首先,thchs30有两种数据库,kaldi运行的数据库最好是 thchs30-openslr。
修改run.sh里面的语音库路径 thchs30=...
修改nj线程数 等于CPU的核心数
修改cmd.sh queue.pl 改为run.pl本地机器跑
运行出现错误:
lexicon.txt验证出错
里面binary file matches
这是grep的问题,grep -v -a '<s>' | grep -v -a '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
---------------------------------------------------------------------------------------------------------------------------
在线识别部分:
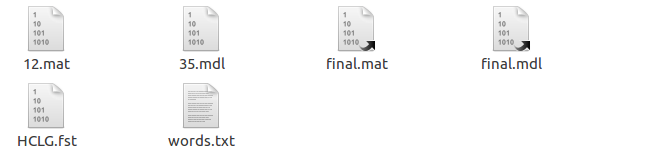
去egs下,打开voxforge,里面有个online_demo,直接考到thchs30下。在online_demo里面建2个文件夹online-data work,在online-data下建两个文件夹audio和models,audio下放你要回放的wav,models建个文件夹tri1,把s5下的exp下的tri1下的final.mdl和35.mdl(final.mdl是快捷方式)考过去。把s5下的exp下的tri1下的graph_word里面的words.txt,和HCLG.fst,考到models的tri1下。
类似处理,包括tri2b,tri3b,tri4b,不过后者需要添加转移矩阵,final.mat以及所指的mat文件。
如下所示,例如 tri2b文件夹下,
打开online_demo的run.sh
a)将下面这段注释掉:(这段是voxforge例子中下载现网的测试语料和识别模型的。我们测试语料自己准备,模型就是tri1了)
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Downloading test models and data ..."
wget -T 10 -t 3 $data_url;
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Download of $data_file has failed!"
exit 1
fi
fi
b) 然后再找到如下这句,将其路径改成tri1
ac_model_type=tri2b
if [ -s $ac_model/final.mat ]; then
trans_matrix=$ac_model/final.mat
echo "set matrix"
fi
online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000
--beam=12.0 --acoustic-scale=0.0769 --left-context=3 --right-context=3 $ac_model/final.mdl $ac_model/HCLG.fst
$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
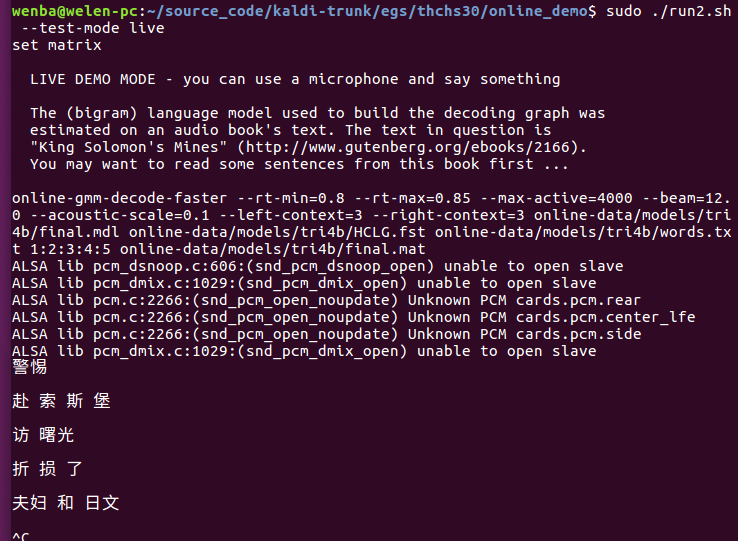
识别效果很差