In order to train our model, we need to define what it means for the model to be good. Well, actually, in machine learning we typically define what it means for a model to be bad. We call this the cost, or the loss, and it represents how far off our model is from our desired outcome. We try to minimize that error, and the smaller the error margin, the better our model is.
One very common, very nice function to determine the loss of a model is called "cross-entropy." Cross-entropy arises from thinking about information compressing codes in information theory but it winds up being an important idea in lots of areas, from gambling to machine learning. It's defined as:
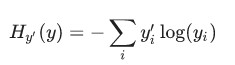
Where y is our predicted probability distribution, and y′ is the true distribution (the one-hot vector with the digit labels). In some rough sense, the cross-entropy is measuring how inefficient our predictions are for describing the truth. Going into more detail about cross-entropy is beyond the scope of this tutorial, but it's well worthunderstanding.
To implement cross-entropy we need to first add a new placeholder to input the correct answers:
y_ = tf.placeholder(tf.float32, [None, 10])
Then we can implement the cross-entropy function, 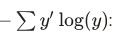
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
First, tf.log computes the logarithm of each element of y. Next, we multiply each element of y_ with the corresponding element of tf.log(y). Then tf.reduce_sum adds the elements in the second dimension of y, due to the reduction_indices=[1] parameter. Finally, tf.reduce_mean computes the mean over all the examples in the batch.
Note that in the source code, we don't use this formulation, because it is numerically unstable. Instead, we apply tf.nn.softmax_cross_entropy_with_logits on the unnormalized logits (e.g., we call softmax_cross_entropy_with_logits on tf.matmul(x, W) + b), because this more numerically stable function internally computes the softmax activation. In your code, consider usingtf.nn.softmax_cross_entropy_with_logits instead.
大意是:如果使用 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
来计算交叉熵,则需要使用 tf.clip_by_value 来使某些求 log 的值,因为 log 会产生 none (如 log-3 ), 用它来限定不出现none,具体使用方式如下:
cross_entropy = -tf.reduce_sum(y_*tf.log(tf.clip_by_value(y_conv, 1e-10, 1.0)))但后来有人用了一个更好的方法来避免none:
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv + 1e-10))具体参见 http://stackoverflow.com/questions/33712178/tensorflow-nan-bug 的讨论。
而如果直接用 tf.nn.softmax_cross_entropy_with_logits 则你再没有上面的后顾之忧了,它自动解决了上面的问题。