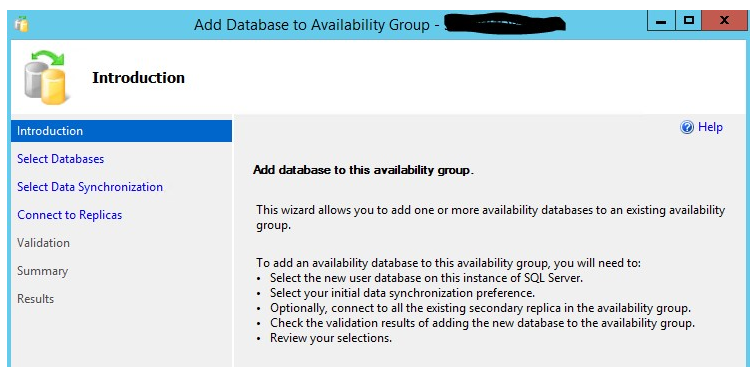
选择打算加入到可用组的数据库:
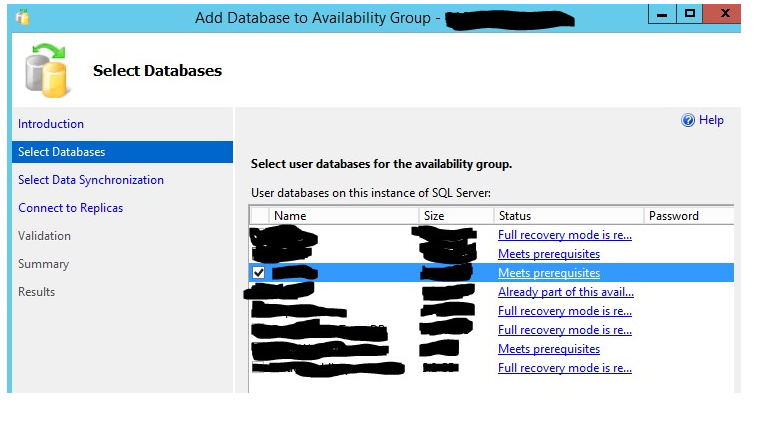
注意,这个数据库一定满足一下必要条件。选择选项“Skip initial data synchronization”:
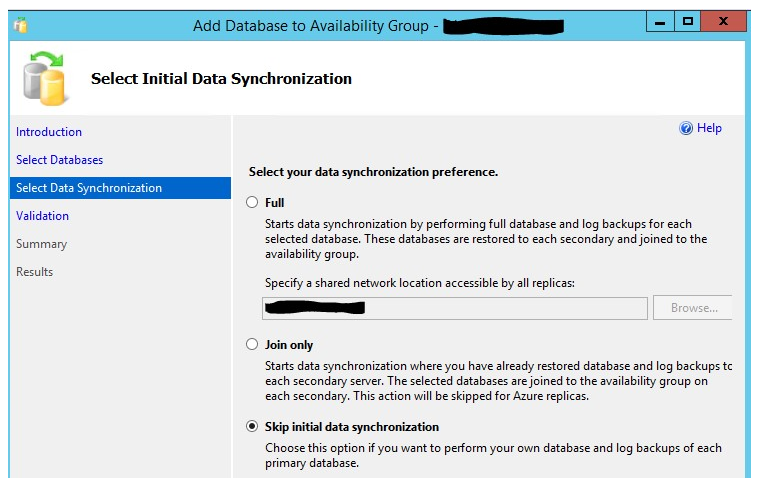
在次要节点,你会看到数据库已经被还原的信息:
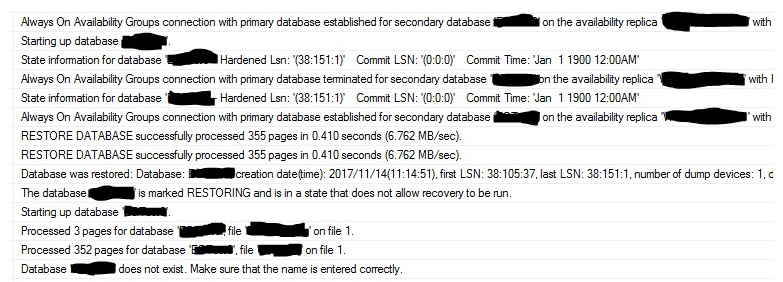
因此,你也可以在msdb.dbo.restorehistory 表中看到每个数据库的增加信息。在主服务器,可以在表msdb.dbo.backupmediafamily 中看到每个数据库信息,数据库可以shiyo8ng下面的T-SQL语句实现:
ALTER AVAILABILITY GROUP {your_AG_name} ADD DATABASE {your_database_name};
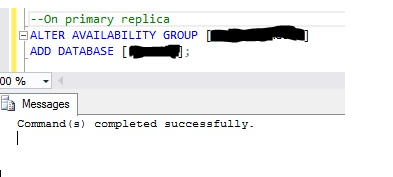
这个脚本必须在可用组的每个数据库上执行。
优缺点
我通常使用自动数据库填充为可用组并且发现它很有价值。例如,微软SharePoint 支持组有权去创建新的数据库在主副本上,但是他们不能直接把数据库加入到可用组中,因为这样做影响了数据库的高可用。当我们使用自动数据填充在指定的可用组上时,我们可以自动添加新的Sharepoint 数据库在可用组上,使用一个将所有最近创建的Sharepoint 数据库添加到可用组上的脚本,使用2016这个特性不在需要使用手动操作。
综上所述,使用自动填充的优势有如下几点:
- 操作过程简单.
- 节省磁盘空间.
- 节省备份还原事件,因为SQLServer复制数据库使用网络.
- 使用追踪标记9567,能够大大减少同步时间。
在可用组中使用自动增长的缺点:
- 在同步过程中需要巨大的网络流。
- 处理需要一些手动处理步骤
引用本文请注明原文地址:http://www.cnblogs.com/wenBlog/p/8341245.html